正文
我们简单举个实例来描述下 Hash 的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户 ID 为查找的 key,存储的 value 用户对象包含姓名,年龄,生日等信息,如果用普通的 key/value 结构来存储,主要有以下2种存储方式:
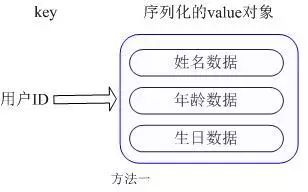
第一种方式将用户 ID 作为查找 key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
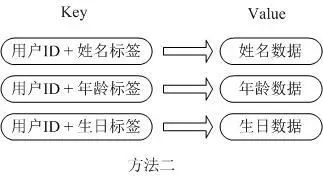
第二种方法是这个用户信息对象有多少成员就存成多少个 key-value 对儿,用用户 ID +对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户 ID 为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么 Redis 提供的 Hash 很好的解决了这个问题,Redis 的 Hash 实际是内部存储的 Value 为一个 HashMap,并提供了直接存取这个 Map 成员的接口,如下图:
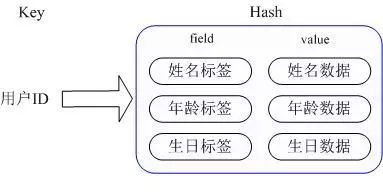
也就是说,Key 仍然是用户 ID,value 是一个 Map,这个 Map 的 key 是成员的属性名,value 是属性值,这样对数据的修改和存取都可以直接通过其内部 Map 的 Key(Redis 里称内部 Map 的 key 为 field),也就是通过 key(用户 ID) + field(属性标签)就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis 提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部 Map 的成员很多,那么涉及到遍历整个内部 Map 的操作,由于 Redis 单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
实现方式:
上面已经说到 Redis Hash 对应 Value 内部实际就是一个 HashMap,实际这里会有2种不同实现,这个 Hash 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,对应的 value redisObject 的 encoding 为 zipmap,当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 ht。
List
常用命令:
lpush,rpush,lpop,rpop,lrange等。
应用场景:
Redis list 的应用场景非常多,也是 Redis 最重要的数据结构之一,比如 twitter 的关注列表,粉丝列表等都可以用 Redis 的 list 结构来实现,比较好理解,这里不再重复。
实现方式:
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Set
常用命令:
sadd,spop,smembers,sunion 等。
应用场景:










