正文
其他的数据则写入存储层或者数据库存储这一层。数据经过 Spark、Flink、Zepplin 加载之后,再通过他们各自的数据可视化工具进行历史数据的展现,比如像 Elasticsearch、Zeppelin 等。
整个我们的实时系统拓扑结构就是这样,但是可能最后有一层的工具是没有显示出来,因为这个随时会有变化。
2.2 为了解决我们的疼点,DEVOPS起步了
我们的起步就如这幅图片里一样,产品碰到 BUG 了,我们经常会开讨论会,而每次会议中的场景就像图片中看到的一样。

最开始我们定位 Developer 是问题的瓶颈,我们开始盘查问题并逐一分析问题原因,发现运维上在发布更新的过程中能及时的反馈和发现 BUG,最后大家都希望通过 DevOps 开发新的产品来面对这些问题,剩下一些人只能干看着。
在运维看来,问题原因其实很简单,因为只有 DevOps 知道你的日志怎么查,去哪儿查。其他人没有像 DevOps 这么了解,一般公司都是有 Ops 这个环节的,但是在我们公司没有,在我们公司只有开发,Dev 写的代码,谁开发的谁去运维,谁去改进,谁去改 Bug。
问题定位一直都是我们的疼,我们就带着这样的疼起步了。
2.3 解决问题的良方—ELK
所以为了解决这个问题瓶颈,我们要把数据收集到一起,降低查问题的成本,所以我们引入了 ELK 工具,这个工具应该大家都了解。
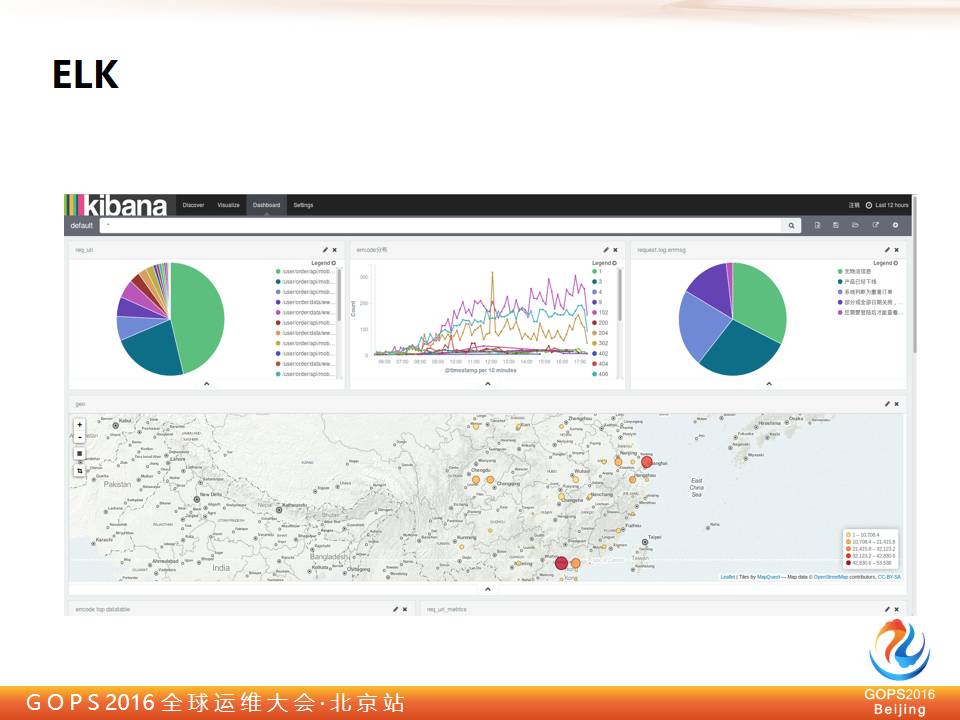
这是 Kibana 数据展示层的界面,大家可以很容易的看到数据的分布。非常简单易操作,而且数据分析挖掘能力非常强,很容易的可以通过条件在整体数据里检索,也很容易就交叉定位出故障的问题点。
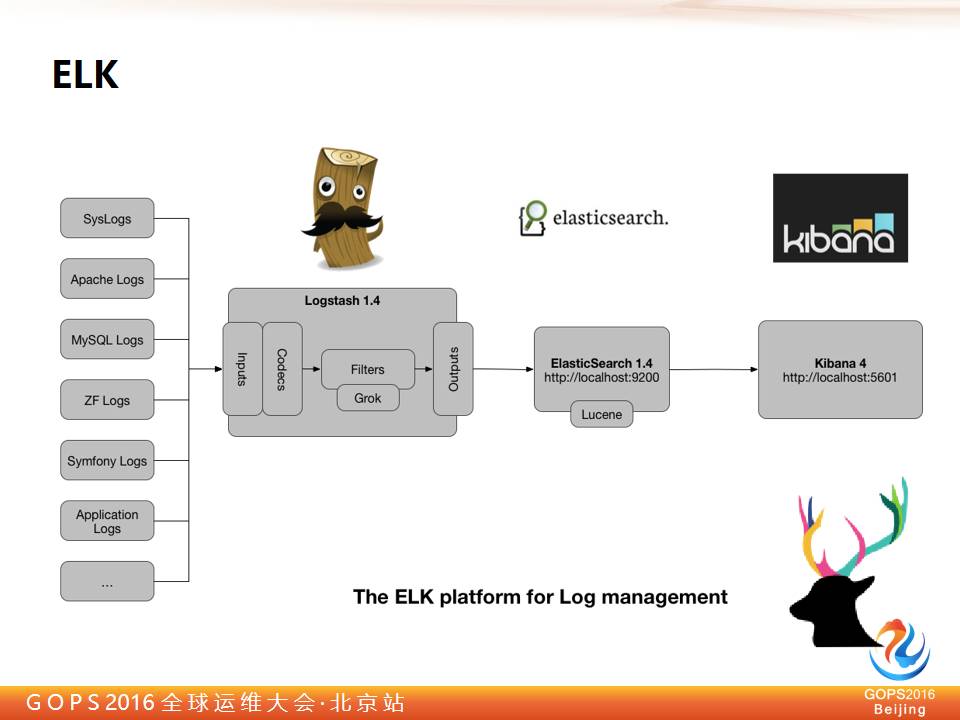
再简单看一下 ELK 是什么,棱镜(Prism)和 ELK 收集层差不多,基础的日志棱镜(Prism)都有,都是 ELK 演进过来的。它中间是个 Logstash 是做 ETL 用的。然后在到 Elasticsearch 做数据检索,最后 Kibana 显示出来,Kibana 在 BI 的能力上还是比较强的。
在做棱镜(Prism)这个系统的时候是从一个项目使用 ELK 开始的,之前我们有一个酒店的项目,它有几百台机器,然后根据城市来做的哈希,每次上线的时候要根据区域或者城市,来一部分一部分的做发布。
每次发布的时间大概要花费六七个小时,经常是从晚上十点开始发,一直发到凌晨四点钟那样的。发布了一个晚上第二天就没法工作了,在搭建了 ELK 之后时间大大的压缩了,起码凌晨一两点钟肯定能回家了。
这是因为分发的速度其实很快,有了 ELK 后,很快就能发现发布的结果是不是有问题,之前发布是要通过一台一台的去扫描日志,但是那个没有统一平台,效率非常低。
我们做完这个系统之后,ELK 系统很受欢迎,这种方式是大家非常接受的,能够极大的提升大家的效率,所以很多人来要求我们给他们做同样的工具,一开始我们部署方式是这样,我们部署方式是申请虚拟机账号,添加账号。
原本每次分发需要六七个小时的更新分发任务,在使用 ELK 之后分发速度节约近一半时间,原本晚上十点开始的更新任务,要更新到凌晨四点,更新的工作人员第二天都没精神工作。现在工作人员最多更新到凌晨一两点就能回家了,一般都能在12点前更新完成回家。
更新的时候,任务下发,速度是很快的,导致慢的原因往往是在更新中卡住了,而我们并不知道问题在哪,哪里未完成。ELK 能帮我们快速的定位问题在哪里,我们可以快速响应处理。这与原先使用工具来扫描校验结果正确性的方式相比,实时性准确性以及全局性都大大提高了,问题定位更加精确。





