P
(
Y
|
X
)
L
(
Y
,
P
(
Y
|
X
)
)
=
−
log
P
(
Y
|
X
)
刚刚说到,取对数是为了方便计算极大似然估计,因为在MLE中,直接求导比较困难,所以通常都是先取对数再求导找极值点。
损失函数L(Y, P(Y|X))表达的是样本X在分类Y的情况下,使概率P(Y|X)达到最大值(换言之,
就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大
)。
因为log函数是单调递增的,所以logP(Y|X)也会达到最大值,因此在前面加上负号之后,最大化P(Y|X)就等价于最小化L了。
逻辑回归的P(Y=y|x)表达式如下(为了将类别标签y统一为1和0,下面将表达式分开表示):

将它带入到上式,通过推导可以得到logistic的损失函数表达式,如下:

逻辑回归最后得到的目标式子如下:
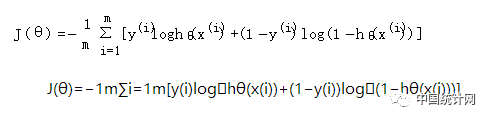
上面是针对二分类而言的。
这里需要解释一下:
之所以有人认为逻辑回归是平方损失,是因为在使用梯度下降来求最优解的时候,它的迭代式子与平方损失求导后的式子非常相似,从而给人一种直观上的错觉。
这里有个PDF可以参考一下:Lecture 6: logistic regression.pdf.
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。
在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?
其实这里隐藏了一个小知识点,就是
中心极限定理
,可以参考【central limit theorem】),最后通过极大似然估计(MLE)可以推导出最小二乘式子。
最小二乘的基本原则是:
最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小
。
换言之,OLS是基于距离的,而这个距离就是我们用的最多的欧几里得距离。




