正文
假如有这么一张表(表名:sanguo):
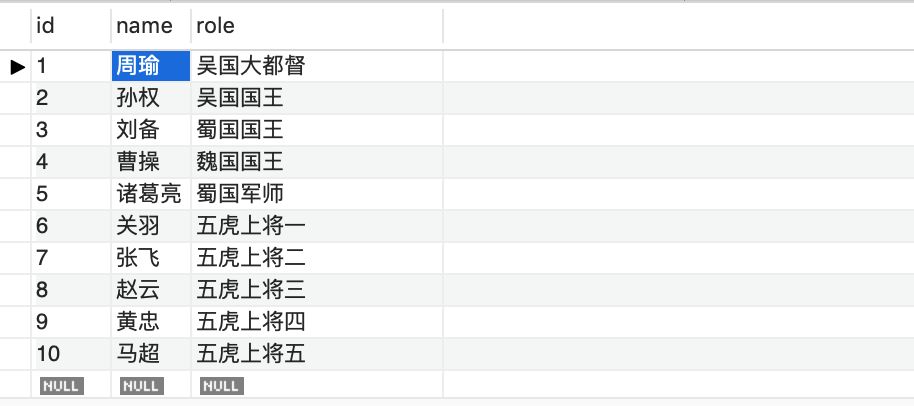
现在对name字段建立哈希索引:

注意字段值所对应的数组下标是哈希算法随机算出来的,所以可能出现
哈希冲突
。那么对于这样一个索引结构,现在来执行下面的sql语句:
select*fromsanguowherename='周瑜'
可以直接对‘周瑜’按哈希算法算出来一个数组下标,然后可以直接从数据中取出数据并拿到锁对应那一行数据的地址,进而查询那一行数据。
那么如果现在执行下面的sql语句:
select*fromsanguowherename>'周瑜'
则无能为力,因为哈希表的特点就是
可以快速的精确查询,但是不支持范围查询
。
如果用完全平衡二叉树呢?
还是上面的表数据用完全平衡二叉树表示如下图(为了简单,数据对应的地址就不画在图中了。):

图中的每一个节点实际上应该有四部分:
-
左指针,指向左子树
-
键值
-
键值所对应的数据的存储地址
-
右指针,指向右子树
另外需要提醒的是,二叉树是有顺序的,简单的说就是“左边的小于右边的”假如我们现在来查找‘周瑜’,需要找2次(第一次曹操,第二次周瑜),比哈希表要多一次。而且由于完全平衡二叉树是有序的,所以也是支持范围查找的。
如果用B树呢?
还是上面的表数据用B树表示如下图(为了简单,数据对应的地址就不画在图中了。):

可以发现同样的元素,B树的表示要比完全平衡二叉树要“矮”,原因在于B树中的一个节点可以存储多个元素。
如果用B+树呢?
还是上面的表数据用B+树表示如下图(为了简单,数据对应的地址就不画在图中了。):






