正文
3、
秒针
:2016年垂直网站与网盟媒体异常流量占比最高。其中,垂直类媒体曝光异常大幅增至 24.93%,点击异常中网盟类媒体最为明显,占比高达 71.07%。
4、
AdMaster
:2016年全年无效流量整体占比为30.2%;下半年出现小幅度恶化现象,无效流量增加3.7%;
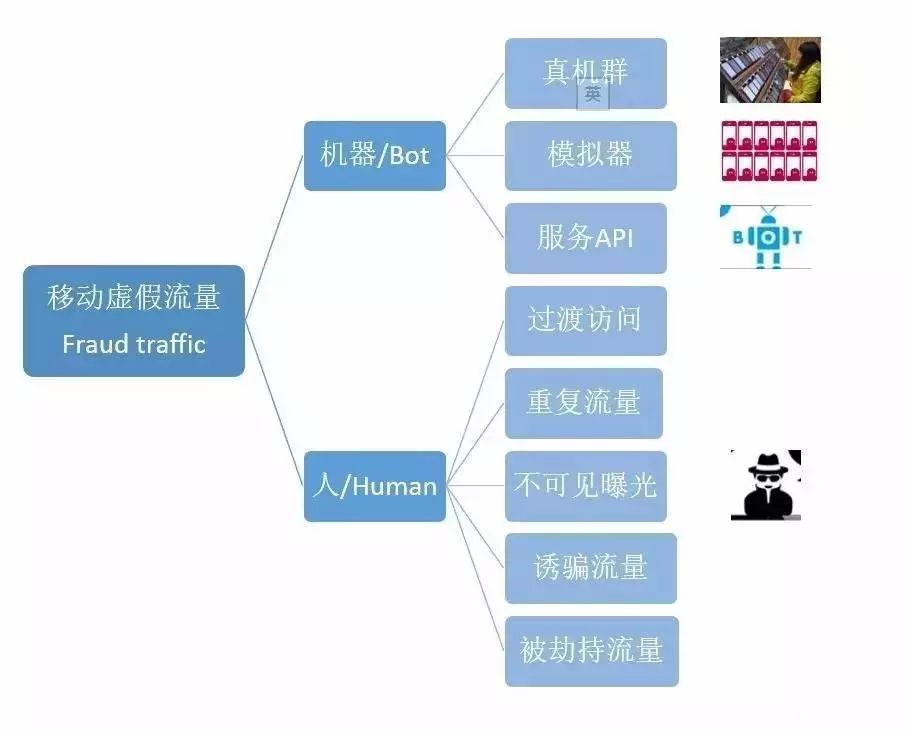
四、移动虚假流量的分类
虚假流量有很多种分类,各种分类都会有灰色的领域,下面我试图用作弊的基本原理方式来分类,而且主要是针对移动的场景。更加全面和系统的分类,可以参考刘鹏老师的《
互联网广告作弊十八般武艺
》。
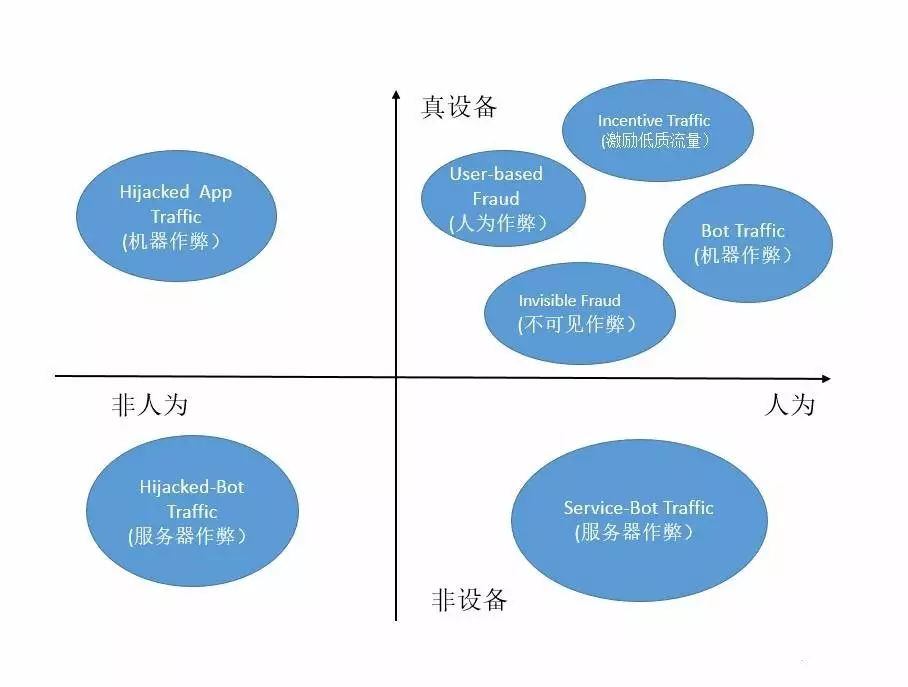
另外一种分类可以按照设备和人为的四象限分类:
五、移动反虚假流量的模型
在讨论如何对付移动虚假流量的方法之前,我们先看看移动作弊的一些主要黑技术,做到知己知彼。
移动作弊中涉及很多黑技术,其中包括一下一些:
-
模拟器:BlueStacks, AndyWin, GenyMotion
-
Spoofer: 不断的修改机器的IP , IMEI, MAC等
-
Proxy: 网关,修改ISP, IP, UA , 设备类型等
-
苹果: 没有模拟器,主要通过硬件和软件模拟
-
激励流量(incent Traffic ): 真实人流量,但是转化率差的流量
...
对于如何防范移动虚假流量,这确实是一个复杂的问题。并非没有防范作弊的高端技术,也不是因为这个问题不够严重,最主要的原因有三个。
例如,最近友盟+在法院起诉某家App刷量公司,理由是影响了友盟统计计算的正确性和公正性。目前法院并没有判定,我也不得知其诉讼的合理性。打个比方,有一个刷墙公司把路上所有广告牌都刷成某家公司,然后有一个品牌影响力排名公司去控告这个刷墙公司,严重影响了它的品牌排名公正性。总感觉这个逻辑,不算太对。我也确实非常讨厌App刷量公司,但是从哪个角度去批判和惩罚他们,确实值得法律法规上更多的讨论。
不聊伦理和法规,聊聊技术吧,我觉得技术上可以按照如下模型来对付虚假流量,这里特指移动端。
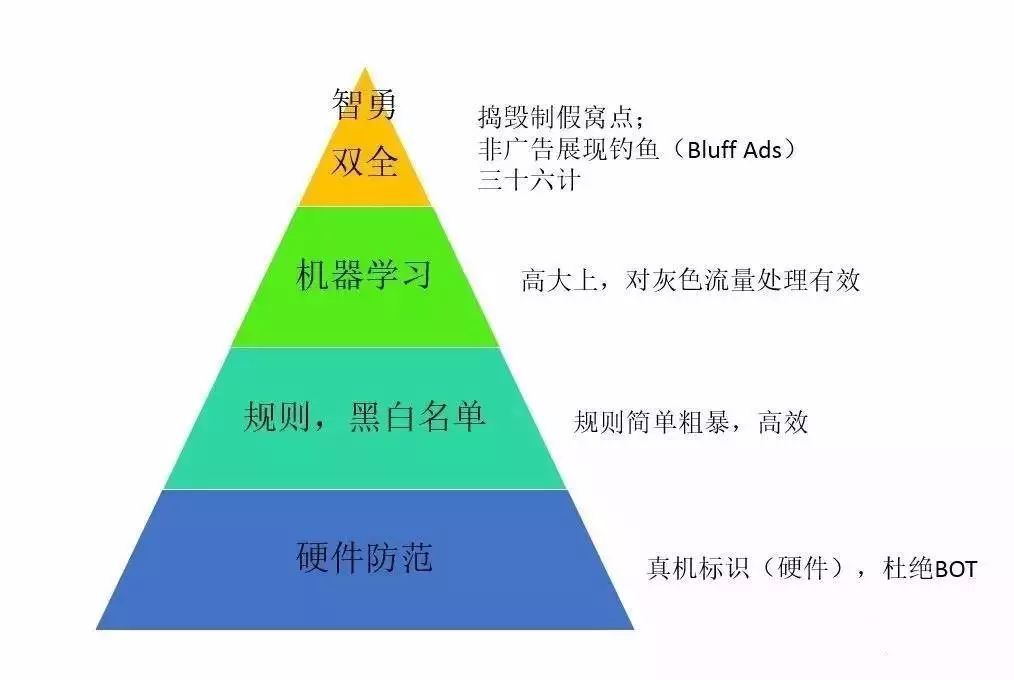
硬件:
手机拥有更多的硬件信息,因此通过硬件信息进行虚假流量的防范,可以防范通过非手机(即Bot,服务器等)的虚假流量。虽然,现在手机系统提供了有一些标准函数可以获得硬件信息,例如IMEI,MAC等,但这些函数很容易被一些通用软件工具所攻破。另外,这个硬件标识的信息,也无法在服务器端得到有效校验。因此,在虚假流量的斗争中,第一步往往就是识别流量的来源,是真实手机,还是模拟器,服务器模拟等工具。
规则策略:
规则往往是最简单有效的防范机制,例如,对于第一次访问全新流量,将虚假流量的可能性设置为高。对于每天多余X次的有规律访问,坚决抵制等等。规则有很多很多,不断的增加,修改,发展到最后,规则的匹配次序也成了一门艺术了。对于一些初级的造假者,往往会落到这些规则中。
机器学习:
机器学习就是通过一些训练数据集合训练出一个分类器,对于一些特征,训练出一些权重信息,而后用于流量的分类识别上。做虚假识别的团队很多时候在这个方向会越做越深,使用更多的特征,使用更多数据,使用更加及时的数据,尝试更多的模型。这个领域工作很“苦”,做严格了,收入可能受影像,做宽松了,广告主投诉ROI下降,这种平衡有点里外不是人。
智勇双全:
有些作弊并非一定通过死板的技术手段完成的,其实有很多五花八门的方法。举例来说,通过加大对于媒体的惩罚力度,可以提高媒体的作弊成本,从而降低作弊率。另外,还有一种有趣的反作弊方法,叫做Honey Ad(有时也叫Bluff Ad),这些广告有些特点(例如,预期点击率很低),通过观察点击率是否和预期一样,可以判断流量是否是机器流量(机器流量无法判断这些广告的贴点)。

六、识别虚假流量的技术流派
这一部分主要是集中在通过机器学习的办法辨识虚假流量的技术,有一大部分内容可以在相关的论文中找到。
6.1 分类方法
大部分算法工程师在处理虚假流量都是从分类技术开始的,构造一个分类器,找各种各样的特征,找到一些虚假流量的(例如转化率异常)训练数据。这种方法对于对于虚假流量的样本非常依赖,不同的样本很容易训练出不同的模型,容易过渡拟合。 对于新的虚假流量模式,不容易及时发现。









