正文
peewee
import
Model, CharField, ForeignKeyField
class
Category
(Model)
:
name = CharField()
parent = ForeignKeyField(
'self'
,
related_name=
'children'
,
null=
True
)
每个Filed都有一些参数可以设置:
更多
关于Sqlite多说几句(其他数据库可不可以这样用,不清楚,没试过)
一下是关于commit的问题,默认Sqlite是自动commit的,问题就是巨慢,因此连接数据库时可以指定autocommit为False,但是就需要用一下三种方式手动进行commit,后边还有一个atomic()功能与transaction()一致
db = SqliteDatabase('my_app.db', autocommit=False)
db.begin()
User.create(username='charlie')
db.commit()
with db.transaction():
User.create(username='huey')
@db.transaction()
def create_user(username):
User.create(username=username)
言归正传,开始举例
基本使用方法
我使用Sqlite数据库来做展示,Sqlite可以直接导入导出CSV文件,官方也给出了解决方法 【详情】
然而,我还是决定自己处理,毕竟有很多数据需要修饰什么的
第一次接触这个模块是从《Python高效开发实战Django Tornado Flask Twisted》(刘长龙著),对它的第一印象就是貌似很简单(?),因此,就直接沿着这个模块用下来了。
以Human protein atlas下载到的细胞系表达量数据为例,简单说明一些用法
下载到一个CSV文件,总大小51.3M
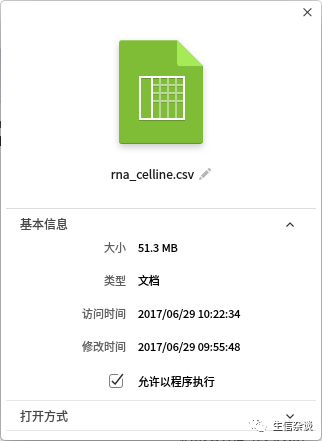
一共包含五列数据,分别是ensembl_id,gene_name, tissue, value,value_type
1.
连接数据库
第一步,先指定一个数据库,新建各种所需的model
import os
from peewee import Model
from peewee import SqliteDatabase
from peewee import CharField, FloatField
db = SqliteDatabase(os.path.join(
os.path.dirname(__file__),
'expression_value.db'),
autocommit=True)





