正文
现在,我们可以做一个很简单的类比,把上述更新过程扩展到贝叶斯模型,在线地学习贝叶斯SVM,每个时刻都学到所有模型的一个后验分布。这个想法实际上和前面的更新过程基本上是一样的,差别在于我们更新的是后验分布。假设当前的后验分布是
q
t
(W)
,新
来的数据可以用一个准则判断它到底是正确还是错误,同样对应到两种情况,如果正确的话,表明当前的后验分布足够好了,我可以不去更新,实际操作时如果有似然函数,我可以用贝叶斯定理做一次更新,不会影响这个结果。当我们犯错误的时候,可以做一个Aggressive的更新,得到新的分布。
在错误发生时,我们可以做硬约束或是允许一定错误的软约束,来优化这个错误率。理论分析我这里就不细说了。

这种在线贝叶斯学习的最大好处时它可以处理隐含变量(数据中没有观察到的变量),挖掘数据中的隐含结构。在这种情况下,只需要对前面讲的在线更新的过程稍加扩展即可,基本流程保持不变。
这里讲一个话题模型的例子。比如:我明天要出差,现在想订一个宾馆,那么我可能会打开网站去看它的评论和打分;现在,这方面的数据有很多。假设我们拿到了很多评论文档数据,我们可以做两件事情,一个是挖掘大家关心的主题是哪些,另一个是看看某个具体的评论是倾向于正面还是负面,这实际上是做一个判别。这就可以用我刚才所讲的在线贝叶斯学习来实现。
具体过程我就不讲了。这里给大家看一个效果,横轴是时间,纵轴是分类的正确率(F1值)。这里列出来多个算法,大家显然能看出来,基于在线贝叶斯学习的算法要比使用批处理的方法大约有100倍的性能提升,同时,分类的精度没有下降(甚至可能有提升)。
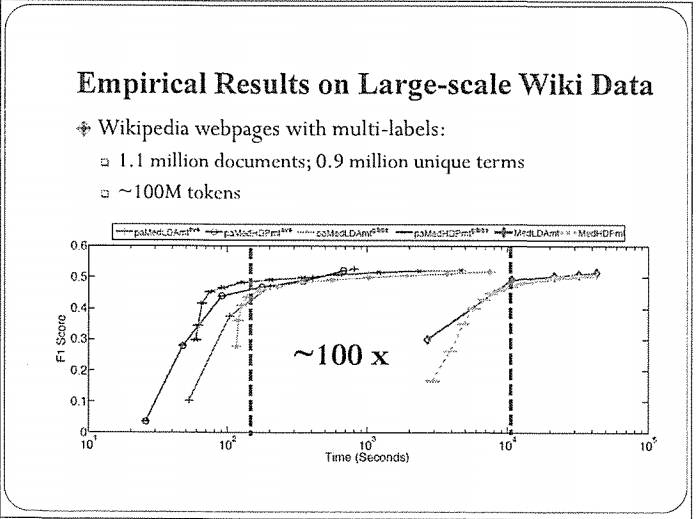
这里边道理是什么呢?实际上,大数据里边通常有很多冗余,在做模型更新的时候没必要把所有的数据都处理一遍,尤其当你的数据集特别大的时候完全没有必要,现在大家训练的深度学习也是一样,最常用的方法是用随机梯度,思想是一样的。我们没必要把上万张图片扫描一遍,再更新模型的权重,少量图片其实就足够了。由于每次计算的数据量非常少,因此,总体时间上有很大优势。
分布式后采样
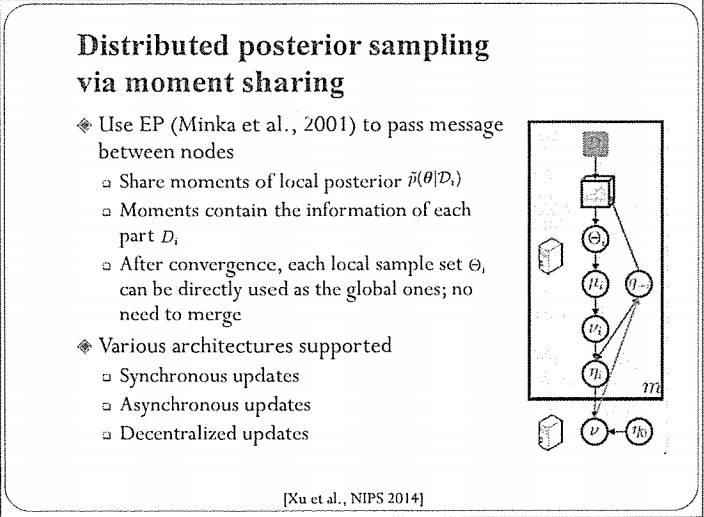
我们前面讲贝叶斯方法本身有一个很好的性质做分布式计算,但是,难点在于我们怎么去做计算。我们在这方面做了一个工作,是基于MCMC蒙特卡洛采样的,发表在NIPS 2014。它的基本思路是,我们把数据划分到多个机器,先采用MCMC的方法去估算局部后验分布(的一些统计量),然后采用期望传播(EP)的框架在多个机器之间传递信息,把采样的样本聚集合在一起,以解决近似后验分布的问题。这个算法收敛之后,每个局部的分布实际上就是我们想要的全局分布。这个算法支持同步更新、异步更新以及去中心化的更新方式,配置非常灵活。
第三部分 深度生成模型(Deep Generative Models)
我接下来讲一些大家可能都很关心的深度学习。我主要介绍一些深度生成模型,包括无监督和半监督学习的模型。

通常情况下,大家做深度学习时,用的更多的是所谓的判别式深度学习,比如深度卷积网络,它的目的是学习一个从输入到输出的影射函数,在测试时,判断测试样本属于哪个类。这种网络已经在人脸识别、语音识别或者自然语言(处理)的很多任务中应用。当然,在实际做的时候,还要注意一些细节,包括一些保护模型、避免过拟合的机制。
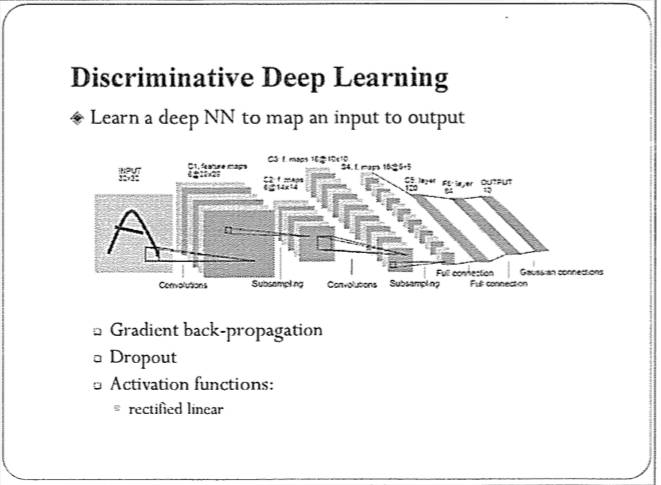
深度卷积网络已经被广泛应用,包括发展出来的一些变种的网络结构。最近,这种网络也用于强化学习,比如AlphaGo。细节这里就不说了,我今天想和大家分享一下,除了这种判别式学习,深度学习实际上还有许多问题值得我们关注。
简单来说,深度学习现在的应用场景有以下三点。大模型;大数据;大集群。
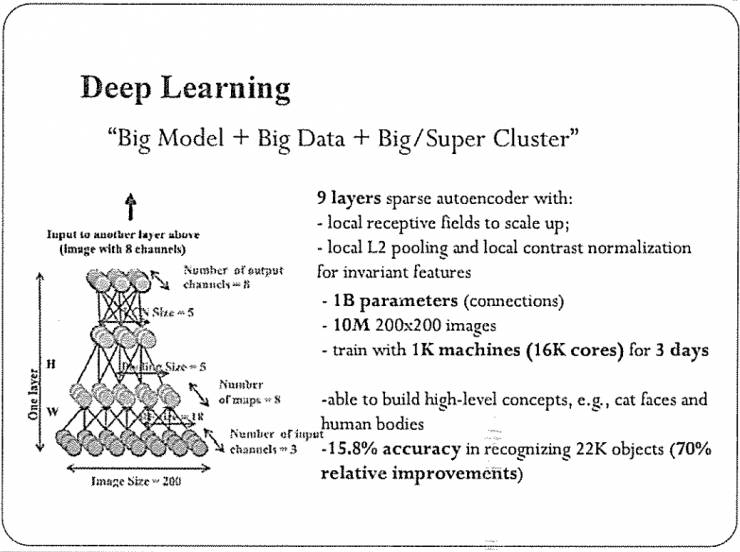
首先,现在的模型比较大,主要体现在它有很多参数。这是2012年的一个例子,它大概有10亿个参数。其次,训练数据比较多,当时的训练使用了1000万的图片。最后,需要很大的计算资源,我可以用CPU或者GPU集群来运算,这几乎成了现在做深度学习的标配。
过拟合
在这种场景下,往往有一个误解:如果有大数据,过拟合就不再是问题了。实际上,我们说,大数据情况下过拟合可能变得更严重。
具体来说,对于一个机器学习算法,我们实际上不是在关心数据的个数有多大,10万也好,100万也罢;我们更关心的是,这个数据里包含的信息有多少,给我们模型训练所带来的统计信息有多大。数据量多会给我们带来很大的处理负担。
这有一个研究结果,它衡量了当数据大小增加时,数据中的相关信息(relevant information)是如何增加的。
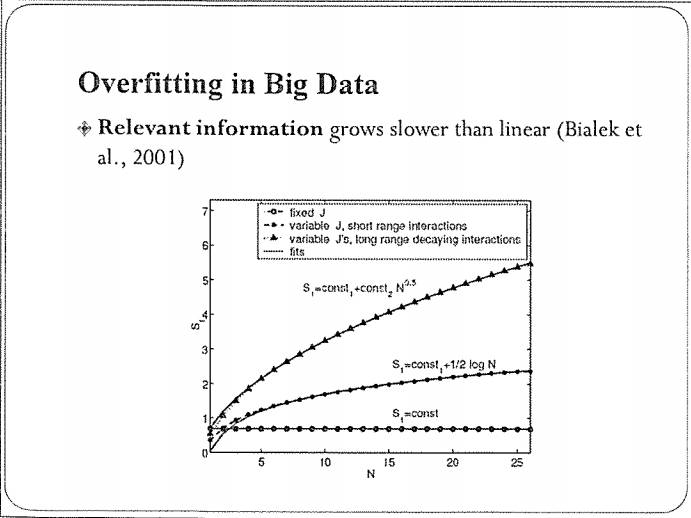
该图呈现了常见的三个情况:
-
第一个是水平线:数据增加时,信息没有增加。这个场景很容易理解,如果你的数据是周期性的、不断重复的,当你知道一个周期的数据之后,基本上覆盖了全部的信息,那么再增加更多周期,对训练模型没有太大帮助。
-
再一个是Log N的曲线:当数据的产生过程可以用有限的参数刻画时,信息量大概是Log N的速度增加。
-
还有更快一些的曲线,N
0.5
,它描述的是更复杂的情况,数据不能用有限阐述的模型刻画,这种情况下信息量也会更多。
总体上,这三种情况下的信息增加速度都远低于线性,充分反映了数据中存在很多冗余。所以,在这种大数据下,过拟合是一个更值得关注的问题。










