正文
调度系统核心指标
-
资源利用率
:即提高整体物理集群的资源利用率。一个优秀的调度系统可以把资源利用率提高到30%~70%,而简陋的调度系统甚至会使资源利用率降低到10%以下。
-
业务最优化
:即保障运行业务的稳定高可用,以及服务相互调用的优化。比如,如果调度系统一味的追求资源利用率,将宿主机上堆砌超过其负载能力的实例,又或一台宿主机/机架的故障会影响到一个服务下所有实例的运行,都在业务稳定性上打了折扣。
-
并发调度能力
:调度系统请求处理能力的体现。一个大规模的物理集群上,往往运行数以千百计的业务,当出现调度请求高峰的场景下,调度系统要有能力在短时间内给出答案,即使这个答案可能只是全局近似最优解。
调度系统设计难题
调度系统设计的难题,在于
几个调度核心指标在实现上存在的矛盾关系
,类似于CAP理论中的三要素,无法同时满足。
在CAP理论中,Consistency(一致性)、Availability(可用性)与Partition Tolerance(分区容错性)无法同时满足。如果追求可用性与分区容错性,则需要牺牲强一致性,只能保证最终一致性;而如果要保障强一致性与可用性,如果出现网络故障将无法正常工作。
类似的,在调度系统中,如果要追求极限的资源利用率,则每一次调度的结果必须是基于当前资源池状态的最优解,因此不管调度队列还是调度处理计算只能是“单行道”,效率低下是毋庸置疑的,大批量伸缩调度场景下任务堆积严重。
如果追求高效的调度能力,则所有调度请求需要并发处理。但底层资源池只有一个,很容易出现多个调度请求争抢同一份资源的情况。这种情况下,就要采取措施来保障资源层数据一致性,且调度所得的结果不能保证是全局最优解(无法最大化资源利用率)。
业界解决思路
Mesos
Mesos采用双层调度的理念,把应用相关的管理交由上层Framework来做,这也是Mesos与Kubernetes等系统最大的不同点。Mesos只是分布式系统内核,即管理分布式资源、对外暴露标准接口来操作集群资源(屏蔽资源层细节)。在双层调度的模式下,Mesos只负责在不同的Framework之间分派资源,将资源作为Offer的形式提供给Framework。
这种做法把上述调度设计矛盾丢给了Framework,但如果只从提供资源Offer的角度来看,这是一种并发调度的形式(同一个Mesos资源池,资源要提供给上层多个Framework)。Mesos解决并发调度、资源池数据一致性的方案是,资源Offer同时只会分派给一个Framework。这种资源分派方式是悲观的,资源被Framework独占,直到返回或超时。
显然,这种悲观锁导致了Mesos双层调度的并发粒度较小,但是在多数情况下,同个Mesos集群上层的Framework数量不会太多,有时只有一个Framework在独享资源,因此这种悲观锁的方案一般不会存在分配调度的瓶颈问题。
Omega
Omega同样采用了将资源分派给上层应用的调度方式,与Mesos的悲观锁不同,Omega采用了乐观锁(MVCC,基于多版本的并发访问控制)解决并发调度的问题,因此Omega也被称为共享状态调度器。
由于将资源层信息作为共享数据提供给上层所有应用,Omega为了解决数据一致性,会对所有应用调度的提交冲突做解决,本质上是为每个节点维护了一个状态关系数据库。从这个角度看,Omega也存在一些缺点:
-
共享调度时冲突发生的频率,直接影响了整体调度器的性能。
-
由于没有集中的调度模块,难以对所有资源分组(Namespace)或用户的资源使用量做精确限制。
-
上层调度器数量仍然不能很多,并行分发完整集群状态的开销较大。
Borg与Kubernetes
Borg据说现在已经逐渐演进吸收了Omega的很多设计思想,包括共享状态调度模式,然而Kubernetes默认调度plugin的做法仍然是串行处理队列中的调度任务,这也符合Kubernetes追求的简洁优雅。
HULK调度解决方案
对于调度器设计难题,我们认为针对不同的场景,指标的侧重点不同。
比如对于分布式系统的CAP,大多数互联网场景下都会保证AP而舍弃C(只保证最终一致性),因为在互联网分布式集群规模大、网络故障频发的场景下,要保证服务高可用只能牺牲强一致;而对于金融等涉及钱财的领域,则一般保证CA、舍弃P,即使遇到网络故障时只读不写,也必须保证强一致性。
同理对于调度器资源层设计,在互联网高并发、弹性伸缩频发的场景下,可以
牺牲部分资源利用率从而提高并发调度能力
。
HULK调度系统模型如下:
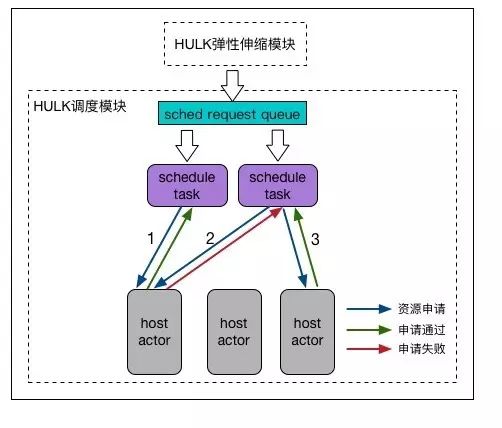
HULK调度模型
如图,HULK调度系统分为
调度请求队列、调度计算模块、调度资源池
这三个模块。工作流程如下:
-
上层HULK弹性伸缩系统,将调度任务ID写入调度请求队列中。
-
HULK调度系统消费调度请求队列,取出的调度任务ID将由调度计算池执行调度计算,决策出备选的部署位置,并向调度资源池申请资源。
-
调度资源池维护管理宿主机集群资源,全部资源会提供给所有调度任务共享(与Omega类似),资源池中每个宿主机都有一个对应的Actor来负责管理。
调度计算模块(资源调度算法)







