正文
20世纪80年代时,这些内容还没有进入计算机体系结构的书中,所以我们在1989年编写《计算机架构:定量方法》( Computer Architecture: AQuantitative Approach)一书。本书的主题是使用测量和基准测试来对计算机架构进行量化评估,而不是更多地依赖于架构师的直觉和经验,就像过去一样。我们使用的定量方法也得益于图灵奖得主高德纳(Donald Knuth)关于算法的著作内容的启发。
VLIW,EPIC,Itanium。指令集架构的下一次创新试图同时惠及RISC和CISC,即超长指令字(VLIW)和显式并行指令计算机(EPIC)的诞生。这两项发明由英特尔和惠普共同命名的,在每条指令中使用捆绑在一起的多个独立操作的宽指令。VLIW和EPIC的拥护者认为,如果用一条指令可以指定六个独立的操作——两次数据传输,两次整数操作和两次浮点操作,编译器技术可以有效地将这些操作分配到六个指令槽中,硬件架构就可以变得更简单。与RISC方法一样,VLIW和EPIC的目的是将工作负载从硬件转移到编译器上。
英特尔和惠普合作设计了一款基于EPIC理念的64位处理器Itanium,想用其取代32位x86处理器并对其抱了很高的期望,但实际情况与他们的早期预期并不相符。虽然EPIC方法适用于高度结构化的浮点程序,但在可预测性较低的缓存或的分支整数程序上很难实现高性能。正如高德纳后来所指出的那样:“Itanium的设想非常棒,但事实证明满足这种设想的编译器基本上不可能写出来。” 开发人员注意到Itanium的迟钝和性能不佳,将用命途多舛的游轮“Titanic”其重命名为“Itanic”。不过,市场再次失去了耐心,最终64位版本的x86成为32位x86的继承者,没有轮到Itanium。
不过一个好消息是,VLIW在较窄的应用程序与小程序上,包括数字信号处理任务中留有一席之地。
AMD和英特尔利用500人的设计团队和先进的半导体技术,缩小了x86和RISC之间的性能差距。同样,受到流水线化简单指令vs.复杂指令的性能优势的启发,指令解码器在运行中将复杂的x86指令转换成类似RISC的内部微指令。AMD和英特尔随后将RISC微指令的执行流程化。RISC的设计人员为了性能所提出的任何想法,例如隔离指令和数据缓存、片上二级缓存、deep pipelines以及同时获取和执行多条指令等,都可以集成到x86中。在2011年PC时代的巅峰时期,AMD和英特尔每年大约出货3.5亿台x86微处理器。PC行业的高产量和低利润率也意味着价格低于RISC计算机。
考虑到全球每年售出数亿台个人电脑,PC软件成为了一个巨大的市场。尽管Unix市场的软件供应商会为不同的商业RISC ISA (Alpha、HP-PA、MIPS、Power和SPARC)提供不同的软件版本,但PC市场只有一个ISA,因此软件开发人员发布的“压缩打包”软件只能与x86 ISA兼容。更大的软件基础、相似的性能和更低的价格使得x86在2000年之前同时统治了台式机和小型服务器市场。
Apple公司在2007年推出了iPhone,开创了后PC时代
。智能手机公司不再购买微处理器,而是使用其他公司的设计(包括ARM的RISC处理器),在芯片上构建自己的系统(SoC)。移动设备的设计者不仅重视性能,而且重视晶格面积和能源效率,这对CISC ISA不利。此外,物联网的到来大大增加了处理器的数量,以及在晶格大小、功率、成本和性能方面所需的权衡。这种趋势增加了设计时间和成本的重要性,进一步不利于CISC处理器。在今天的后PC时代,x86的出货量自2011年达到峰值以来每年下降近10%,而采用RISC处理器的芯片的出货量则飙升至200亿。
今天,99%的32位和64位处理器都是RISC
。
总结上面的历史回顾,我们可以说
市场已经解决了RISC-CISC的争论
;CISC赢得了PC时代的后期阶段,但RISC正在赢得整个后PC时代。几十年来,没有出现新的CISC ISA。令我们吃惊的是,今天在通用处理器的最佳ISA原则方面的共识仍然是RISC,尽管距离它们的推出已经过去35年了。
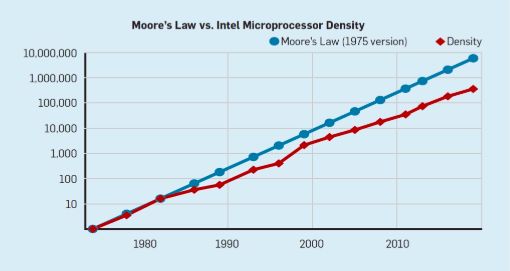
虽然上一节的重点是指令集体系结构(ISA)的设计,但大多数计算机架构师并不设计新的ISA,而是在当前的实现技术中实现现有的ISA。自20世纪70年代末以来,技术的选择一直是基于金属氧化物半导体(MOS)的集成电路,首先是n型金属氧化物半导体(nMOS),然后是互补金属氧化物半导体(CMOS)。MOS技术惊人的改进速度(Gordon Moore的预测中已经提到这一点)已经成为驱动因素,使架构师能够设计更积极的方法来实现给定ISA的性能。摩尔在1965年26年的最初预测要求晶体管密度每年翻一番;1975年,他对其进行了修订,预计每两年翻一番。这最终被称为摩尔定律。由于晶体管密度呈二次增长,而速度呈线性增长,架构师们使用了更多的晶体管来提高性能。
尽管摩尔定律已经存在了几十年(见图2),但它在2000年左右开始放缓,到2018年,摩尔的预测与目前的能力之间的差距大约是15倍。目前的预期是,随着CMOS技术接近基本极限,差距将继续扩大。
与摩尔定律相伴而来的是罗伯特·登纳德(Robert Dennard)的预测,称为
“登纳德缩放比例”(Dennard Scaling)
。该定律指出,随着晶体管密度的增加,每个晶体管的功耗会下降,因此每平方毫米硅的功耗几乎是恒定的。由于硅的计算能力随着每一代新技术的发展而提高,计算机将变得更加节能。Dennard Scaling在2007年开始显著放缓,到2012年几乎变为零(见图3)。
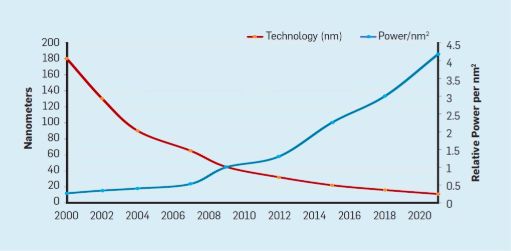
图3:Transistors per chip and power per mm2.
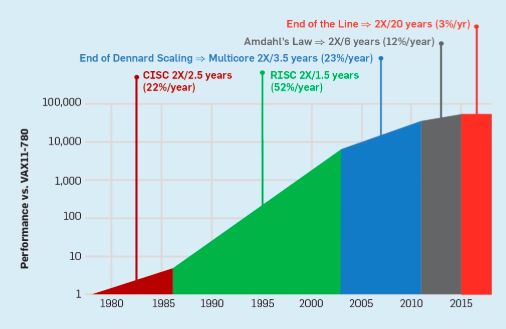
在1986年到2002年之间,指令级并行(ILP)的开发是提高性能的主要架构方法,并且随着晶体管速度的提高,每年的性能增长大约50%。Dennard Scaling的结束意味着架构师必须找到更有效的方法来利用并行性。
要理解为什么ILP的增加会导致更大的效率低下,可以考虑一个像ARM、Intel和AMD这样的现代处理器核心。假设它有一个15-stage的pipeline,每个时钟周期可以发出四条指令。因此,它在任何时刻都有多达60条指令在pipeline中,包括大约15个分支,因为它们代表了大约25%的执行指令。为了使pipeline保持完整,需要预测分支,并推测地将代码放入pipeline中以便执行。投机性的使用是ILP性能和效率低下的根源。当分支预测完美时,推测可以提高性能,但几乎不需要额外的能源成本——甚至可以节省能源——但是当它“错误地预测”分支时,处理器必须扔掉错误推测的指令,它们的计算工作和能量就被浪费了。处理器的内部状态也必须恢复到错误预测分支之前的状态,这将花费额外的时间和精力。
要了解这种设计的挑战性,请考虑正确预测15个分支的结果的难度。如果处理器架构师希望将浪费的工作限制在10%的时间内,那么处理器必须在99.3%的时间内正确预测每个分支。很少有通用程序具有能够如此准确预测的分支。
为了理解这些浪费的工作是如何累加起来的,请考虑下图中的数据,其中显示了有效执行但由于处理器的错误推测而被浪费的指令的部分。在Intel Core i7上,这些基准测试平均浪费了19%的指令。
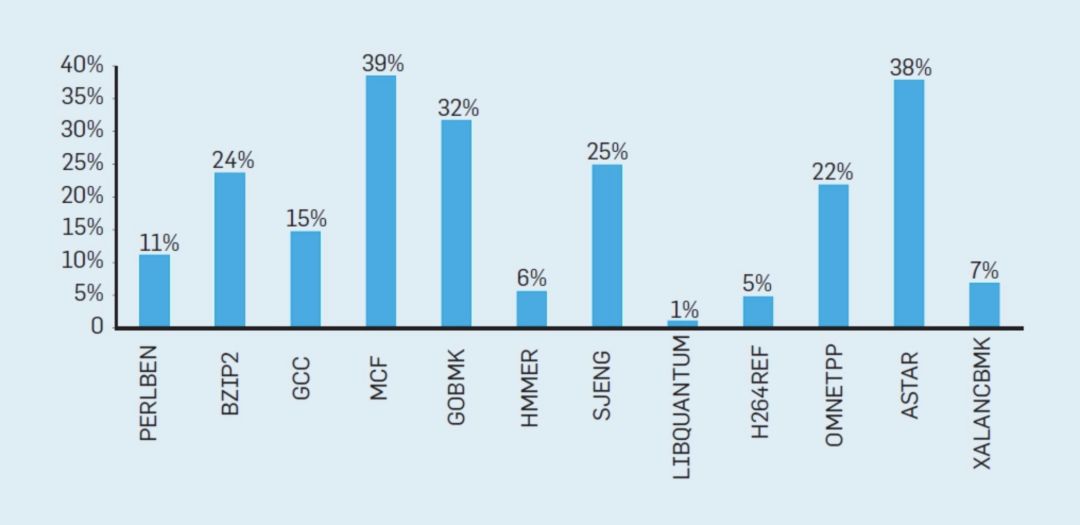
但是,浪费的能量更大,因为处理器在推测错误时必须使用额外的能量来恢复状态。这样的度量导致许多人得出结论,架构师需要一种不同的方法来实现性能改进。多核时代就这样诞生了。
多核将识别并行性和决定如何利用并行性的责任转移给程序员和语言系统。多核并不能解决由于登纳德缩放比例定律结束而加剧的节能计算的挑战。无论有源堆芯对计算的贡献是否有效,有源堆芯都会消耗能量。
一个主要的障碍是
Amdahl定律
,它指出并行计算机的加速受到连续计算部分的限制。 为了理解这一观察的重要性,请考虑下图,其中显示了假设串行执行的不同部分(其中只有一个处理器处于活动状态),在最多64个内核的情况下,应用程序的运行速度要比单个内核快得多。例如,当只有1%的时间是串行的,64处理器配置的加速大约是35。不幸的是,所需的功率与64个处理器成正比,因此大约45%的能量被浪费了。
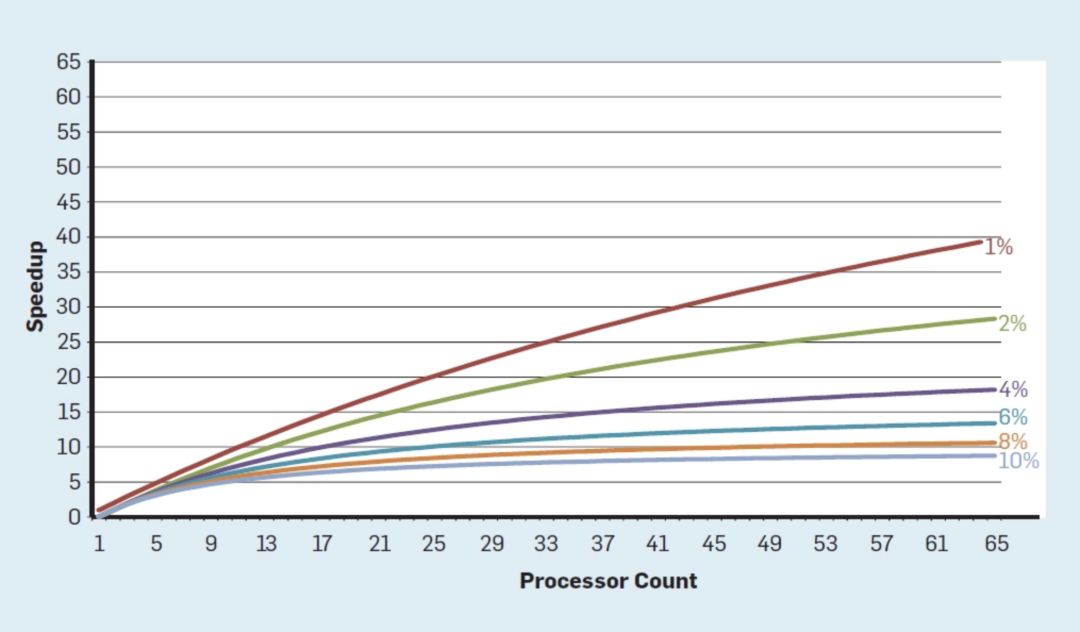
当然,真正的程序有更复杂的结构,其中部分允许在任何给定的时间点使用不同数量的处理器。尽管如此,定期通信和同步的需求意味着大多数应用程序的某些部分只能有效地使用一部分处理器。尽管Amdahl定律已有50多年的历史,但它仍然是一个困难的障碍。
随着
Dennards Scaling
定律的结束,芯片上内核数量的增加意味着
功率也在以几乎相同的速度增长
。不幸的是,进入处理器的能量也必须以热量的形式被移除。因此,多核处理器受到热耗散功率(TDP)的限制,即封装和冷却系统可以移除的平均功率。虽然一些高端数据中心可能会使用更先进的软件包和冷却技术,但没有电脑用户愿意在办公桌上安装一个小型热交换器,或者在背上安装散热器来冷却手机。TDP的限制直接导致了“暗硅”时代,处理器会降低时钟速率,关闭空闲内核以防止过热。另一种看待这种方法的方法是,一些芯片可以重新分配他们宝贵的权力,从空闲的核心到活跃的。
一个没有Dennards Scaling,摩尔定律减速、Amdahl法则完全有效的时代,意味着低效率限制了性能的提升,每年只有几个百分点的提升(见图6)。
实现更高的性能改进需要新的架构方法,更有效地使用集成电路功能
。在讨论了现代计算机的另一个主要缺点后,我们将回到可能起作用的方法上来。