正文
虽然已有相应的解决方案去加快 GPU 与 CPU 之间的信息流通,但仍旧存在延时等问题。
目前比较前沿的加速 CPU 与 GPU 信息交方案是 IBM 与 NVIDIA 联合研制的 NVlink 信息交换通道。我们知道,GPU 和 CPU 间的数据传输速度都是一项技术瓶颈,因为 GPU 的显存能够快速而少量的读写数据,而 CPU 使用内存读写则大量而慢速,因此,CPU 的传输带宽大于 GPU。NVlink 通过调整相应架构,使得 GPU 和 CPU 间的传输速度获得巨大的提升。

其实 IBM 早在几年前便注意到了这种趋势,随后它们与 NVIDIA 合作,去加快新数据中心工作负载的处理速度。经过四年的研发,POWER8 服务器联合了 NVIDIA 的 Tesla P100 GPU 和 NVlink 互联技术,实现了更高的数据性能分析和深度学习能力提升。据测试资料显示:IBM 和 NVIDIA 技术如此紧密的结合使得数据流动速度比使用 PCIE 快了 5 倍。
NVlink 除了可实现 GPU-CPU 节点内部的高速互联,同时还能在 GPU-GPU 甚至 CPU-CPU 之间形成高速互联。
雅捷信息首席数据官谢军向雷锋网 (公众号:雷锋网) 透露,由于他们服务的客户通常是大中型银行,对计算量要求巨大,因此雅捷信息的新品 DataTurbines 背后采用的是 GPU 集群,这个时候集群中 GPU 与 GPU 之间的高速互联就非常关键。当然,雅捷信息的数据库也并非完全在 GPU 中处理,也有一小部分会放在 CPU 中,具体会根据客户的成本以及数据量等问题来灵活安排。
为了让 GPU 集群以及 CPU-GPU 之间通信顺畅,雅捷信息选择与 IBM 进行深入合作。IBM 大中华区硬件系统部服务器解决方案副总裁施东峰向雷锋网介绍到,与雅捷信息的合作主要体现在两方面,在技术层面 IBM 为雅捷信息的 GPU 数据库提供 GPU-GPU 以及 GPU-CPU 的 NVlink 通道机器 Minsky。在市场方面,IBM 借助雅捷信息的银行客户,向银行推广包含 GPU 数据库的一体机。
这个一体机本质上是 IBM 提供的认知计算平台,其中 GPU 数据库也归类在认知计算平台中。施东峰继续讲到:IBM 接触的银行客户有两种,一种是对方只要打包好的、直接能够使用的产品,他们只需知道这个引擎如何使用即可,另外一种客户则要是想要自己买机器、做数据库、做算法,自己搭建
人工智能
引擎。
IBM 主要服务于前者,以一体机的形态把相关的
人工智能技术
以及 GPU 数据库进行整合,从而做成企业级直接使用的、没有很多指令集、直接连接的产品。
GPU 数据库商业化应用案例
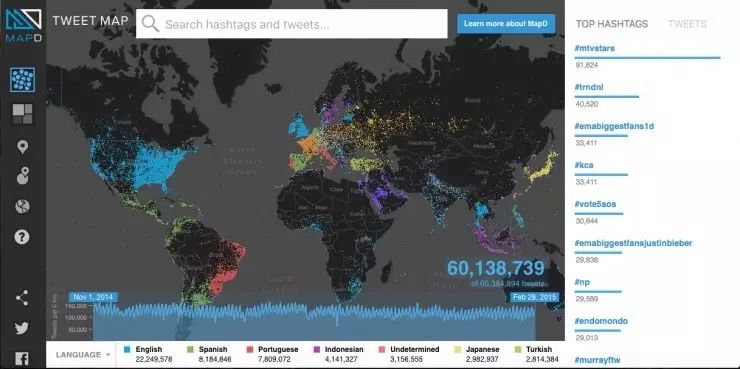
目前从公开资料显示,已有 GPU 数据库产品在海外市场使用,如 Kinetica、BlazingDB 等。其中最具代表性的就是文章开头提到的哈佛学生 Todd Mostak,他已成立了公司运营相关商业化产品 MapD。在 MapD 系统中,每个 GPU 都有自己的缓冲池,利用高速缓存机制将最常访问的数据直接存储在 GPU 一侧,在数据库需要反复查询同一个数据点时,MapD 就可以直接从 GPU 一侧的高带宽存储器中直接访问数据,而不是从 CPU 或硬盘。
通过这种机制,MapD 可以提供相比传统数据库管理系统快两到三个数量级的性能。