正文
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。
这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。
NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
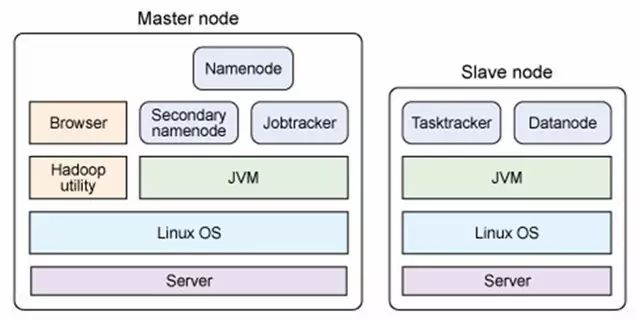
主从结构
主节点,只有一个: namenode
从节点,有很多个: datanodes
namenode负责:接收用户操作请求 、维护文件系统的目录结构、管理文件与block之间关系,block与datanode之间关系
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。
datanode负责:存储文件文件被分成block存储在磁盘上、为保证数据安全,文件会有多个副本
MapReduce是处理大量半结构化数据集合的编程模型。编程模型是一种处理并结构化特定问题的方式。例如,
在一个关系数据库中,使用一种集合语言执行查询,如SQL。告诉语言想要的结果,并将它提交给系统来计算出如何产生计算。
还可以用更传统的语言(C++,Java),一步步地来解决问题。这是两种不同的编程模型,MapReduce就是另外一种。
MapReduce和Hadoop是相互独立的,实际上又能相互配合工作得很好。
主从结构
主节点,只有一个: JobTracker
从节点,有很多个: TaskTrackers
JobTracker负责:接收客户提交的计算任务、把计算任务分给TaskTrackers执行、监控TaskTracker的执行情况
TaskTrackers负责:执行JobTracker分配的计算任务
-
大数据量存储:分布式存储
-
日志处理: Hadoop擅长这个
-
海量计算: 并行计算
-
ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
-
使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
-
机器学习: 比如Apache Mahout项目
-
搜索引擎:hadoop + lucene实现
-
数据挖掘:目前比较流行的广告推荐
-
大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高。
-
数据支持一次写入,多次读取。对于已经形成的数据的更新不支持。
-
数据不进行本地缓存(文件很大,且顺序读没有局部性)
-
任何一台服务器都有可能失效,需要通过大量的数据复制使得性能不会受到大的影响。
-
用户细分特征建模
-
个性化广告推荐
-
智能仪器推荐