正文

深度学习为什么叫深度学习?就是因为里面的层数很多,层数多了就叫深。AlexNet在2012年,做了一个八层的网络。这之前,大多数的网络只有三层,但是这个方法当时是受到质疑的。过了两年,一个牛津大学的研究组,把深度推到了20层;然后2015年微软研究团队做了个ResNet:152层的网络。
网络有多少层数今天已经不重要了,
其中的基本思想是:学习一个很深的神经网络,是要学习一个映射。
相邻几层之间的映射变化不大,这是很直观的想法。变化不大的话,我们就用残差学习的方法,不要直接学习重构网络,而是学习它的变化,变化比直接学会更容易。
训练过程中,是由浅到深的动态。在早期训练过程中,可能是训练浅层网络,在后期时训练深层网络。因为早期浅层网络没办法帮助训练深层网络。
深度学习的效果
这样的深度算法网络,有什么样的效果?这是ImageNet:斯坦福的李飞飞教授,带着他的学生建立的数据集。2000多万张照片,有10几万类,这些照片都是从图像中爬下来的,这个数据库比以前用的更小的数据库真实,主要在上面做分类。

深度学习解决的问题
多层的网络能解决什么问题?意味着什么问题?CVPR 2016最佳论文奖,它解决了深度学习的优化问题。虽然说神经网络是一个很古老的技术,但是它在今天可以通用,是中间一点一滴的进步造成的,包括数据越来越大,计算力越来越好。但是做的这个残差网络是说,这个网络的体系结构要对优化友好。然后结合前人的工作积累在一起,才有了今天可以反复训练,效果非常好的系统。

这篇论文里面优化的问题,深度学习的三大问题。
第一个问题是表述能力的问题
。也就是这个模型本身有多少能力的问题。
第二个问题是,假如系统有这个能力,算法能不能找到这个最优解?能把参数调合适吗?
第三个问题是推广能力的问题
,推广能力的问题又分成两类:弱推广能力和强推广能力。机器学习研究的基本问题是:训练数据和测试数据的统计是同分布的。弱推广能力是指,如果训练数据和测试数据不同分布,就不管了。强推广能力是指,真正理解了这件事情的表示,遇到新的训练数据集统计、分布和训练数据集,也可以去做。
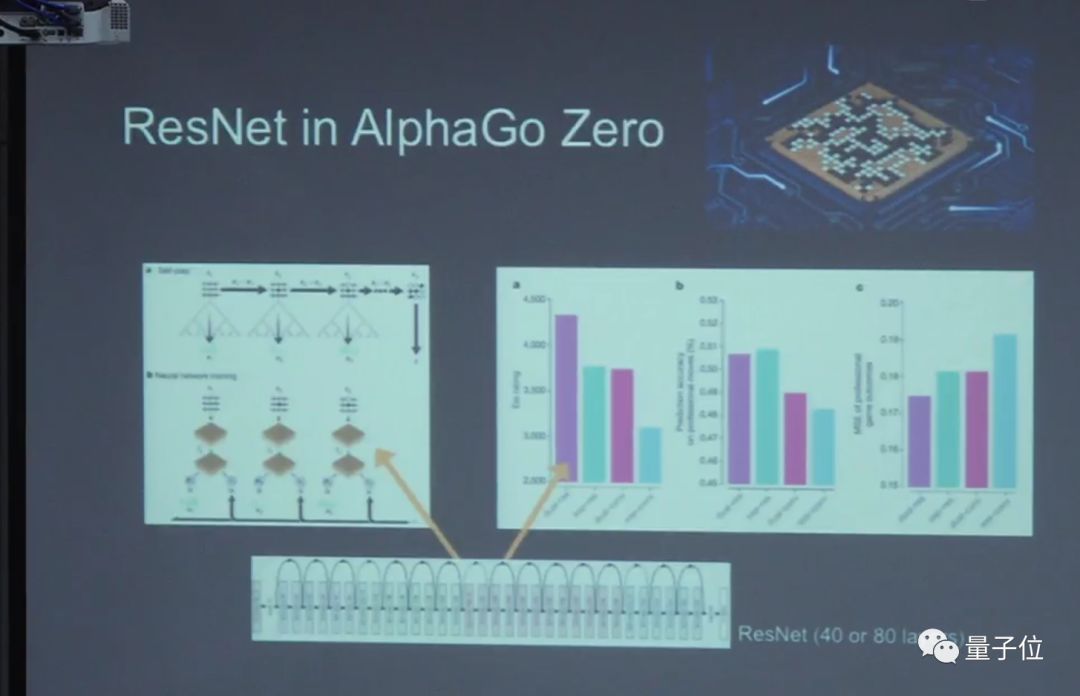
去年AlphaZero他们也用了残差网络来做AlphaZero核心的技术。
视觉发展时间线

这是视觉识别常用的从2012年到2016年的网络结构,表现出了图像分类很大的变化,最近的新趋势是大家逐渐开始用机器来设计这些网络结构。
视觉的检测
视觉检测非常有用。几年前,做人脸、车的识别,能到70、80分;到了今天,我们可以做很复杂的逻辑检测,训练数据也是足够多的。
最近几年,检测的趋势也是设计物体检测的框架,不光是指神经网络的结构,检测是更复杂的系统。
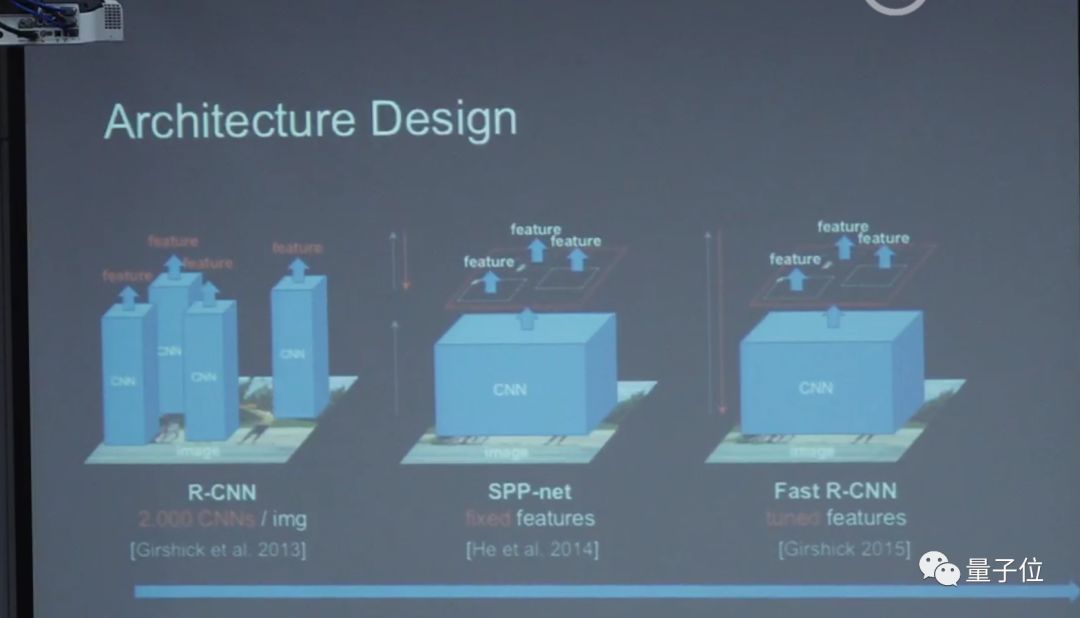
在2013年神经网络刚出来时,微软的一个名叫Rose的研究员做了一个方法:检测在图像中所有位置都让给CNN。我们之后所有东西都是基于这个思想,这也是物体检测中,最近几年最大的突破。
把前面和后面都做反常学习,Feature也重新更新了,效果很好,这就是Fast R-CNN。但是这里有一个问题:窗口还是人工设计的,其实也很慢。后来我们和Rose合作了第一个N2N的检测系统,不需要人工设计成这样的Feature,但框架还是需要设计。
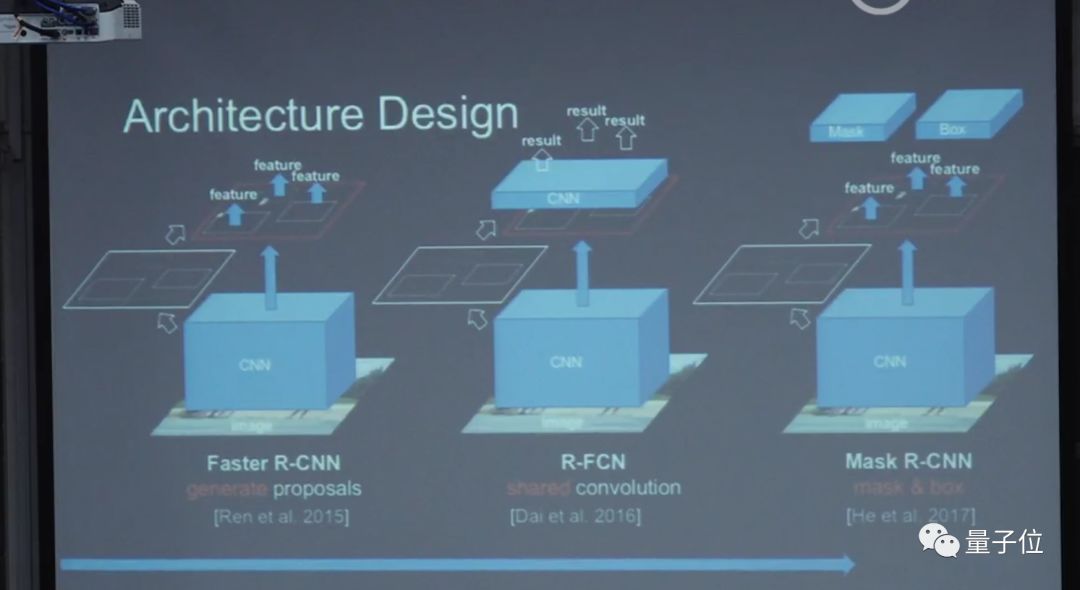
后来又更优化了一下,做了一个非常有效的一步法检测器设计,这个就是Mask R-CNN,目前是最好的物体检测系统。

这是2017年COCO的比赛。在2015年Face++做到37.3;去年做到52.25,得了冠军。
COCO冠军
夺到冠军背后的工作是什么呢?





