正文
我现在希望获得一个合理的,并且能够最大程度的反映面积与房价关系的规律。于是我调查了周边与我房型类似的一些房子,获得一组数据。这组数据中包含了大大小小房子的面积与价格,如果我能从这组数据中找出面积与价格的规律,那么我就可以得出房子的价格。
对规律的寻找很简单,拟合出一条直线,让它“穿过”所有的点,并且与各个点的距离尽可能的小。
通过这条直线,我获得了一个能够最佳反映房价与面积规律的规律。这条直线同时也是一个下式所表明的函数:
房价 = 面积 * a + b
上述中的a、b都是直线的参数。获得这些参数以后,我就可以计算出房子的价格。
假设a = 0.75,b = 50,则房价 = 100 * 0.75 + 50 = 125万。这个结果与我前面所列的100万,120万,140万都不一样。由于这条直线综合考虑了大部分的情况,因此从“统计”意义上来说,这是一个最合理的预测。
在求解过程中透露出了两个信息:
1.房价模型是根据拟合的函数类型决定的。如果是直线,那么拟合出的就是直线方程。如果是其他类型的线,例如抛物线,那么拟合出的就是抛物线方程。机器学习有众多算法,一些强力算法可以拟合出复杂的非线性模型,用来反映一些不是直线所能表达的情况。
2.如果我的数据越多,我的模型就越能够考虑到越多的情况,由此对于新情况的预测效果可能就越好。这是机器学习界“数据为王”思想的一个体现。一般来说(不是绝对),数据越多,最后机器学习生成的模型预测的效果越好。
通过我拟合直线的过程,我们可以对机器学习过程做一个完整的回顾。首先,我们需要在计算机中存储历史的数据。接着,我们将这些 数据通过机器学习算法进行处理,这个过程在机器学习中叫做“训练”,处理的结果可以被我们用来对新的数据进行预测,这个结果一般称之为“模型”。对新数据的预测过程在机器学习中叫做“预测”。“训练”与“预测”是机器学习的两个过程,“模型”则是过程的中间输出结果,“训练”产生“模型”,“模型”指导 “预测”。
让我们把机器学习的过程与人类对历史经验归纳的过程做个比对。
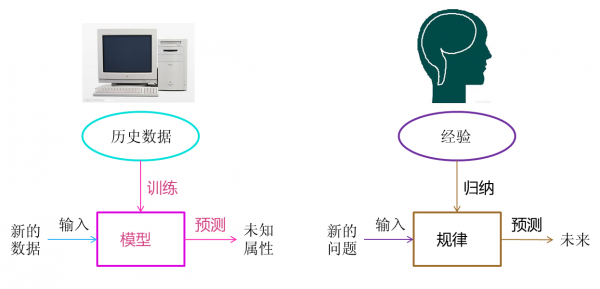
图5 机器学习与人类思考的类比
人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作。
机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。
这也可以联想到人类为什么要学习历史,历史实际上是人类过往经验的总结。有句话说得很好,“历史往往不一样,但历史总是惊人的相似”。通过学习历史,我们从历史中归纳出人生与国家的规律,从而指导我们的下一步工作,这是具有莫大价值的。当代一些人忽视了历史的本来价值,而是把其作为一种宣扬功绩的手段,这其实是对历史真实价值的一种误用。
3.机器学习的范围
上文虽然说明了机器学习是什么,但是并没有给出机器学习的范围。
其实,机器学习跟模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理等领域有着很深的联系。
从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的,同时,机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。因此,一般说数据挖掘时,可以等同于说机器学习。同时,我们平常所说的机器学习应用,应该是通用的,不仅仅局限在结构化数据,还有图像,音频等应用。
在这节对机器学习这些相关领域的介绍有助于我们理清机器学习的应用场景与研究范围,更好的理解后面的算法与应用层次。
下图是机器学习所牵扯的一些相关范围的学科与研究领域。
图6 机器学习与相关学科
模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。在著名的《Pattern Recognition And Machine Learning》这本书中,Christopher M. Bishop在开头是这样说的“模式识别源自工业界,而机器学习来自于计算机学科。不过,它们中的活动可以被视为同一个领域的两个方面,同时在过去的10年间,它们都有了长足的发展”。
数据挖掘=机器学习+数据库。这几年数据挖掘的概念实在是太耳熟能详。几乎等同于炒作。但凡说数据挖掘都会吹嘘数据挖掘如何如何,例如从数据中挖出金子,以及将废弃的数据转化为价值等等。但是,我尽管可能会挖出金子,但我也可能挖的是“石头”啊。
这个说法的意思是,数据挖掘仅仅是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每个数据都能挖掘出金子的,所以不要神话它。一个系统绝对不会因为上了一个数据挖掘模块就变得无所不能(这是IBM最喜欢吹嘘的),恰恰相反,一个拥有数据挖掘思维的人员才是关键,而且他还必须对数据有深刻的认识,这样才可能从数据中导出模式指引业务的改善。大部分数据挖掘中的算法是机器学习的算法在数据库中的优化。
统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。
计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深度学习的发展,大大促进了计算机图像识别的效果,因此未来计算机视觉界的发展前景不可估量。
语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,一般会结合自然语言处理的相关技术。目前的相关应用有苹果的语音助手siri等。
自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。
作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向。按照百度机器学习专家余凯的说法“听与看,说白了就是阿猫和阿狗都会的,而只有语言才是人类独有的”。
如何利用机器学习技术进行自然语言的的深度理解,一直是工业和学术界关注的焦点。
可以看出机器学习在众多领域的外延和应用。机器学习技术的发展促使了很多智能领域的进步,改善着我们的生活。
4.机器学习的方法
通过上节的介绍我们知晓了机器学习的大致范围,那么机器学习里面究竟有多少经典的算法呢?在这个部分我会简要介绍一下机器学习中的经典代表方法。这部分介绍的重点是这些方法内涵的思想,数学与实践细节不会在这讨论。
在大部分机器学习课程中,回归算法都是介绍的第一个算法。原因有两个:一.回归算法比较简单,介绍它可以让人平滑地从统计学迁移到机器学习中。二.回归算法是后面若干强大算法的基石,如果不理解回归算法,无法学习那些强大的算法。回归算法有两个重要的子类:即线性回归和逻辑回归。
线性回归就是我们前面说过的房价求解问题。如何拟合出一条直线最佳匹配我所有的数据?一般使用“最小二乘法”来求解。“最小二乘法”的思想是这样的,假设我们拟合出的直线代表数据的真实值,而观测到的数据代表拥有误差的值。为了尽可能减小误差的影响,需要求解一条直线使所有误差的平方和最小。最小二乘法将最优问题转化为求函数极值问题。函数极值在数学上我们一般会采用求导数为0的方法。但这种做法并不适合计算机,可能求解不出来,也可能计算量太大。
计算机科学界专门有一个学科叫“数值计算”,专门用来提升计算机进行各类计算时的准确性和效率问题。例如,著名的“梯度下降”以及“牛顿法”就是数值计算中的经典算法,也非常适合来处理求解函数极值的问题。梯度下降法是解决回归模型中最简单且有效的方法之一。从严格意义上来说,由于后文中的神经网络和推荐算法中都有线性回归的因子,因此梯度下降法在后面的算法实现中也有应用。





