正文
其次是安全
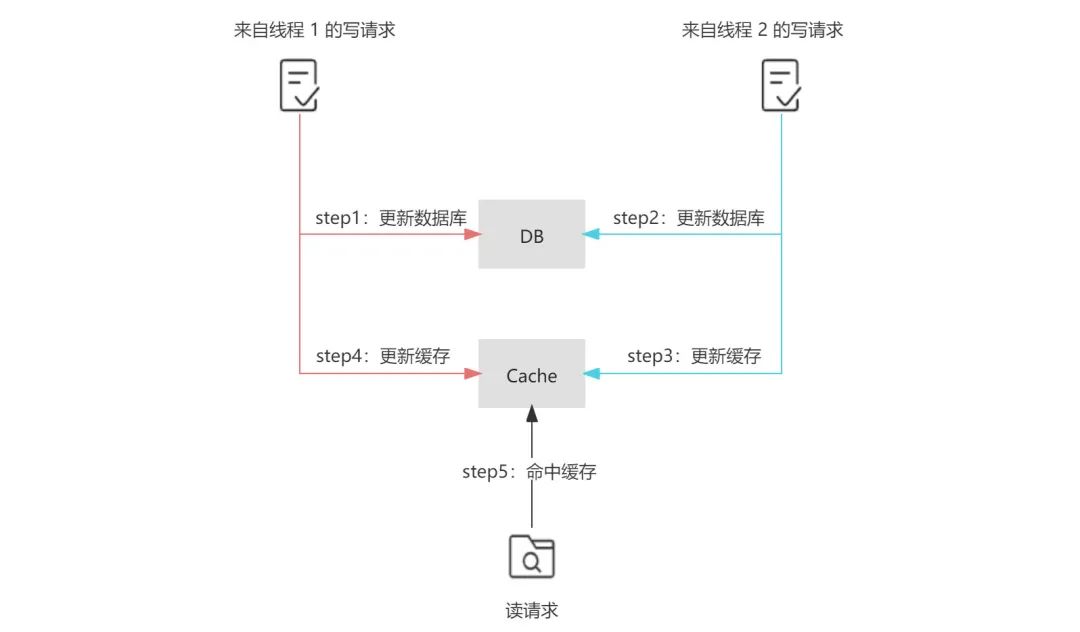
,在并发场景下,在写请求中更新缓存可能会引发数据的不一致问题。参考下面的图示,若存在两个来自不同线程的写请求,首先来自线程 1 的写请求更新了数据库(step 1),接着来自线程 2 的写请求再次更新了数据库(step 3),但由于网络延迟等原因,线程 1 可能会晚于线程 2 更新缓存(step 4 晚于 step 3),那么这样便会导致最终写入数据库的结果是来自线程 2 的新值,写入缓存的结果是来自线程 1 的旧值,即缓存落后于数据库,此时再有读请求命中缓存(step 5),读取到的便是旧值。
2、为什么先更新数据库,而不是先删除缓存?
另外,有读者也会对更新数据库和删除缓存的时序产生疑问,那么为什么不先删除缓存,再更新数据库呢?在单线程下,这种方案看似具有一定合理性,这种合理性体现在删除缓存成功。
但更新数据库失败的场景下,尽管缓存被删除了,下次读操作时,仍能将正确的数据写回缓存,相对于 Cache-Aside 中更新数据库成功,删除缓存失败的场景来说,先删除缓存的方案似乎更合理一些。那么,先删除缓存有什么问题呢?
问题仍然出现在并发场景下,首先来自线程 1 的写请求删除了缓存(step 1),接着来自线程 2 的读请求由于缓存的删除导致缓存未命中,根据 Cache-Aside 模式,线程 2 继而查询数据库(step 2),但由于写请求通常慢于读请求,线程 1 更新数据库的操作可能会晚于线程 2 查询数据库后更新缓存的操作(step 4 晚于 step 3),那么这样便会导致最终写入缓存的结果是来自线程 2 中查询到的旧值,而写入数据库的结果是来自线程 1 的新值,即缓存落后于数据库,此时再有读请求命中缓存( step 5 ),读取到的便是旧值。
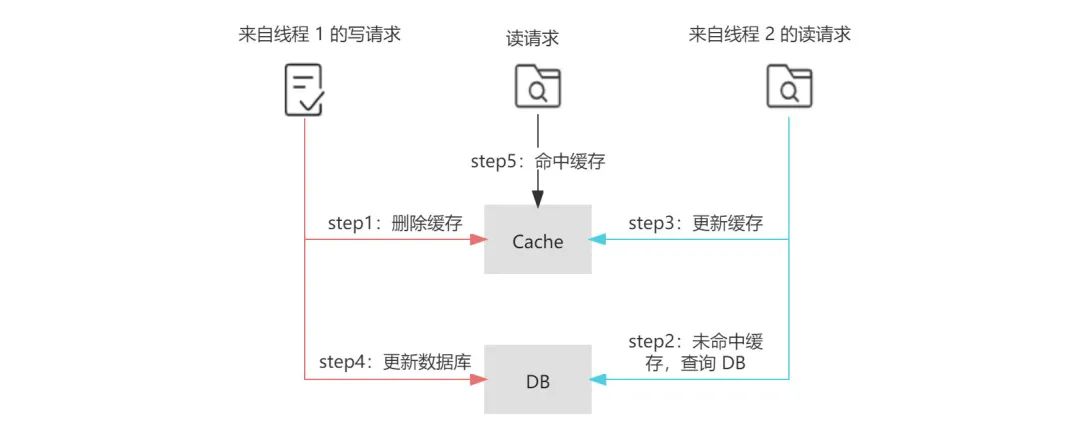
另外,先删除缓存,由于缓存中数据缺失,加剧数据库的请求压力,可能会增大缓存穿透出现的概率。
3、如果选择先删除缓存,再更新数据库,那如何解决一致性问题呢?
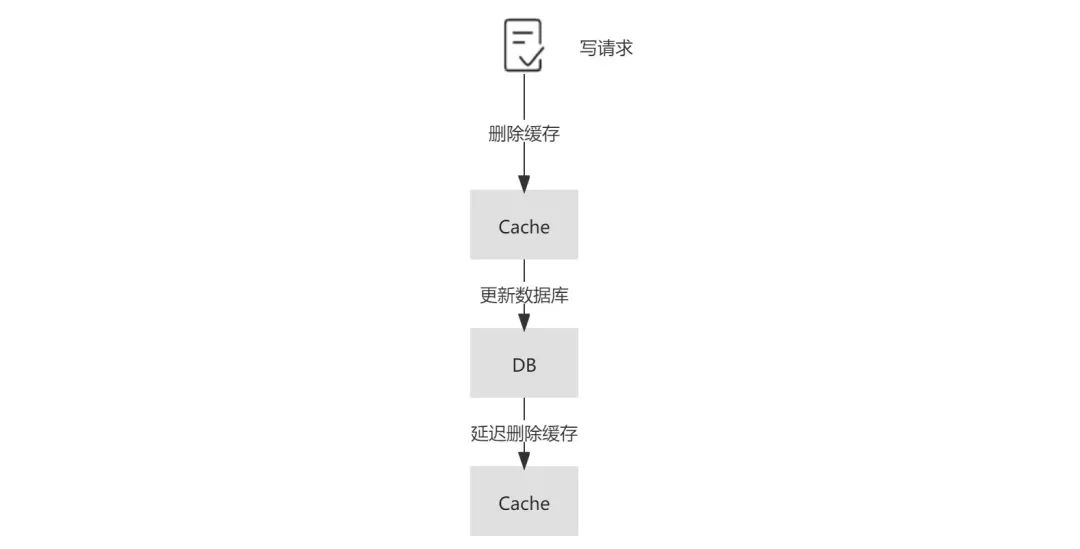
为了避免“先删除缓存,再更新数据库”这一方案在读写并发时可能带来的缓存脏数据,业界又提出了延时双删的策略,即在更新数据库之后,延迟一段时间再次删除缓存,为了保证第二次删除缓存的时间点在读请求更新缓存之后,这个延迟时间的经验值通常应稍大于业务中读请求的耗时。
延迟的实现可以在代码中 sleep 或采用延迟队列。显而易见的是,无论这个值如何预估,都很难和读请求的完成时间点准确衔接,这也是延时双删被诟病的主要原因。
4、那么 Cache-Aside 存在数据不一致的可能吗?
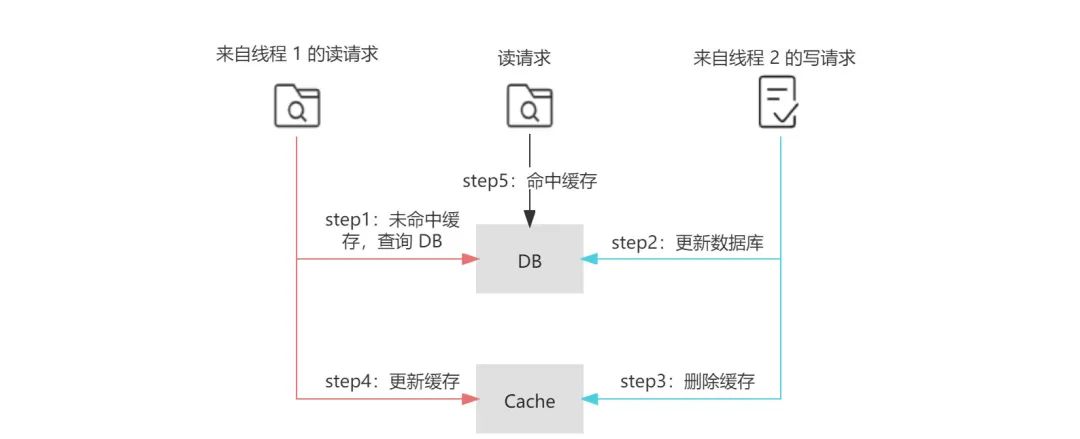
在 Cache-Aside 中,也存在数据不一致的可能性。在下面的读写并发场景下,首先来自线程 1 的读请求在未命中缓存的情况下查询数据库(step 1),接着来自线程 2 的写请求更新数据库(step 2),但由于一些极端原因,线程 1 中读请求的更新缓存操作晚于线程 2 中写请求的删除缓存的操作(step 4 晚于 step 3),那么这样便会导致最终写入缓存中的是来自线程 1 的旧值,而写入数据库中的是来自线程 2 的新值,即缓存落后于数据库,此时再有读请求命中缓存(step 5),读取到的便是旧值。
这种场景的出现,不仅需要缓存失效且读写并发执行,而且还需要读请求查询数据库的执行早于写请求更新数据库,同时读请求的执行完成晚于写请求。足以见得,这种
不一致场景产生的条件非常严格,在实际的生产中出现的可能性较小
。
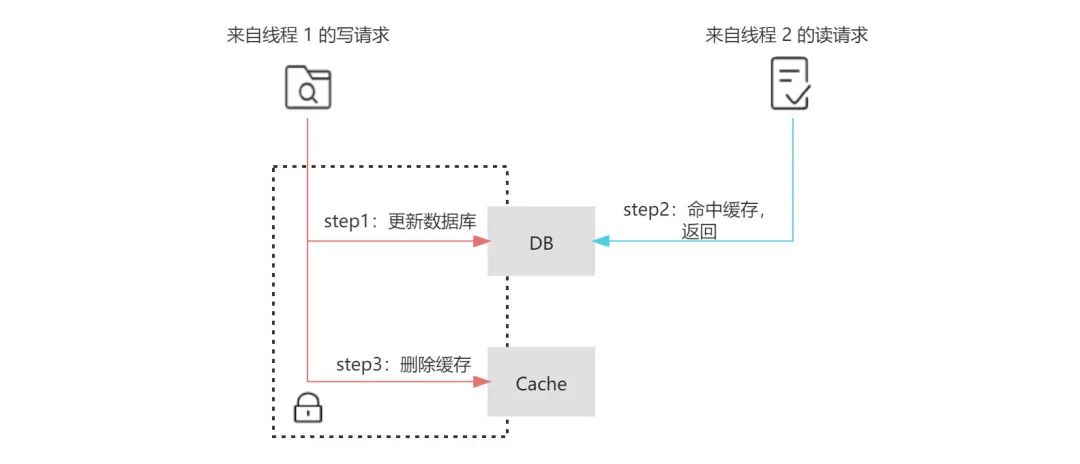
除此之外,在并发环境下,Cache-Aside 中也存在读请求命中缓存的时间点在写请求更新数据库之后,删除缓存之前,这样也会导致读请求查询到的缓存落后于数据库的情况。
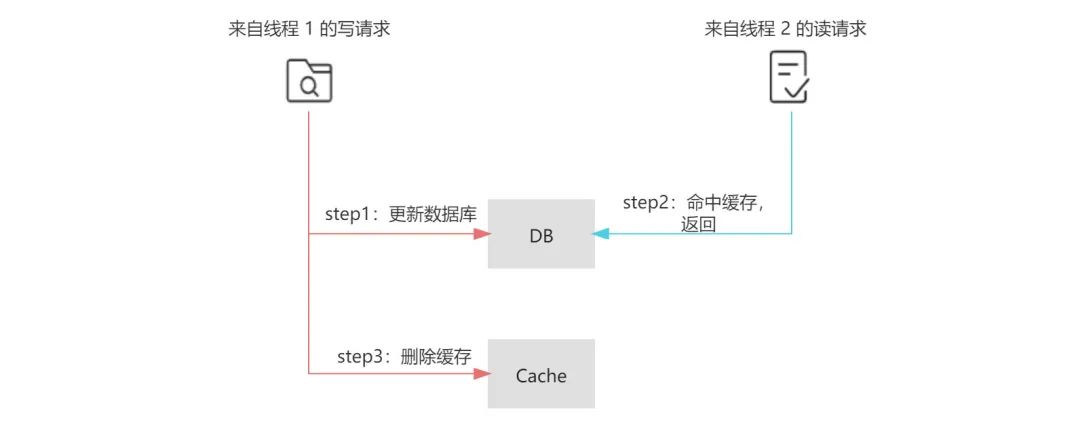
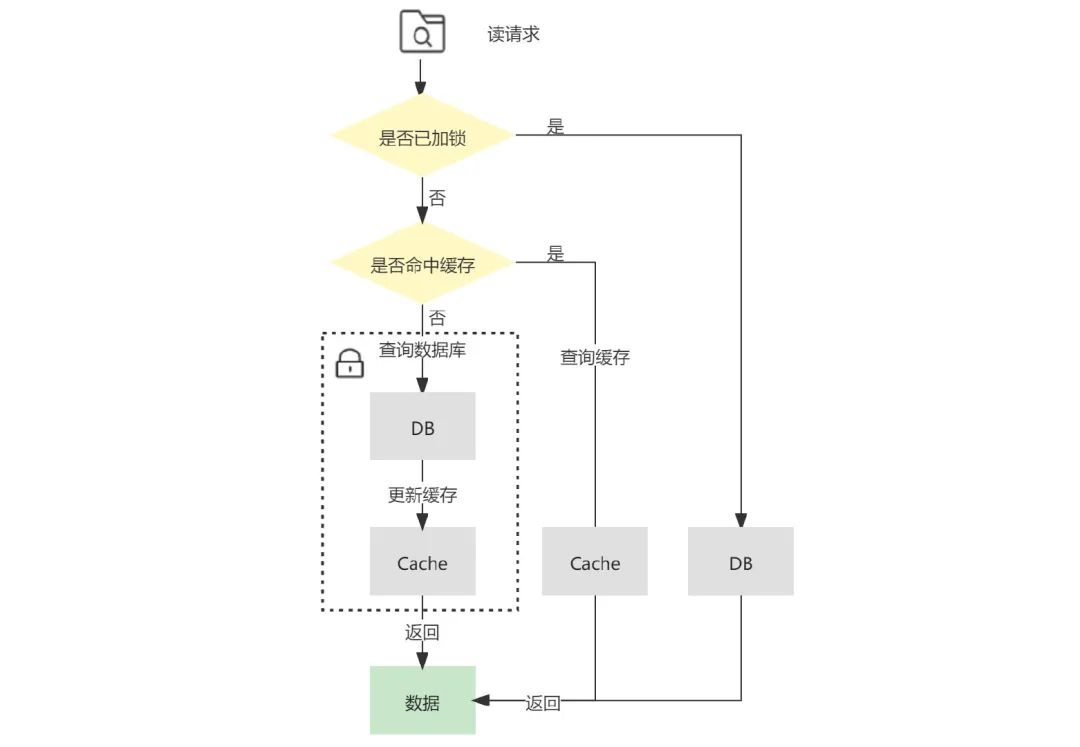
虽然在下一次读请求中,缓存会被更新,但如果业务层面对这种情况的容忍度较低,那么可以采用加锁在写请求中保证“更新数据库&删除缓存”的串行执行为原子性操作(同理也可对读请求中缓存的更新加锁)。
加锁势必会导致吞吐量的下降,故采取加锁的方案应该对性能的损耗有所预期。