正文
nltk
.
corpus
import
gutenberg
>>>
from
nltk
import
FreqDist
# 作图需要 matplotlib(可以从 NLTK 下载页获得)
>>>
import
matplotlib
>>>
import
matplotlib
.
pyplot
as
plt
# 统计 Gutenberg 中每个词例数量
>>>
fd
=
FreqDist
()
>>>
for
text
in
gutenberg
.
fileids
()
:
...
for
word
in
gutenberg
.
words
(
text
)
:
...
fd
.
inc
(
word
)
# 初始化两个空列表来存放词序和词频
>>>
ranks
=
[]
>>>
freqs
=
[]
# 生成每个词例的(词序,词频)点并且将其添加到相应列表中,
# 注意循环中的 fd 会自动排序
>>>
for
rank
,
word
in
enumerate
(
fd
)
:
...
ranks
.
append
(
rank
+
1
)
...
freqs
.
append
(
fd
[
word
])
...
# 在 log-log 图中展示词序和词频的关系
>>>
plt
.
loglog
(
ranks
,
freqs
)
>>>
plt
.
xlabel
(
’
frequency
(
f
)
’
,
fontsize
=
14
,
fontweight
=
’
bold
’
)
>>>
plt
.
ylabel
(
’
rank
(
r
)
’
,
fontsize
=
14
,
fontweight
=
’
bold
’
)
>>>
plt
.
grid
(
True
)
>>>
plt
.
show
()
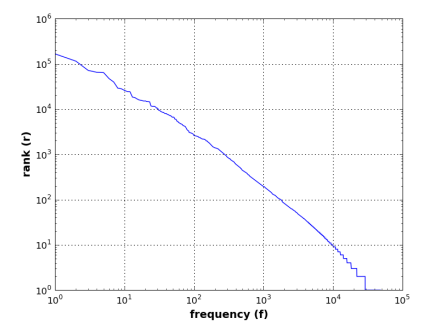
图 1: 齐普夫定律在古登堡语料库中适用吗?
3.4 任务 2:预测单词
现在我们已经探索过语料库了,让我们定义一个任务,能够用上之前探索的结果。
任务:训练和创建一个单词预测器,例如:给定一个训练过语料库,写一个能够预测给定单词的一下个单词的程序。使用这个预测器随机生成一个 20 个词的句子。
要创建单词预测器,我们首先要在训练过的语料库中计算两个词的顺序分布,例如,我们需要累加给定单词接下来这个单词的出现次数。一旦我们计算出了分布,我们就可以通过输入一个单词,得到它在语料库中所有可能出现的下一个单词列表,并且可以从列表中随机输出一个单词。为了随机生成一个 20 个单词的句子,我只需要给定一个初始单词,利用预测器来预测下一个单词,然后重复操作指导直到句子满 20 个词。清单 2 描述了怎么利用 NLTK 提供的模块来简单实现。我们利用简奥斯丁的 Persuasion 作为训练语料库。
清单 2:利用 NLTK 预测单词
>>>
from
nltk
.
corpus
import
gutenberg
>>>
from
nltk
import
ConditionalFreqDist
>>>
from
random
import
choice
# 分布实例化
>>>
cfd
=
ConditionalFreqDist
()
# 对于每个实例,统计给定词的下一个词数量
>>>
prev_word
=
None
>>>
for
word
in
gutenberg
.
words
(
’
austen
-
persuasion
.
txt
’
)
:
...
cfd
[
prev_word
].
inc
(




