正文
3.1 输入层
输入层需要预处理,输入固定维度的数据。所以图片需先预处理再传入输入层。作者使用 OpenCV(计算机视觉库)做图像面部识别。OpenCV 的 haar-cascade_frontalface_default.xml 文件包含预训练的过滤器,使用 Adaboost 算法能快速找到面部并裁剪。
使用 cv2.cvtColor 函数将裁剪面部图片转化为灰度图,并使用 cv2.resize 改变图片大小为 48x48 像素。处理完的面部图片,相比于原始的(3,48,48)三色 RGB 格式“瘦身”不少。同时也确保传入输入层的图片是(1,48,48)的 numpy 数组。
3.2 卷积层
numpy 数组传入 Convolution2D 层,指定过滤层的数量作为超参数。过滤层(比如,核函数)是随机生成权重。每个过滤层,(3,3)的感受野,采用权值共享与原图像卷积生成 feature map。
卷积层生成的 feature map 代表像素值的强度。例如,图5,通过过滤层1 和原始图像卷积生成一个 feature map,其它过滤层紧接着进行卷积操作生成一系列 feature map。
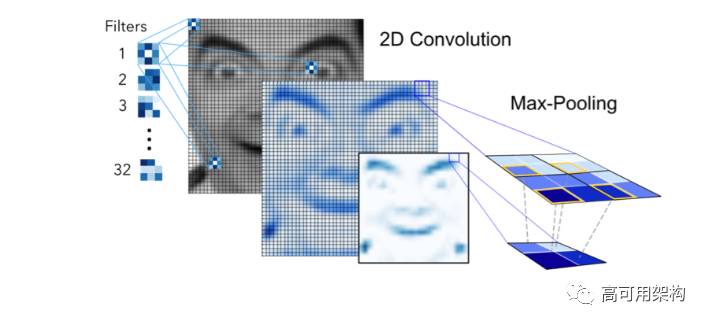
图 5. Convolution and 1st max-pooling used in the network
池化(Pooling)是一种降低维度的技术,常用于一个或者多个卷积层之后。池化操作是构建 CNN 的重要步骤,因为增加的多个卷积层会极大的影响计算时间。本文使用流行的池化方法 MaxPooling2D,其使用(2,2)窗口作用于 feature map 求的最大像素值。池化后图像降低 4 个维度。
3.3 稠密层
稠密层(比如,全联接层)是模仿人脑传输神经元的方式。它输入大量输入特征和变换特征,通过联接层与训练权重相连。
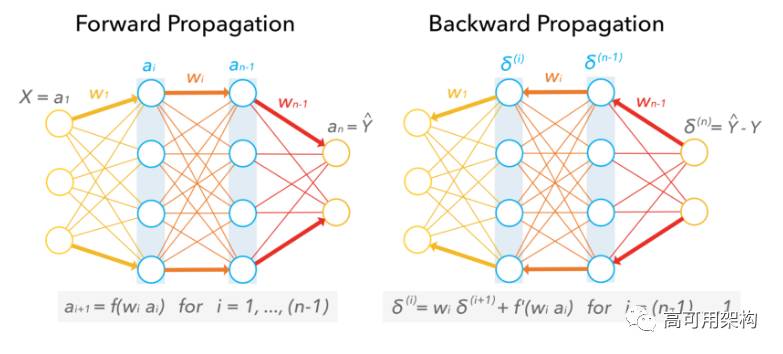
图 6. Neural network during training: Forward propagation (left) to Backward propagation (right).
模型训练时权重前向传播,而误差是反向传播。反向传播起始与预测值和实际值的差值,计算所需的权重调整大小反向传回到每层。采用超参数调优手段(比如,学习率和网络密度)控制训练速度和架构的复杂度。随着灌入更多的训练数据,神经网络能够使得误差最小化。
一般,神经网络层/节点数越多,越能捕捉到足够的信号。但是,也会造成算法模型训练过拟合。应用 dropout 可以防止训练模型过拟合。Dropout 随机选择部分节点(通常,占总节点数的百分比不超过 50%),并将其权重置为 0。该方法能有效的控制模型对噪声对敏感度,同时也保留架构的复杂度。
3.4 输出层
本文的输出层使用 softmax 激励函数代替 sigmoid 函数,将输出每类表情的概率。
因此,本文的算法模型能显示出人脸表情组成的详细组成概率。随后会发现没必要将人类表情表示为单个表情。本文采用的是混合表情来精确表示特定情感
注意,没有特定的公式能建立一个神经网络保证对各种场景都有效。不同的问题需要不同的模型架构,产生期待的验证准确度。这也是为什么说神经网络是个“黒盒算法”。但是也不要太气馁,模型训练的时间会让你找到最佳模型,获得最大价值。
3.5 小结
刚开始创建了一个简单的 CNN 深度学习模型,包括一个输入层,三个卷积层和一个输出层。事实证明,简单的算法模型效果比较差。准确度 0.1500 意味着仅仅是随机猜测的结果(1/6)。简单的网络结构导致不能有效的判别面部表情,那只能说明要“深挖”。。。










