正文
浏览器漏洞类型
第一类漏洞是信息泄漏漏洞,有以下几种场景:
-
比如老的IE浏览器可以用 JS 检测是否存在某文件。
这样会泄漏用户是否安装了杀毒软件,以便进行下一步操作。
-
有些信息泄漏漏洞会泄漏内存的信息,
攻击者可能使用泄漏的信息来绕过操作系统的保护机制,
比如:ASLR、DEP 等等。
-
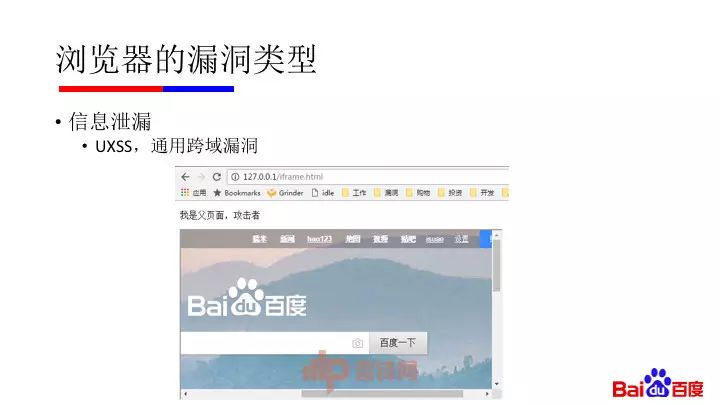
还有一类信息泄漏漏洞:UXSS,通用跨域漏洞。
这种跨越域隔离策略的漏洞,可以在后台偷偷地打开其它域的网页,把你在其它网站上的数据偷走。
第二类漏洞是内存破坏漏洞:
内存破坏漏洞又可以细分为释放后重用漏洞(UAF),越界读写漏洞,类型混淆漏洞。
越界读写漏洞比较神,他也能用来泄漏内存信息,所以越界读写漏洞非常好利用。
第三类漏洞,是国产浏览器的一些神漏洞,特权域 XSS+特权域 API:
比如搜狗浏览器浏览网页可下载任意文件到任意位置,重启之后,电脑可能被完全控制。百度浏览器可静默安装插件,且存在目录穿越漏洞。解压缩到启动目录,重启之后,电脑被完全控制。
利用这些浏览器漏洞可以做什么可怕的事情呢?
想像一下:
打开一个网页,完全控制你的电脑,APT攻击;
打开一个网页,完全控制你的手机,监听通话短信;
打开一个网页,越狱你的游戏机,玩盗版游戏;
打开一个网页,偷走你京东帐号、控制微博帐号…….
我们曾经抓到一个打 DDoS 的嫌疑人,他控制了200个肉鸡,接单打 DDoS。这200个肉鸡每天给他创造2000块的收入,如果有一套组合的浏览器0day+一个大站 Webshell,一天上千的肉鸡非常简单,日入万元不是梦,哈哈。。。
浏览器漏洞挖掘方法
那怎么挖掘浏览器漏洞呢?
第一种方法,人工
像Chrome 和 Webkit 这些是开源的,通过理解代码逻辑来找 Bug。比如 marius.mlynski 读 Chrome 代码发现数十个 UXSS 漏洞,每个漏洞Google奖励 7500 美元。
国产浏览器的漏洞大多是人工测试出来的,用自己的经验,逆向分析,手工测试。
第二种方法,自动化 Fuzz
用机器代替人来自动化挖漏洞。
有一些开源的框架可以学习:Grinder、Fileja、funfzz等。我们来看一下一个Fuzz框架是怎样实现的。
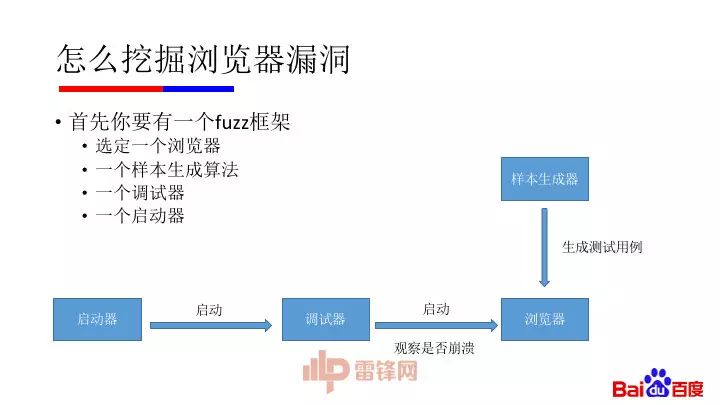
简单地说就是控制浏览器去加载你生成的测试样本,捕捉导致浏览器崩溃的样本,传回服务器作下一步分析。今天给大家分享一个最简单的Fuzz框架,一行代码,启动调试器打开样本生成器网页:
windbg -c “!py chrome_dbg_test.py” -o “C:\Program Files\Google\Chrome\Application\chrome.exe --js-flags=”--expose-gc" --no-sandbox --disable-seccomp-sandbox --allow-file-access-from-files --force-renderer-accessibility http://127.0.0.1/fuzzer.php
解释上面的命令:
使用windbg调试启动chrome打开样本生成器http://127.0.0.1/fuzzer.php
http://127.0.0.1/fuzzer.php生成测试样本并切换样本。
一个最简单调试器,十几行代码,pydbg 是 windbg 的一个插件,使用它可以编程控制 windbg。
比如用这段代码,监控调试进程产生的调试事件:
while True:
exc = e(".lastevent")
print exc
if exc.find("Exit process") > 0:
os.system("taskkill /F /IM windbg.exe")
观察windbg收到的调试事件,如果是退出进程事件,那么把windbg退出(同时chrome进程也退出了)。同理,如果windbg收到的调试事件是读写内存异常,那就是一个有效崩溃。
这时候你只需要执行windbg命令r,k,把结果传回服务器就完成了一个崩溃信息的收集了。
要想挖掘浏览器漏洞,推荐大家去分析以往浏览器的漏洞,收集一些POC,这样能更好地理解浏览器漏洞形成的原因以及调试分析方法。来看一个典型IE漏洞的POC:

所以我们的目标是怎样去生成有效的、复杂的、测试用例,让浏览器崩溃。
我们需要去构建 fuzz 生成算法用的字典,通常可以写爬虫到 MSDN、MDN、W3C 去抓取,还有可以用 IDA 分析 mshtml 找隐藏的属性键值,还可以看浏览器源码的头文件。我们需要去构建全面的字典,去覆盖浏览器的各个特性。

网上也有些自动构建字典的方法,可以参考:
var elements = [“abbr”, “acronym”, “address”, “article”, “aside”, “b”……];
for (var i = 0; i





