正文
CAP理论
CAP理论是指,分布式系统中,一致性、可用性和分区容忍性最多只能同时满足两个。
一致性
-
通过某个节点的写操作结果对后面通过其它节点的读操作可见
-
如果更新数据后,并发访问情况下后续读操作可立即感知该更新,称为强一致性
-
如果允许之后部分或者全部感知不到该更新,称为弱一致性
-
若在之后的一段时间(通常该时间不固定)后,一定可以感知到该更新,称为最终一致性
可用性
分区容忍性
一般而言,都要求保证分区容忍性。所以在CAP理论下,更多的是需要在可用性和一致性之间做权衡。
Kafka基于ISR的数据复制方案
如《
Kafka High Availability(上)
》一文所述,Kafka的数据复制是以Partition为单位的。而多个备份间的数据复制,通过Follower向Leader拉取数据完成。从一这点来讲,Kafka的数据复制方案接近于上文所讲的Master-Slave方案。不同的是,Kafka既不是完全的同步复制,也不是完全的异步复制,而是基于ISR的动态复制方案。
ISR,也即In-sync Replica。每个Partition的Leader都会维护这样一个列表,该列表中,包含了所有与之同步的Replica(包含Leader自己)。每次数据写入时,只有ISR中的所有Replica都复制完,Leader才会将其置为Commit,它才能被Consumer所消费。
这种方案,与同步复制非常接近。但不同的是,这个ISR是由Leader动态维护的。如果Follower不能紧“跟上”Leader,它将被Leader从ISR中移除,待它又重新“跟上”Leader后,会被Leader再次加加ISR中。每次改变ISR后,Leader都会将最新的ISR持久化到Zookeeper中。
至于如何判断某个Follower是否“跟上”Leader,不同版本的Kafka的策略稍微有些区别。
-
对于0.8.*版本,如果Follower在replica.lag.time.max.ms时间内未向Leader发送Fetch请求(也即数据复制请求),则Leader会将其从ISR中移除。如果某Follower持续向Leader发送Fetch请求,但是它与Leader的数据差距在replica.lag.max.messages以上,也会被Leader从ISR中移除。
-
从0.9.0.0版本开始,replica.lag.max.messages被移除,故Leader不再考虑Follower落后的消息条数。另外,Leader不仅会判断Follower是否在replica.lag.time.max.ms时间内向其发送Fetch请求,同时还会考虑Follower是否在该时间内与之保持同步。
-
0.10.* 版本的策略与0.9.*版一致
对于0.8.*版本的replica.lag.max.messages参数,很多读者曾留言提问,既然只有ISR中的所有Replica复制完后的消息才被认为Commit,那为何会出现Follower与Leader差距过大的情况。原因在于,Leader并不需要等到前一条消息被Commit才接收后一条消息。
事实上,Leader可以按顺序接收大量消息,最新的一条消息的Offset被记为High Wartermark。而只有被ISR中所有Follower都复制过去的消息才会被Commit,Consumer只能消费被Commit的消息。
由于Follower的复制是严格按顺序的,所以被Commit的消息之前的消息肯定也已经被Commit过。换句话说,High Watermark标记的是Leader所保存的最新消息的offset,而Commit Offset标记的是最新的可被消费的(已同步到ISR中的Follower)消息。
而Leader对数据的接收与Follower对数据的复制是异步进行的,因此会出现Commit Offset与High Watermark存在一定差距的情况。0.8.*版本中replica.lag.max.messages限定了Leader允许的该差距的最大值。
Kafka基于ISR的数据复制方案原理如下图所示。
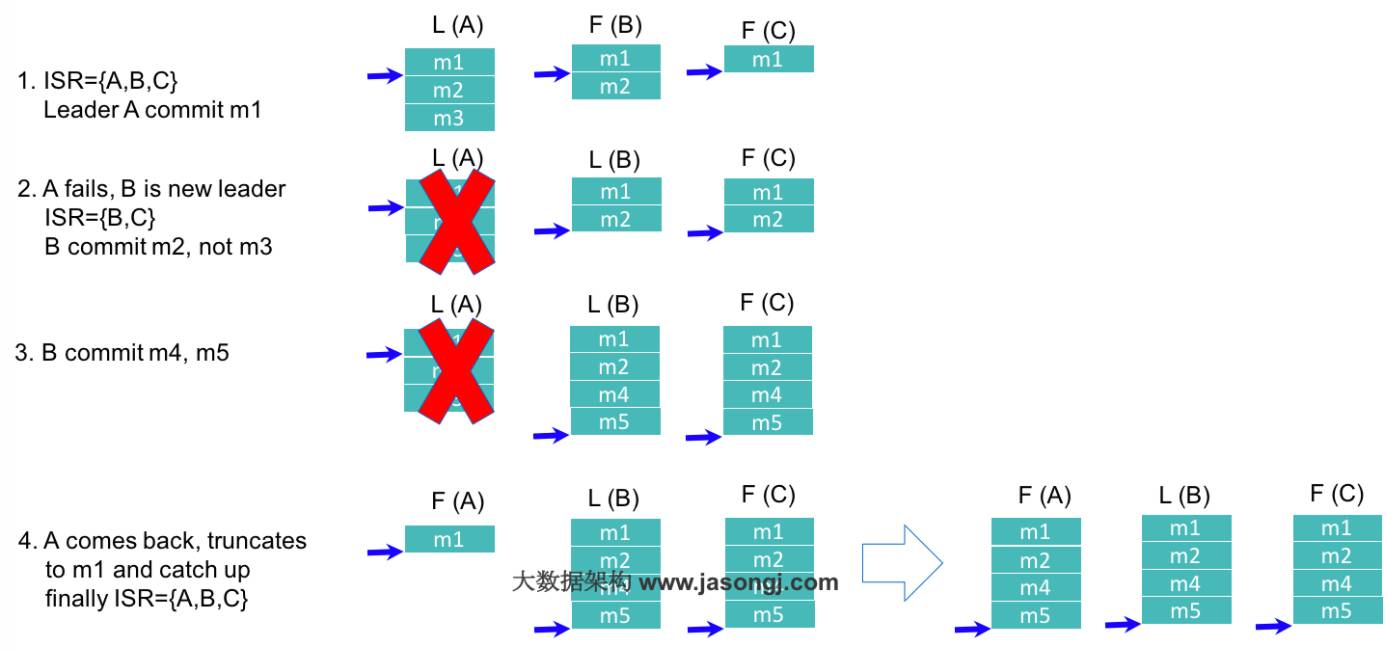
如上图所示,在第一步中,Leader A总共收到3条消息,故其high watermark为3,但由于ISR中的Follower只同步了第1条消息(m1),故只有m1被Commit,也即只有m1可被Consumer消费。此时Follower B与Leader A的差距是1,而Follower C与Leader A的差距是2,均未超过默认的replica.lag.max.messages,故得以保留在ISR中。
在第二步中,由于旧的Leader A宕机,新的Leader B在replica.lag.time.max.ms时间内未收到来自A的Fetch请求,故将A从ISR中移除,此时ISR={B,C}。同时,由于此时新的Leader B中只有2条消息,并未包含m3(m3从未被任何Leader所Commit),所以m3无法被Consumer消费。
第四步中,Follower A恢复正常,它先将宕机前未Commit的所有消息全部删除,然后从最后Commit过的消息的下一条消息开始追赶新的Leader B,直到它“赶上”新的Leader,才被重新加入新的ISR中。
用ISR方案的原因
-
由于Leader可移除不能及时与之同步的Follower,故与同步复制相比可避免最慢的Follower拖慢整体速度,也即ISR提高了系统可用性。
-
ISR中的所有Follower都包含了所有Commit过的消息,而只有Commit过的消息才会被Consumer消费,故从Consumer的角度而言,ISR中的所有Replica都始终处于同步状态,从而与异步复制方案相比提高了数据一致性。
-
ISR可动态调整,极限情况下,可以只包含Leader,极大提高了可容忍的宕机的Follower的数量。与Majority Quorum方案相比,容忍相同个数的节点失败,所要求的总节点数少了近一半。





