正文
层连接
训练深度神经网络时,可以使用一些核心技巧避免梯度消失问题。不同的层和连接因此被提出来了,这里我们将讨论 3 点:i) Highway 层,ii) 残差连接(residual connection),iii) 密集型残差连接。
Highway 层:它受到 LSTM 的门控机制所启发 (Srivastava et al., 2015) [1]。首先让我们假设一个单层的 MLP,它将一个非线性 g 的仿射变换应用到其输入 x:
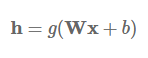
Highway 层接着计算以下函数:
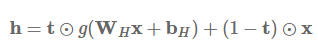
其中 t=σ(WTx+bT) 被称作变换门(transform gate),(1−t) 被称作进位门(carry gate)。我们可以看到,Highway 层和 LSTM 门很相似,因为它们自适应地把输入的一些维度直接传递到输出。
Highway 层主要用于语言建模,并取得了当前最佳的结果 (Kim et al., 2016; Jozefowicz et al., 2016; Zilly et al., 2017) [2, 3, 4],但它同时也用于其他任务,如语音识别 (Zhang et al., 2016) [5]。想了解更多相关信息和代码,可查看 Sristava 的主页(http://people.idsia.ch/~rupesh/very_deep_learning/)。
残差连接:残差连接(He et al., 2016)[6] 的首次提出是应用于计算机视觉,也是计算机视觉在 ImageNet 2016 夺冠的最大助力。残差连接甚至比 Highway 层更直接。我们使用代表当前层的指数 L 来增加之前的层输出 h。然后,残差连接学习以下函数:
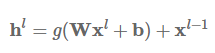
仅通过一个快捷连接,残差连接即可把之前层的输入添加到当前层。这一简单的更改缓解了梯度消失问题,因为层级不能变得更好,模型可以默认使用恒等函数(identity function)。
密集型残差连接:密集型残差连接 (Huang et al., 2017) [7] ( CVPR 2017 最佳论文奖)从每一个层向所有随后的层添加连接,而不是从每一个层向下一个层添加层:
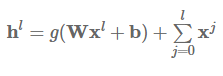
密集型残差连接已成功应用于计算机视觉,也被证明在神经机器翻译方面的表现持续优于残差连接 (Britz et al., 2017) [27]。
Dropout
尽管在计算机视觉领域的多数应用中,批归一化已使其他正则化器变得过时,但是 dropout (Srivasta et al., 2014) [8] 依然是应用于 NLP 深度神经网络中的正则化器。0.5 的 dropout 率表明其在绝大多数场景中依然高效 (Kim, 2014)。近年来,dropout 的变体比如适应性 dropout(Ba & Frey, 2013) [9]和进化 dropout (Li et al., 2016) [10] 已被提出,但没有一个在 NLP 社区中获得广泛应用。造成这一问题的主要原因是它无法用于循环连接,因为聚集 dropout masks 会将嵌入清零。
循环 dropout:循环 dropout(Gal & Ghahramani, 2016)[11] 通过在层 ll 的时间步中应用相同的 dropout masks 来解决这一问题。这避免了放大序列中的 dropout 噪音,并为序列模型带来了有效的正则化。循环 dropout 已在语义角色标注 (He et al., 2017) 和语言建模 (Melis et al., 2017) [34] 中取得了当前最佳的结果。
多任务学习
如果有额外的数据,多任务学习(MTL)通常可用于在目标任务中提升性能。
辅助目标(auxiliary objective):我们通常能找到对我们所关心的任务有用的辅助目标 (Ruder, 2017) [13]。当我们已经预测了周围词以预训练词嵌入 (Mikolov et al., 2013) 时,我们还可以在训练中将其作为辅助目标 (Rei, 2017) [35]。我们也经常在序列到序列模型中使用相似的目标(Ramachandran et al., 2016)[36]。
特定任务层:尽管把 MTL 用于 NLP 的标准方法是硬参数共享,但允许模型学习特定任务层很有意义。这可通过把一项任务的输出层放置在较低级别来完成 (Søgaard & Goldberg, 2016) [47]。另一方法是诱导私有和共享的子空间 (Liu et al., 2017; Ruder et al., 2017) [48, 49]。
注意力机制
注意力机制是在序列到序列模型中用于注意编码器状态的最常用方法,它同时还可用于回顾序列模型的过去状态。使用注意力机制,系统能基于隐藏状态 s_1,...,s_m 而获得环境向量(context vector)c_i,这些环境向量可以和当前的隐藏状态 h_i 一起实现预测。环境向量 c_i 可以由前面状态的加权平均数得出,其中状态所加的权就是注意力权重 a_i:
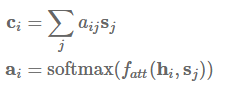
注意力函数 f_att(h_i,s_j) 计算的是目前的隐藏状态 h_i 和前面的隐藏状态 s_j 之间的非归一化分配值。在下文中,我们将讨论四种注意力变体:加性注意力(additive attention)、乘法(点积)注意力(multiplicative attention)、自注意力(self-attention)和关键值注意力(key-value attention)。
加性注意力是最经典的注意力机制 (Bahdanau et al., 2015) [15],它使用了有一个隐藏层的前馈网络来计算注意力的分配:
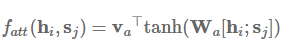
其中 v_a 和 W_a 是所学到的注意力参数,[* ; *] 代表了级联。类似地,我们同样能使用矩阵 W_1 和 W_2 分别为 h_i 和 s_j 学习单独的转换,这一过程可以表示为:










