正文
在可以构建AI之前,我必须首先编写代码将使用不同语言和协议的系统连接起来。我们的电灯、恒温器和门使用的是Crestron系统,音乐流媒体Spotify搭配的是Sonos音箱,还有一台三星电视机,以及为Max准备的Nest Cam摄像头,当然,我的工作室连接的是Facebook的系统。为了能够通过我的电脑发布诸如开灯、播放歌曲之类的指令,我不得不对其中一些系统的API进行逆向开发。
此外,大多数的电器甚至都不能连接到互联网。虽然通过支持连接到互联网、可远程控制的电源开关能够控制其中的一些电器,但是这还远远不够。比如,如果你希望烤面包机能在接通电源的时候自动开始烤面包,但你很难找到能够让你在断电的情况下将面包按下去的烤面包机。最终,我最终找到了一个1950年代的古董烤面包机,然后把它插在了智能插座上。同样的,要想连接Beast(扎克伯格的宠物狗)的自动投食器,则需要涉及到硬件改造工作。
对于Jarvis这样的助手来说,要想能够帮助更多的人控制家里的一切,我们需要将更多的设备连接起来。而业界也需要开发通用的API和标准,让设备与设备之间能相互通信。
自然语言
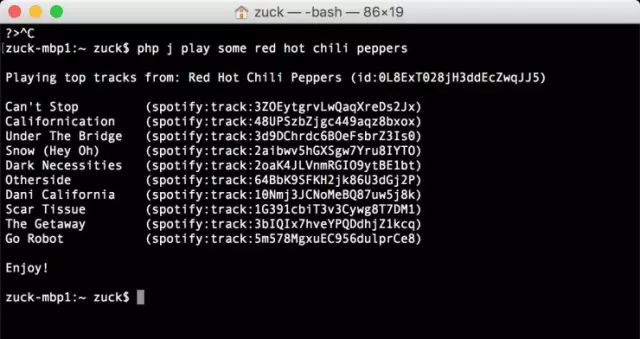
当我写完能够让我的电脑控制我家的代码之后,下一步就是让我和电脑之间的沟通变得像日常对话那样自然。这里的过程分为两步:
首先实现通过文本信息来对话,然后增加将语音转录成文本的功能。
从寻找关键词开始,比如通过“卧室”、“灯”、“开”这几个关键字,它可以知道我是在告诉它把卧室的灯打开。很快,我就发现它需要理解同义词,“family room”和“living room”在我们家里指的是同一个房间,这就需要建立一种能教它学习新的词汇和概念的方法。
理解语境对任何AI来说都非常重要。例如,当我告诉它打开我办公室里的空调时,这和Priscilla说同样的话的意思完全不同。这造成了一些混乱。比如,当你在没有指定房间的情况下让它把灯调暗一点或者播放一首歌的时候,如果它不知道你在哪个房间,那么很可能打开Max房间里的播放器,然后在我们希望她能打个小盹的时候把她吵醒。
音乐是一个更有趣也更复杂的自然语言领域。对于一个识别关键字的系统来说,有太多的艺术家、歌曲、专辑,因此你可以问的东西也非常宽泛。电灯只能关闭或打开,然而当你说“play XX(播放XX歌曲)”时,即使细微的差别也可能意味很多不同的意思。比如,“play someone like you(播放歌曲someone like you)”,“play someone like Adele(播放和Adele风格相似的歌手的歌曲)”,“play some Adele(播放Adele的歌)”,这些听起来很相似,但其实是完全不同的指令。第一个指令是播放一首特定的歌曲,第二个是推荐一位歌手,第三个则是创建一个Adele最好听的歌曲播放列表。不过,
通过一个有反馈的系统,AI可以学习到这些差异。
一个AI系统对语境的了解越多,就能越好地处理开放式问题。我经常只对Jarvis说“play me some music(播放音乐)”,它会查看我过去的听歌习惯,大部分情况下它播放的都是我想听的歌。如果它播的歌不符合当时的气氛,我可以直接告诉它,比如,“这不是舒缓的,播放一些舒缓的音乐”,它就会学习到那首歌的分类,并立即做出调整。而且它也知道是我在跟它说话,还是Priscilla(扎克伯格的妻子)在跟它说话,这样它就可以根据我们的口味推荐不同的歌曲。相比非常具体的指令,我发现我们更常使用开放式的命令。就我所知,
目前还没有哪个商业化的产品在做这个,这应该是一个巨大的机会。
视觉和面部识别




