正文
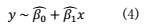
现在我们再收集一个样本量为m的新样本,包含以下的数据点:
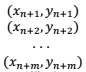
把上面这m个点中的自变量x都代入到模型(4)里,我们就可以得到该模型给出的各个数据点因变量的预测值:
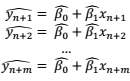
因此,要检查模型(4)对于这个新样本的预测能力如何,我们只需比较因变量的实际测量值
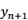 和模型预测值
和模型预测值
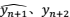 和
和
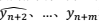 和
和
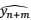 。
。
如果只需要比较
单个数据点
上的预测值和测量值,那样很好办,我们取个差值,再来个绝对值或者平方就行了。如果要把许
多个数据点
都综合起来考虑怎么办?如果你还记得上一集我们费了半天劲对R平方的推导,应该会想到,这其实和R平方的目的非常相像!R平方其实就是我们为了比较模型预测值和实际测量值差异而构造出来的一把「尺子」。唯一的区别,就在于计算R平方时,我们使用的是原来的、用于拟合回归模型的那些数据点(即上面例子中的
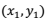 到
到
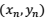 ),而在这里,我们要考虑的是一组新的、并没有用来拟合回归模型的数据点(
),而在这里,我们要考虑的是一组新的、并没有用来拟合回归模型的数据点(
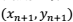 即上面的到
即上面的到
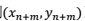 )。
)。
既然现在我们要考虑的是最开始的样本以外的新数据点,那么我们就把用原来的模型在新的数据点上算出来的R平方称为样本外R平方(out-of-sample R square)。就像经典的R平方一样,算出来越接近1,则说明预测值和实际测量值越相似,模型对新数据的预测能力也就越好。
说了这么多,我们终于可以对文章开头部分关于蓝精灵宝宝身高的三个模型来个终极对决啦!假设我们收集了新的一批蓝精灵宝宝身高、性别、父母平均身高和隔壁老王身高的数据,但是仍然使用在之前老样本上得到的回归模型来计算预测值,我们可以得到这三个模型的样本外R平方:

这时候,三个模型孰优孰劣,就和之前的结论不太一样了:包含父母平均身高和性别的模型(2)的样本外R平方最高,也就是说,它对于新样本的预测最准确。而有些无厘头的模型(3)、不够全面的模型(1)都成了它的手下败将。

过度拟合
你一定会问,为什么
R平方
和
样本外R平方
会给出不一样的结论呢?我们不妨把这三个模型想象成三个正要迎接考试的学生。抛开偶然因素不谈,谁的成绩会最好呢?当然是真本事最强的那一个了——我们前面已经讨论过,一个模型的真本事,就在于它能够解释新的样本和数据,因此,
样本外R平方
能够客观地反映模型的优劣。
那么,模型对样本的解释能力是从哪儿来的呢?毫无疑问,这是「学」来的。从哪儿学的?从一开始拟合模型的数据中。这个老的样本就好比是课本上的例题,而普通的R平方,就像是直接拿课本上的例题来当考试题。为什么这么说呢?在拟合模型时,各个模型本来就是要使自己的预测值和真实值尽量吻合(我们说过,极大似然估计的一个效果,是使得误差平方和最小)。在得到模型以后,再来算一次普通R平方,其实就相当于同样的题目让人做两遍嘛!
如果是同样的题目做两遍,为什么三个模型表现还是有差异(模型(1)的R平方最小,模型(3)的R平方最大)呢?这就体现出三位学生学习能力和方法的差异来了。我们的模型(1)呢,学例题的时候学得有点儿不够,把性别这个重要因素漏掉了,所以即便是再做一遍题目,还是不如学得更好的模型(2)。模型(1)同学的这个毛病,统计学上称为
「拟合不足」
(under-fitting)
。
而模型(3)呢,有点儿死读书,它有时爱用一招——背题。所以呢,碰上以前见过的题目,它总能做得更好,但是一旦遇到了没做过的新题型新背景,即使考的还是原来的知识点,都容易丢分。它的这个毛病呢,统计学上也有个名字,叫做
「过度拟合」
(
overfitting)
。
我们接着来刨根问底:为什么会发生过度拟合?简单来讲,我们收集的任何数据,都是两个成分的叠加:一、现实世界中某些有
普遍性
的规律
的效果,称为
「信号」(signal)
;二、收集数据过程中某些没有被测量的
随机因素
的影响,称为
「噪音」(noise)
。在拟合模型时,如果模型拟合的是信号(就好比课本例题中体现的某个知识点),这个模型就会有更好的推断和预测能力,但如果拟合的是噪音(就像某道例题中的特殊情景或者条件),那就没什么大用处了。
而麻烦的是,我们无法确切地知道,数据的差异性中哪些是信号,哪些是噪音(要是能知道还要统计学干吗?)。但是,如果我们往模型中加入越来越多的自变量,即便这些自变量对因变量本身
没有效应
,但由于
随机因素
,总会与因变量有些微小的相关性。这时,这些
噪音
就会被当成信号,拟合到模型中去,甚至获得有显著性的效应。在本文的例子里,根据常识我们就能知道性别和父母平均身高应该是有意义的因素,而隔壁老王显然就是闹着玩儿的。但在真实的科研课题里,变量间的关系错综复杂,就不可能这样简单地做主观判断的。
R平方不给力,有更好的标准吗?
读到这里,相信大家都已经明白,虽然R平方能在一定程度上指示模型的好坏(要是有个学生连同样的题目做第二遍都做不好,那你说这学生靠不靠谱呢?),但是绝不是一个完善的指标。模型优劣的金标准,应该是模型在面对新的样本时预测的准确性。因此,最理想的评判方式,便是像我们前面一样,在新的样本中比较不同模型的预测能力,称为「模型验证」(model validation)。事实上,近年来科学界广受重视的数据的「可重复性」(replicability,即在新的样本中得到与已有文献一致的现象和结论),也是一种广义上的验证。
可是,说起来简单,要真这么做,却不是那么容易。在绝大多数情况下,收集数据是件费时费力的事情,不是所有人都能够重新收集一批新的数据,来验证已有的模型。一种流行的办法是,把样本先留下一部分(如20%),用剩下的80%的数据拟合不同的模型,再用事先留下的20%来做验证和模型比较。
但这样做还有一个现实问题:我们很早以前就讲过,同样的一个研究,样本量越大,统计功效也就越大,得到可靠结论的可能性就越高。如果我收集了100个样本,却只能把80个用来建立模型,岂不是浪费了相当一部分统计功效?有没有可能既把手上的样本用完,又能用样本外的验证方法,选出真正最好的模型?
值得庆幸的是,勤劳勇敢的统计学家们完成了这个仿佛是无中生有的任务,发明了几个衡量统计模型在「样本外」的预测能力的标准。它们的名称和用法分别是:
1.
修正R平方
(
adjusted R square):数值越大,模型越好;
2.
赤池信息标准
(
Akaike Information Criterion,简称AIC, 因日本统计学家赤池弘次而得名):数值越小,模型越好;
3.
贝叶斯信息标准
(
Bayesian Information Criterion,简称BIC):数值越小,模型越好。
这几个标准的具体原理比较高深,我们就不具体介绍了。简单来说,它们都包含了类似于普通R平方那样
衡量模型和数据契合程度
的部分,然后再根据模型包含的自变量数量进行修正(使得自变量多的模型更吃亏),从而尽可能消除
过度拟合
的负面影响。在很多情况下,这三条标准都会给出一致的结论,而且也会与真正的样本外验证方法相吻合。为了验证这一点,下面我们列出前面讨论的三个模型的修正R平方、AIC和BIC值,大家不难发现,所有三条标准都显示,模型(2)是三者中最好的模型,这与样本外R平方的结论也是一样的。










