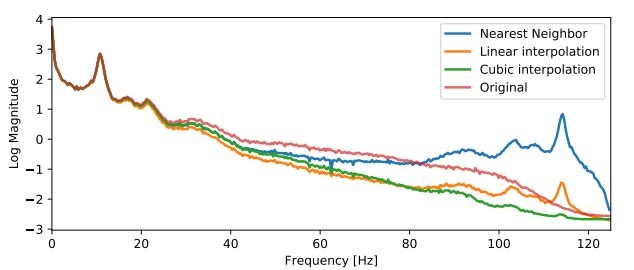
正文
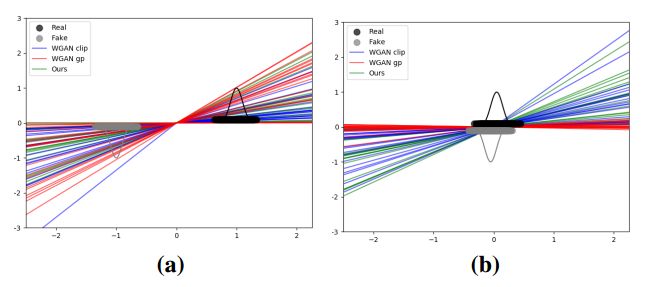
图1:WGAN批评者进行训练以最优化两种分布,其中(a)遥远,(b)近。
虽然机器学习的大部分内容涉及对来自分类任务等现实世界的数据进行信息解码,但最近也有一个非常活跃的领域,即如何通过隐式生成式模型生成现实世界数据。例如,生成人工数据可以用于数据增强(data augmentation),这种数据增强通过生成不包含在原始数据集中的自然外观样本,从而人为地增加不可见样本的训练数据。此外,生成具有某些特性的自然外观样本的可能性,以及对创建它们的模型的研究,可以成为理解用于训练GAN的原始数据分布的有用工具。
最近提出的用于生成人工数据的框架是生成式对抗网络(Goodfellow等人于2014提出),它为人工图像的生成提供了突破性结果。最初,普通GAN严重受到训练不稳定性的影响,并且仅限于低分辨率的图像的生成。通过不同的正则化方法(regularization method)(Mao等人于2016年提出、Arjovsky等人于2017年提出、Gulrajani等人于2017年提出、Kodali等人、于2017年提出),以及通过在训练期间逐渐增加的图像分辨率(Karras等人于2017年提出),生成图像的稳定性和质量方面已经取得了很大进展。GAN还允许在生成样本中对特定属性进行有意操作(Radford等人于2015年提出),因此它可以被证明是理解用于训练GAN的原始数据分布的有用工具。