正文
事实上,从分词、词性、语法解析、信息抽取等基础模块,到自然语言生成、机器翻译、对话管理、知识问答等高层的 NLP 领域,几乎都可以应用以 CNN、RNN 为代表的深度学习模型,且确实能够取得不错的效果。深度学习模型有效降低了语言模型输入特征的维度,降低了输入层的复杂性。另外,深度学习模型具有其他浅层模型不能比拟的灵活性。深度学习模型更复杂,能够对数据进行更精准的建模,从而增强实验效果。
深度学习模型可以将文本中的词高效地表示为分布式连续向量(word2vec),将词语、文本由词空间映射到语义空间,这样的语义表示可以捕获重要的句法和语义信息,一定程度上缓解了词面不匹配、数据稀疏、语义鸿沟等问题。Word2vec 的应用可以使许多自然语言处理任务取得突出的表现。Word2vec 虽然可以通过神经网络训练大规模的语料实现,但仍面临着 out of vocabulary 的现实。Bahdanau 等人利用 LSTM 模型结合定义知识语料,解决传统 word embedding 模型中的 out of vocabulary 问题。(框架流程见图 1,具体见 https://arxiv.org/abs/1706.00286)
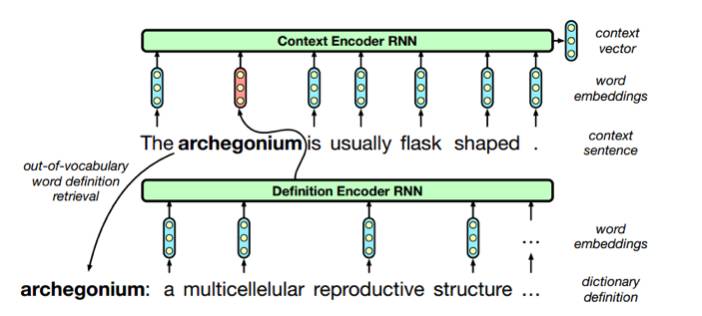
图 1:利用 RNN 解决 Word2Vec 中 out of vocabulary 问题实例
中文不同于英文自然分词,中文分词是文本处理的一个基础步骤,也是自然语言处理的基础模块。分词性能的好坏直接影响比如词性、句法树等其他模块的性能。利用深度学习实现的字嵌入+Bi-LSTM+CRF 中文分词器,不需要构造额外手工特征。使用人民日报的 80 万语料训练实现,按照字符正确率评估标准能达到 98% 的准确率。其本质上是一个序列标注模型,模型参考的论文是:http://www.aclweb.org/anthology/N16-1030,整个神经网络的主要框架如图 2 所示。有感兴趣的朋友可以去看看,具体实现已在 github 开源 https://github.com/koth/kcws。
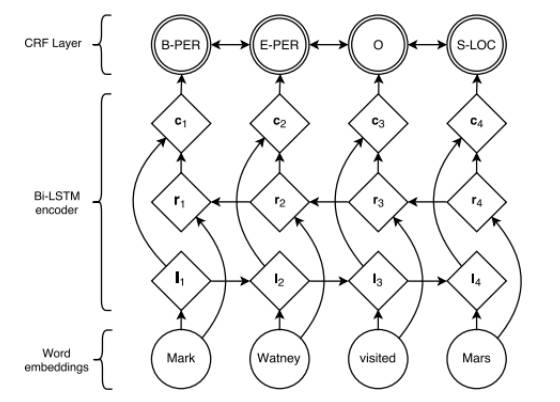
图 2:Word Embedding+Bi-LSTM+CRF 主要框架示意图
语法解析可以获得句子的语法结构,例如,哪些单词组合在一起(形成「短语」),哪些单词是动词的主题或对象。Syntactic Parsing 明确标出了词与词之间的短语结构,隐含了词与词之间的关系。而 Dependency Parser 则明确表示出了词与词之间的关系。利用神经网络模型解析句子的语法结构的实现可以参考 http://www.petrovi.de/data/acl15.pdf 以及斯坦福的 http://cs.stanford.edu/~danqi/papers/emnlp2014.pdf。除解析文本之外,Richard Socher 等人利用 CNN 模型实现了解析图片的功能(Parsing Natural Scenes and Natural Language with Recursive Neural Networks)。




