正文
图三:递归神经网络能够生成输出序列,同时复用各输出单词作为下一函数的输入内容。
递归神经网络能够利用一套联合模型将输入(读取)与输出(生成)内容加以结合,其中输入递归神经网络的最终隐藏状态将被作为输出递归神经网络的初始隐藏状态。通过这种结合方式,该联合模型将能够读取任意文本并以此为基础生成不同文本信息。这套框架被称为编码器-解码器递归神经网络(亦简称Seq2Seq),并作为我们这套汇总模型的实现基础。另外,我们还将利用一套双向编码器替代传统的编码器递归神经网络,其使用两套不同的递归神经网络读取输入序列:一套从左到右进行文本读取(如图四所示),另一套则从右向左进行读取。这将帮助我们的模型更好地根据上下文对输入内容进行二次表达。
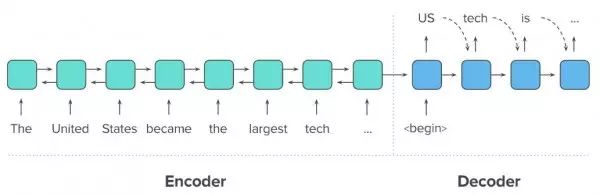
图四:编码器-解码器递归神经网络模型可用于解决自然语言当中的序列到序列处理任务(例如内容汇总)。
新的关注与解码机制
为了让我们的模型能够输出更为一致的结果,我们利用所谓时间关注(temporal attention)技术允许解码器在新单词生成时对输出文档内容进行回顾。相较于完全依赖其自有隐藏状态,此解码器能够利用一条关注函数对输入文本内容中的不同部分进行上下文信息联动。该关注函数随后会进行调整,旨在确保模型能够在生成输出文本时使用不同输入内容作为参考,从而提升汇总结果的信息覆盖能力。
另外,为了确保模型不会发生重复表达,我们还允许其回顾解码器中的原有隐藏状态。在这里,我们定义一条解码器内关注函数以回顾解码器递归神经网络的先前隐藏状态。最后,解码器会将来自时间关注技术的上下文矢量与来自解码器内关注函数的上下文矢量加以结合,共同生成输出结果中的下一个单词。图五所示为特定解码步骤当中这两项关注功能的组合方式。
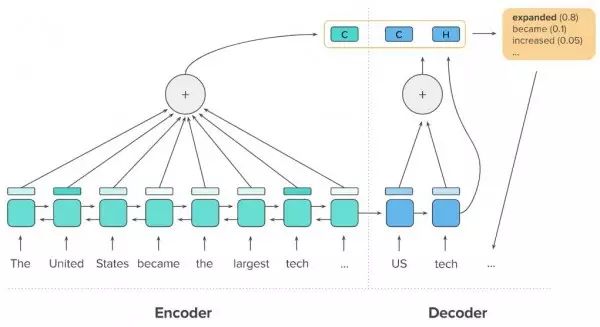
图五:由编码器隐藏状态与解码器隐藏状态共同计算得出的两条上下文矢量(标记为‘C’)。利用这两条上下文矢量与当前解码器隐藏状态(标记为‘H’)相结合,即可生成一个新的单词(右侧)并将其添加至输出序列当中。
如何训练这套模型?监督学习与强化学习
要利用新闻文章等实际数据对这套模型进行训练,最为常规的方法在于使用教师强制算法(teacher forcing algorithm):模型利用参考摘要生成一份新摘要,并在其每次生成新单词时进行逐词错误提示(或者称为‘本地监督’,具体如图六所示)。
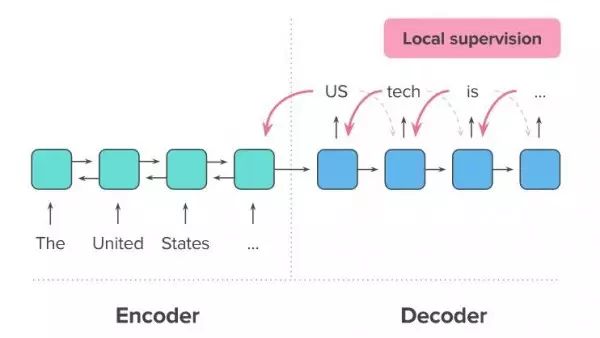
图六:监督学习机制下的模型训练流程。每个生成的单词都会获得一个训练监督信号,具体由将该单词与同一位置的实际摘要词汇进行比较计算得出。
这种方法可用于训练基于递归神经网络的任意序列生成模型,且实际结果相当令人满意。然而,对于我们此次探讨的特定任务,摘要内容并不一定需要逐词进行参考序列匹配以判断其正确与否。可以想象,尽管面对的是同一份新闻文章,但两位编辑仍可能写出完全不同的摘要内容表达——具体包括使用不同的语言风格、用词乃至句子顺序,但二者皆能够很好地完成总结任务。教师强制方法的问题在于,在生成数个单词之后,整个训练过程即会遭受误导:即需要严格遵循正式的总结方式,而无法适应同样正确但却风格不同的起始表达。
考虑到这一点,我们应当在教师强制方法之外找到更好的处理办法。在这里,我们选择了另一种完全不同的训练类型,名为强化学习(简称RL)。首先,强化学习算法要求模型自行生成摘要,而后利用外部记分器来比较所生成摘要与正确参考文本间的差异。这一得分随后会向模型表达其生成的摘要究竟质量如何。如果分数很高,那么该模型即可自我更新以使得此份摘要中的处理方式以更高机率在未来的处理中继续出现。相反,如果得分较低,那么该模型将调整其生成过程以防止继续输出类似的摘要。这种强化学习模型能够极大提升序列整体的评估效果,而非通过逐字分析以评判摘要质量。









