正文
Bokeh
:
用于在现代网络浏览器上创建交互式图表,仪表盘和数据应用程序。它赋予用户以D3.js的风格生成优雅简洁的图形。此外,它具有超大型或流式数据集的高性能交互能力。
Blaze
:
将Numpy和Pandas的能力扩展到分布式和流式传输数据集。它可以用于从众多来源(包括Bcolz,MongoDB,SQLAlchemy,Apache Spark,PyTables等)访问数据。与Bokeh一起,Blaze可以作为在巨型数据块上创建有效可视化和仪表盘的强大的工具。
Scrapy
:
用于网络爬虫。它是获取特定模式数据的非常有用的框架。它从网站首页url开始,然后挖掘网站内的网页内容来收集信息。
SymPy
:
用于符号计算。它具有从基本算术符号到微积分,代数,离散数学和量子物理学的广泛能力。另一个有用的功能是将计算结果格式化为LaTeX代码。
Requests
:
用于web访问。它类似于标准python库urllib2,但是代码更容易。你会发现与urllib2的微妙差异,但是对于初学者来说,Requests可能更方便。
你可能需要的额外的库:
-
os
用于操作系统和文件操作
-
networkx
和
igraph
为基于图的数据操作
-
regular expressions
用于在文本中查找特定模式的数据
-
BeautifulSoup
用于网络爬虫。它不如Scrapy,因为它只是单个网页中提取信息。
既然我们熟悉Python基础知识和库,那么我们可以通过Python深入解决问题。做预测模型过程中,我们会使用到一些功能强大的库,也会遇到不同的数据结构。我们将带你进入三个关键阶段:
-
数据探索 – 详细了解我们的数据
-
数据清洗 – 清理数据,使其更适合统计建模
-
预测建模 – 运行实际算法并获得结果
使用pandas进行数据探索
为了进一步探索我们的数据,给你介绍另一个动物(好像Python还不够!)- Pandas

Pandas是Python中最有好用的数据分析库之一(我知道这些名字听起来很奇怪,先这样!)促使越来越多数据科学界人士使用Python。现在我们将使用pandas从Analytics Vidhya比赛中读取数据集,进行探索性分析,并构建我们的第一个基础分类算法来解决这个问题。
在数据加载之前,先了解Pandas中2个关键数据结构 – Series和DataFrames。
Series
及DataFrame介绍
Series可以理解为1维标签/索引数组。你可以通过这些标签访问series的各个元素。
Dataframe类似于Excel工作簿,列名称引用列,使用行号访问行。本质区别在于dataframes中列名称和行号称为列和行索引。
Series和DataFrames构成了Pandas在Python中的核心数据模型。数据集首先被读入Dataframes,然后各种操作(例如分组、聚合等)可以非常容易地应用于其列。
应用案例 – 贷款预测问题
以下是变量的描述:
|
变量
|
描述
|
|
Loan_ID
|
贷款ID
|
|
Gender
|
男/女
|
|
Married
|
已婚(Y/N)
|
|
Dependents
|
赡养人数
|
|
Education
|
教育程度(Graduate/Under Graduate)
|
|
Self_Employed
|
自雇人士(Y/N)
|
|
ApplicantIncome
|
申报收入
|
|
CoapplicantIncome
|
综合收入
|
|
LoanAmount
|
贷款金额
|
|
Loan_Amount_Term
|
贷款月数
|
|
Credit_History
|
信用记录
|
|
Property_Area
|
房产位置(Urban/Semi Urban/Rural)
|
|
Loan_Status
|
贷款批准状态(Y/N)
|
开始数据探索
首先,在terminal/ Windows命令提示符下键入以下命令,以Inline Pylab模式启动iPython界面:
ipython notebook --pylab=inline
这样在pylab环境中打开了iPython notebook,它已经导入了一些有用的库。此外,可以内联绘制数据,这使得它成为一个非常好的交互式数据分析环境。 你可以通过键入以下命令(并获得如下图所示的输出)来检查环境是否加载正确:
plot(arange(5))
我当前在Linux中工作,并将数据集存储在以下位置: /home/kunal/Downloads/Loan_Prediction/train.csv
导入库和数据集:
以下是我们将在本教程中使用的库:
numpy
matplotlib
pandas
请注意,由于Pylab环境,你不需要导入matplotlib和numpy。我仍然将它们保留在代码中,以便在不同的环境中使用代码。
导入库后,使用函数read_csv()读取数据集。代码如下:
import pandas as pd
import numpy as np
import matplotlib as plt
df = pd.read_csv("/home/kunal/Downloads/Loan_Prediction/train.csv") #使用Pandas读入数据集转换成dataframe
快速数据探索
读取数据集后,可以使用head()函数查看前几行
df.head(10)
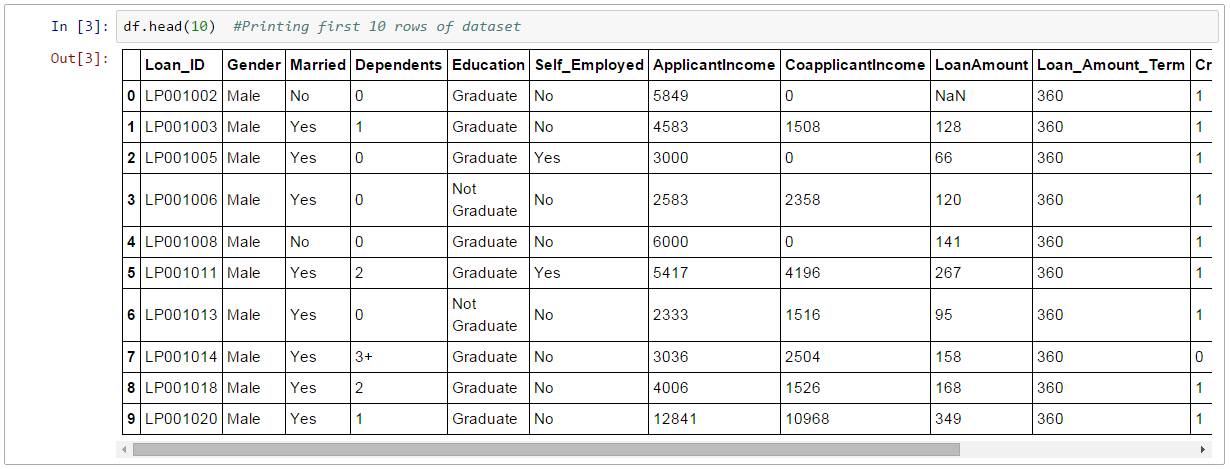
这样输出了10行,或者,也可以打印查看更多行数据集。
接下来,可以使用describe()函数来查看数值字段的摘要
df.describe()
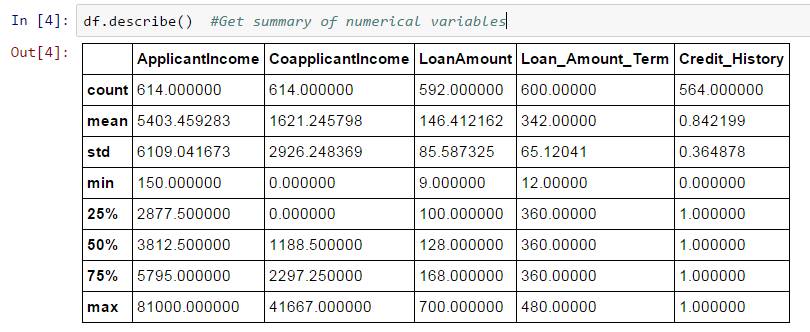
describe()函数将在其输出中提供计数、平均值、标准偏差(std)、最小值、四分位数和最大值。
这里有几个发现,你可以通过看看describe()函数的输出来绘制:
1.LoanAmount有(614 – 592)22个缺失值。
2.Loan_Amount_Term有(614 – 600)14个缺失值。
3.Credit_History有(614 – 564)50个缺失值。
4.我们也可以看到,约84%的申请人有信用记录,怎么样?Credit_History字段的平均值为0.84(记住,Credit_History对于具有信用记录的用户而言为1,否则为0)
5.申请人收入分布似乎符合预期。与CoapplicantIncome相同。
请注意,我们可以通过比较平均值与中位数来了解数据中可能的偏差。
对于非数值(例如Property_Area,Credit_History等),我们可以查看频率分布来了解它们是否有意义。频率表可以通过以下命令打印输出:
df['Property_Area'].value_counts()
同样,我们可以看看信用历史的独特价值。请注意,dfname [‘column_name’]是一种基本的索引方法来访问dataframe的特定列。它也可以是一个列名的列表。
分布分析
现在我们熟悉基本的数据特征,我们来研究各种变量的分布。从数字变量ApplicantIncome和LoanAmount开始。
首先使用以下命令绘制ApplicantIncome的直方图:
df['ApplicantIncome'].hist(bins=50)
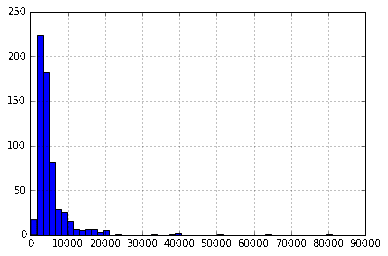
在这里我们观察到很少极端值。这也是为什么需要50个箱子来明确分配分配的原因。
接下来,我们来看一下箱线图来了解分布。箱线图可以通过以下方式绘制:
df.boxplot(column='ApplicantIncome')
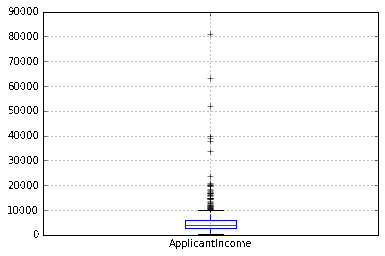
这证实了许多异常值/极端值的存在。这可归因于社会的收入差距。部分原因可能是由于我们研究了不同教育水平的人。通过教育变量将其分离开:
df.boxplot(column='ApplicantIncome', by = 'Education')
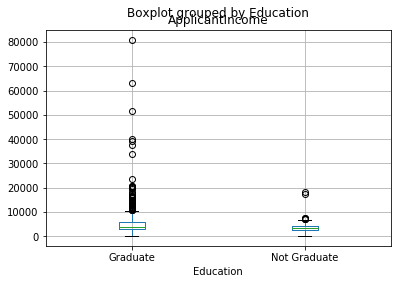
我们可以看到大学学历和非大学学历的平均收入之间没有实质性差异。但是,高学历中高收入人数更多,这似乎是离群值。
现在,我们来看看变量LoanAmount的直方图和boxplot,使用以下命令:
df['LoanAmount'].hist(bins=50)
df.boxplot(column='LoanAmount')
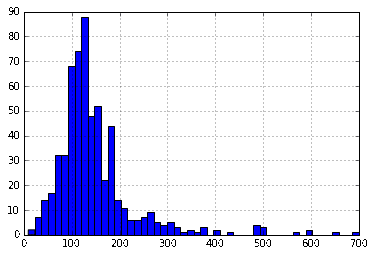
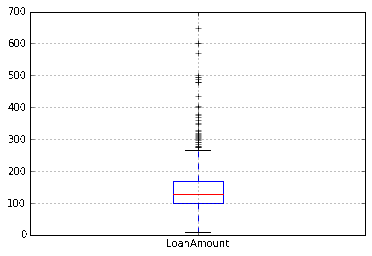
再次,有一些离群值。显然,ApplicantIncome和LoanAmount都需要一定量的数据清洗。 LoanAmount有缺失值和离群值,同时,ApplicantIncome有一些离群值,接下来我们将分几个部分,做更深入的了解。










