正文
Timestamp:即时间戳,用来描述产生时序数据的时间点,上面的1497344217
Data Point:即某个Metric在某个时间点的数值。
1)Data Point包括以下部分:Metric、Tags、Value、Timestamp
2)上面描述的本场分享在21:09时候的同时在线用户,就是1个DataPoint
数据特点:
-
基本上都是插入,没有更新的需求;
-
数据基本上都有时间属性,随着时间的推移不断产生新的数据,旧的数据不需要保存太久;
-
业务方对时序数据通常有几个查询需求;
-
获取最新状态,查询最近的数据(例如传感器最新的状态);
-
展示区间统计,指定时间范围,查询统计信息,例如平均值,最大值,最小值,计数等;
-
获取异常数据,根据指定条件,筛选异常数据。
跟普通数据的区别1:
跟传统数据库的区别2:
时序数据库要解决的问题:
-
以时间点为顺序产生的数据;
-
数据量大,数据来源多;
-
数据的维度多,不同指标有不同维度;
-
统计查询复杂,如任意时间访问,多粒度的检索;
-
需要快速响应查询;
-
对中小团队收益特别大。
在《解密Google SRE》一书中作者提到了Google的监控系统borgmon 和 prometheus非常像。prometheus是一款开源的时序数据库,可以想见Google也是用的类似时序数据库进行监控。Fackbook开源了时序数据库引擎Beringei。他们内部也用的这个做监控。阿里巴巴的Goldeye黄金眼,也是一款时序数据库;百度云产品TSDB,主要用于物联网相关的监控;国内非常火的监控系统Open-falcon也是一款开源时序数据库。当然还有知名的开源软件:Graphihe、OpenTSDB、InfluxDB、Druid、TimeScaleDB等。
我们看下DB-Engine网站对时序数据库的排行。
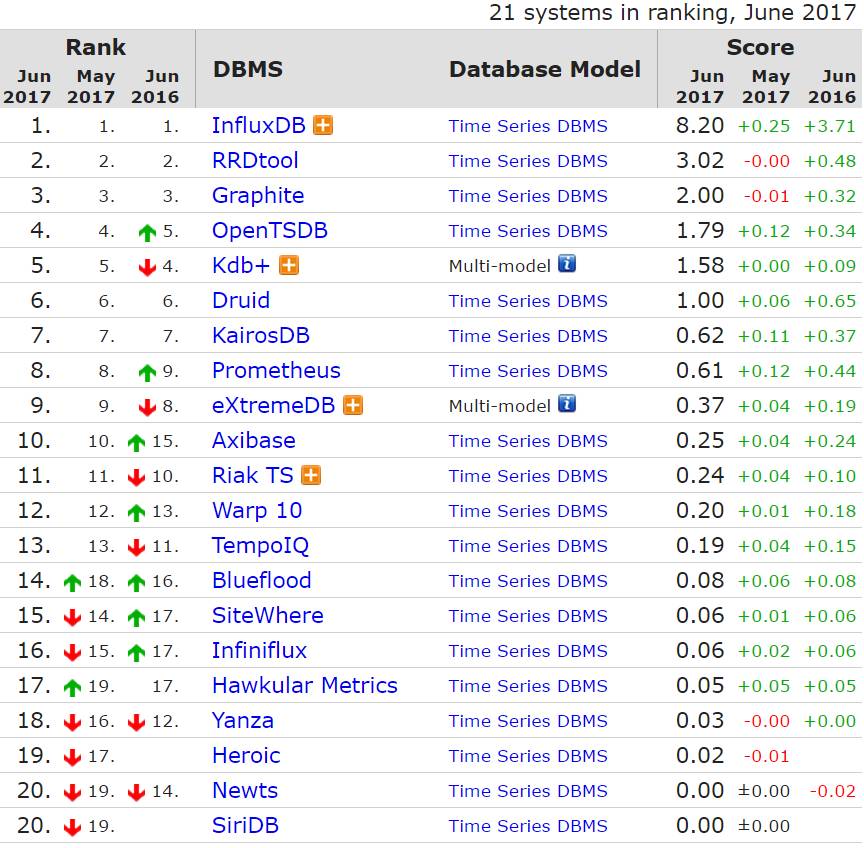
出处:https://db-engines.com/en/ranking/time+series+dbms
参考资料:http://liubin.org/blog/2016/02/25/tsdb-list-part-1/
这里以
OpenTSDB
为例重点介绍下时序数据库的一些技术。
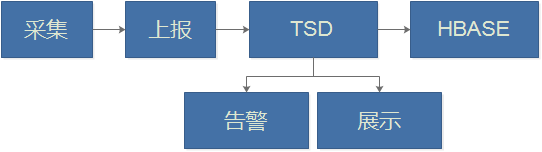
OpenTSDB
的核心,本身比较简单,是Java实现的一套程序。用来读写底层存储及数据处理。
存储:
OpenTSDB
底层存储使用的HBase,自然ZooKeeper、HBase、Hadoop HDFS是少不了的。其架构分布式、高可用也是由HBase实现。
Rowkey的设计是亮点:
Rowkey: metric + timestamp + tagk1 + tagv1… + tagkN + tagvN
HBase(main):003:0> scan 'tsdb'
ROW COLUMN+CELL
\x00\x00\x01U\x9C\xAEP\x00\x column=t:q\x80, timestamp=1497344217, value=\x17 00\x01\x00\x00\x01\x00\x00\x 02\x00\x00\x02
说
OpenTSDB
没有设计模式是指上层上报来的数据,在底层
OpenTSDB
还是有存储表的,在往HBase中写入和查询使用了一套自定义的数据结构,
OpenTSDB
的存储格式是在HBase存储了几个表:
-
Data Table:表名默认叫
tsdb
,存储时序数据的表。
-
UID Table:表名tsdb-uid,UID映射表,时序数据存储时不用实际的字符串,而是经过此表映射之后,取得一个UID,存储在data table中的其实是整个uid。
-
Meta Table:元数据表,时间序列数据的索引表。
-
Tree Table :树表,也是存储元数据用的。
-
Rollup 表:存储rollup 和 pre-aggregation的数据。
OpenTSDB
有多个展示端,Grafana是其中一个支持得较好的。前面文章也讲到了Grafana,这里不多讲。
采集支持udp协议、http协议、telnet。可使用多种采集上报方式,包括脚本、应用内上报等。
保存数据最简单的方式是:
$ telnet localhost 4242
put sys.cpu.user 1497344217 23 host=web01 user=mirzhang








