正文
:基于 Neoverse V2 核心的 C8g 实例运行 Llama 3 70B 模型时,每秒生成 10 个词元,达到人类可读性上限,提示词编码性能较前代 Graviton3 提升 14%-26%。处理 int4 量化的 Phi-3 模型时,吞吐量提升 2.5 倍,单次推理延迟稳定在 100ms 以内。
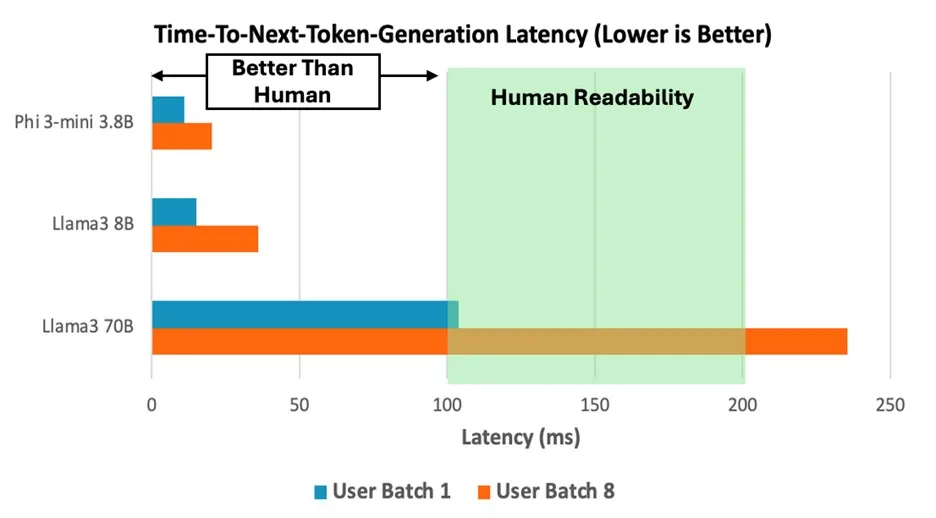
在 C8g.16xlarge 实例上运行 Llama 3 70B、Phi-3-mini 3.8B 和 Llama 3 8B 模型时,下个词元生成时间的性能表现,其中批次大小模拟了一个或多个用户同时调用模型的场景

2.边缘侧:Armv9 边缘 AI 计算平台加速物联网智能化
今年2月,Arm 高级副总裁兼物联网事业部总经理 Paul Williamson 曾表示:“AI 的革新已不再局限于云端。随着世界的互联和智能化水平的日益提升,从智慧城市到工业自动化,在边缘侧处理 AI 工作负载不仅带来显著的优势,其必要性更是不可或缺。专为物联网打造的 Armv9 边缘 AI 计算平台的推出,标志着这一发展趋势迈入了重要的里程碑。”
这里所提到的AI计算平台,是全球首个 Armv9 边缘 AI 计算平台,以全新基于 Armv9 架构的超高能效 Cortex-A320 CPU 和 Ethos-U85 NPU 为核心,专为物联网应用优化,ML 性能较前代提升 8 倍,支持运行超 10 亿参数的端侧 AI 模型。
据悉,该平台已获得包括AWS、西门子和瑞萨电子等在内的多家行业领先企业的支持,推动工业自动化、智能摄像头等领域的进步。
3.端侧:Arm 终端 CSS 提升终端性能
Arm 终端 CSS 囊括最新的 Armv9.2 Cortex CPU 集群和 Arm Immortalis 与 Arm Mali GPU、CoreLink 互连系统 IP,以及采用3nm工艺生产就绪的 CPU 和 GPU 物理实现,能在广泛类别的消费电子设备中实现性能、效率和可扩展性的跨越式提升。
资料显示,Arm Cortex-X925 在 AI 性能方面实现了 41% 的性能提升,可显著提高如 LLM 等设备端生成式 AI 的响应能力。例如在 Meta Llama 3.2 3B 模型部署中,Cortex-X925 CPU 通过优化内核,使提示词处理速度提升 5 倍,词元生成速度达每秒 19.92 个,响应延迟较原生实现缩短 50%。
软硬件协同,释放大模型应用潜力
不仅是硬件方面,Arm 在软件领域的投入也在助力大模型性能的提升与加速落地。Arm 在 2024 年推出 KleidiAI,使 AI 框架开发者们在各种设备上轻松获得 Arm CPU 上的最佳性能,并支持 Neon、SVE2 和 SME2 等关键 Arm 架构功能。作为一套面向 AI 框架开发者的计算内核,KleidiAI 可与 PyTorch、Tensorflow、MediaPipe、Angel 等热门 AI 框架集成,旨在加速 Meta Llama 3、Phi-3、混元大模型等关键模型的性能,为生成式 AI 工作负载带来显著的性能提升。
例如,阿里巴巴通义千问模型通过 KleidiAI 与轻量级深度学习框架 MNN 集成,预填充性能提升 57%,解码性能提升 28%。再比如,Arm 与腾讯合作将 KleidiAI 技术融入腾讯混元自研的 Angel 机器学习框架,为跨操作系统的不同基于 Arm 的设备带来显著的性能提升:混元大模型的预填充部分加速了 100%,而解码器的速度提高了 10%。
结语
当大模型成为数字经济的核心生产力,算力分配范式决定着产业智能化的广度与深度。
Arm 以 Neoverse 计算平台构建云端能效标杆,以边缘 AI 计算平台与终端CSS开启端侧智能,通过架构创新与生态协同,打造 “云边端” 无缝衔接的算力基础设施。这种全栈布局不仅解决了大模型落地的能效与场景适配难题,更构建了开放共赢的技术生态,让算力真正成为普惠性资源。










