正文
第二页:https://movie.douban.com/subject/24773958/comments?
start=20&limit=20
&sort=new_score&status=P&percent_type=
第三页:https://movie.douban.com/subject/24773958/comments?
start=40&limit=20
&sort=new_score&status=P&percent_type=
我们发现,每一页评论的url地址只有一个地方在变动,就是start=后面的数字,而且是以20的倍数增加,如果我们仔细数一下,就知道这个20代表的是每一页评论的开始是所有评论中的第几条,也就是评论的序号,后面的limit=20是代表每一页显示20条评论。
第一页没有后面的参数,我们可以为了方便自己加上(也就是start=0):
为了整齐,limit=20后面的部分可以不要,最终我们的url地址就变成这样:
https://movie.douban.com/subject/24773958/comments?start=
0
&limit=20
红色0
是我们需要作出改变的地方(每次加上20)。
我们先来看如何获取我们需要的网页:
在这里我们一定要先介绍一个Python第三方库:requests库。简单来说requests库就是为了能够从网络中获取网页内容的工具。
这里是官方网站:
http://cn.python-requests.org/zh_CN/latest/
你可以在这里学习到requests更多的方法。有中文哦。
我们看一个例子:
get方法返回的就是包含了网页所有信息的对象,我们可以通过r.text将网页内容取出来。
import requests r =requests.get("https://movie.douban.com/subject/24773958/comments?start=0&limit=20") html = r.text
print(html)
执行上面这几行代码,我们就得到了网页的源代码:如下图
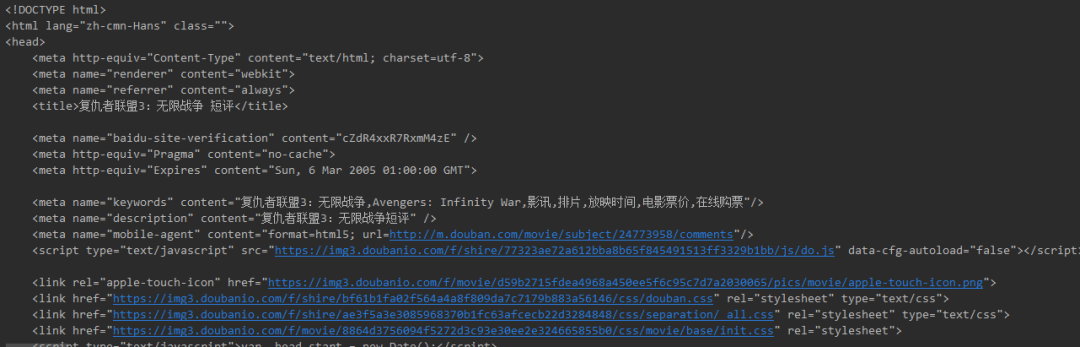
接下来我们需要分析如何在网页中找到我们需要的评论内容。
这里再介绍一个Python第三方库:BeautifulSoup库。
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够将网页代码解析成一个由html标签构筑的标签树对象,并提供了丰富的方法让使用者从这个标签树中获取需要的信息。
这里是官方网站:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
你可以通过这里的手册快速对BeautifulSoup库有个基本的了解。
我们可以通过pip方式进行安装:
在cmd命令行输入:
pip install BeautifulSoup4
安装好之后就可以导入直接使用了。
我们使用from关键字进行导入:
from bs4 import BeautifulSoup
每一个网页都是由不同的html标签构成的,比如段落就是p标签,他们成对出现,比如:
这里就是段落内容
。而标签和标签之间是可以嵌套的,也就是说可以一层包含一层的。所以,想得到里面的内容就需要先找到这个标签。
通过查看网页源代码可以发现,每个页面中的评论列表都在一个class=”mod-bd”,id=”comments”的div标签里,而每个评论者的评论内容都在该标签下的class=”” 的p标签内,如下所示
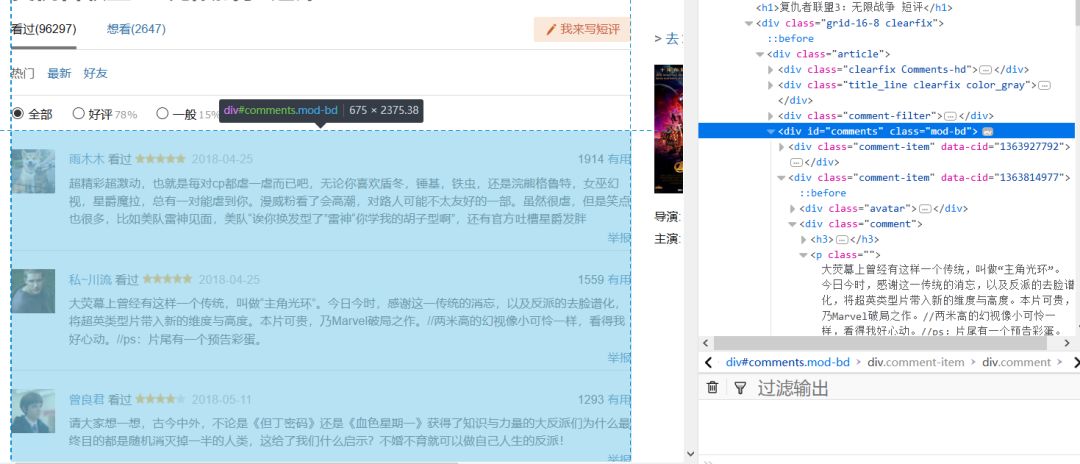
因此我们先要找到class=”mod-bd”的div标签
我们通过BeautifulSoup库可以很方便的找到这部分:
首先我们要通过BeautifulSoup将我们获取的网页内容转化成对象,并通过html.parser进行解析:
soup = BeautifulSoup(html, "html.parser"










