正文
你不会Java?Shell、Python都可以,有个东西叫Hadoop Streaming。
如果你认真完成了以上几步,恭喜你,你的一只脚已经进来了。
第二章:更高效的WordCount
2.1 学点SQL吧
你知道数据库吗?你会写SQL吗?
如果不会,请学点SQL吧。
2.2 SQL版WordCount
在1.6中,你写(或者抄)的WordCount一共有几行代码?
给你看看我的:
SELECT word,COUNT(1) FROM wordcount GROUP BY word;
这便是SQL的魅力,编程需要几十行,甚至上百行代码,我这一句就搞定;使用SQL处理分析Hadoop上的数据,方便、高效、易上手、更是趋势。不论是离线计算还是实时计算,越来越多的大数据处理框架都在积极提供SQL接口。
2.3 SQL On Hadoop之Hive
什么是Hive?官方给的解释是:
The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax.
为什么说Hive是数据仓库工具,而不是数据库工具呢?有的朋友可能不知道数据仓库,数据仓库是逻辑上的概念,底层使用的是数据库,数据仓库中的数据有这两个特点:最全的历史数据(海量)、相对稳定的;所谓相对稳定,指的是数据仓库不同于业务系统数据库,数据经常会被更新,数据一旦进入数据仓库,很少会被更新和删除,只会被大量查询。而Hive,也是具备这两个特点,因此,Hive适合做海量数据的数据仓库工具,而不是数据库工具。
2.4 安装配置Hive
请参考1.1 和 1.2 完成Hive的安装配置。可以正常进入Hive命令行。
2.5 试试使用Hive
请参考1.1 和 1.2 ,在Hive中创建wordcount表,并运行2.2中的SQL语句。
在Hadoop WEB界面中找到刚才运行的SQL任务。
看SQL查询结果是否和1.4中MapReduce中的结果一致。
2.6 Hive是怎么工作的
明明写的是SQL,为什么Hadoop WEB界面中看到的是MapReduce任务?
2.7 学会Hive的基本命令
创建、删除表;
加载数据到表;
下载Hive表的数据;
请参考1.2,学习更多关于Hive的语法和命令。
如果你已经按照《写给大数据开发初学者的话》中第一章和第二章的流程认真完整的走了一遍,那么你应该已经具备以下技能和知识点:
0和Hadoop2.0的区别;
MapReduce的原理(还是那个经典的题目,一个10G大小的文件,给定1G大小的内存,如何使用Java程序统计出现次数最多的10个单词及次数);
HDFS读写数据的流程;向HDFS中PUT数据;从HDFS中下载数据;
自己会写简单的MapReduce程序,运行出现问题,知道在哪里查看日志;
会写简单的SELECT、WHERE、GROUP BY等SQL语句;
Hive SQL转换成MapReduce的大致流程;
Hive中常见的语句:创建表、删除表、往表中加载数据、分区、将表中数据下载到本地;
从上面的学习,你已经了解到,HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据,MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据,而Hive则是SQL On Hadoop,Hive提供了SQL接口,开发人员只需要编写简单易上手的SQL语句,Hive负责把SQL翻译成MapReduce,提交运行。
此时,你的”大数据平台”是这样的:
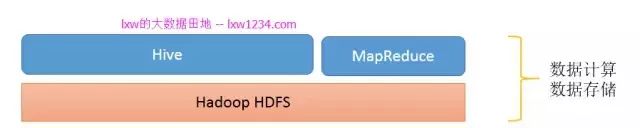
那么问题来了,海量数据如何到HDFS上呢?
第三章:把别处的数据搞到Hadoop上
此处也可以叫做数据采集,把各个数据源的数据采集到Hadoop上。
3.1 HDFS PUT命令
这个在前面你应该已经使用过了。
put命令在实际环境中也比较常用,通常配合shell、python等脚本语言来使用。
建议熟练掌握。
3.2 HDFS API
HDFS提供了写数据的API,自己用编程语言将数据写入HDFS,put命令本身也是使用API。
实际环境中一般自己较少编写程序使用API来写数据到HDFS,通常都是使用其他框架封装好的方法。比如:Hive中的INSERT语句,Spark中的saveAsTextfile等。
建议了解原理,会写Demo。
3.3 Sqoop
Sqoop是一个主要用于Hadoop/Hive与传统关系型数据库




