正文
物体检测的两大类
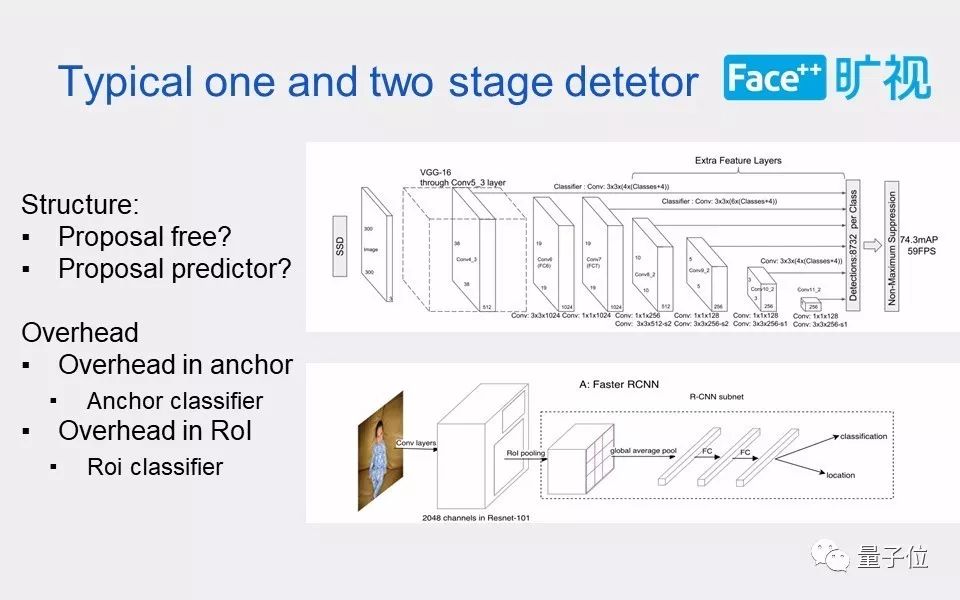
现在的物体检测比较通用的大概能分为两类:
single stage的物体检测;two stage的物体检测方法。
two stage物体检测是基于proposal的,经典的就是R-CNN这一个系列的检测方法;而single stage不依赖于proposal,例如基于anchor的 SSD方法。所以single stage在结构上会少一个proposal的predictor。Two stage往往会引入额外的计算量来对proposal,也就是所谓的ROI进行回归和分类。
也就是说Two-stage的detector比one stage多了一步,对proposal的回归和分类器(R-CNN)。如果单纯说速度,two-stage 肯定是慢于one-stage的.但是诸如retinanet和ssd的single-stage detector也存在一些问题,就是需要对每个anchor进行分类,想比two-stage的rpn而言,anchor预测的channel数会增加。
而在two stage中,第一个stage只是做一个二分类,它的channel就不会很多。 同时如果我们降低第二个stage,也就是ROI预测的部分的复杂度,直到相比于前面的base model计算量达到可以忽略不计的程度,那是不是我们也能说第二个stage对网络的速度没有太大的影响。 这样在总体的复杂度上就能和single stage的检测效率差不太多了。
所以这篇论文要探讨一个问题,就是怎么样设计第二个stage?就目前情况而言,第二个stage 太厚重了。
我们的结论是:在一般的情况下,两阶段的检测方法会在精度更具优势,但是因为它引入了比较厚重的第二个阶段,所以对速度会有一点影响。但相比one-stage物体检测,如果两阶段检测对精度有所提高,我们就能牺牲更多的精度去换取速度的提升。
为什么这么说?因为比速度都是固定的精确度的情况下,如果能达到同样的精确度,速度比另一种方法快,这个就是比较合理情况。在论文的后半部分提到会用一个小模型来替换前面的base model,就是因为小模型它会牺牲一定的精确度来提升性能。
也就是说在同样的精确度的情况下,速度如果能和single stage相匹敌,那么two stage依然是有它的优势。
所以如果能把第二个stage的计算量给减下去,而且相比single stage而言,性价比足够高,那么就可以考虑引入第二个stage。
如何提高速度
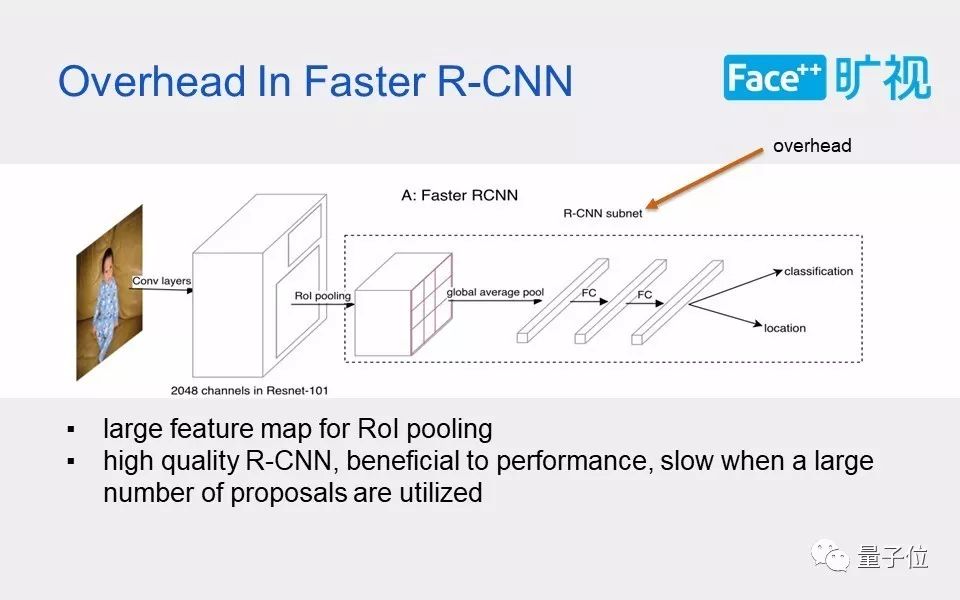
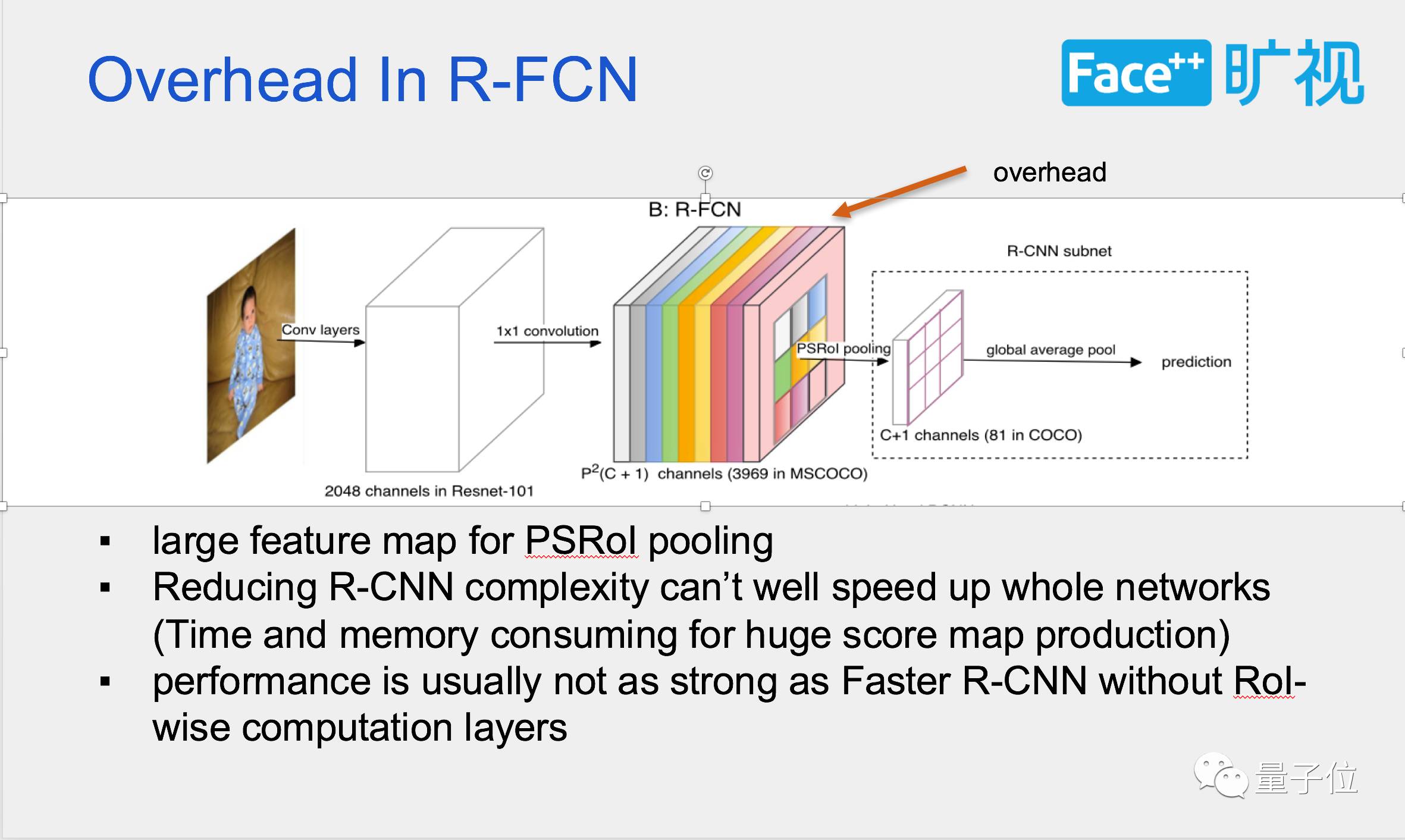
我们回顾一下Fast和R-CNN,其实它两个大体上结构都差不太多,一个是把计算量放在了ROI操作的后面,一个是把计算量放在了ROI操作的前面。也就是在Head那部分,其实他们两个都引入了一些比较大的计算量。
先具体分析下导致Faster R-CNN 和R-FCN在小模型上不够快的原因。
Faster R-CNN 用两个厚重的fc(或者resnet 的第5个stage)做proposal的预测,而R-FCN则通过制造了一个 (类别数x7x7)channel的大score map。 除去basemodel的那部分,两个方法都引入了比较大的计算量。
基于前面的观察,我们设计了更灵活通用的框架。
里面最重要的点,就是把pooling的feature map变得特别薄。为什么要把它变薄呢?因为Head那一部分,复杂度有两个因素决定:pool的feature map的厚度;以及对pool出来的feature进行分类和回归的那一部分,如果这部分逻辑比较多,它依然会对于整体的网络效率有所影响。
然后涉及到一个问题:
pooling的feature map能不能变得很薄?









