正文
超长的训练时间。
这个原因非常好理解:当Batch-Size较小时,我们必须迭代更多的次数来让算法收敛;随着Batch-Size的增加,算法每次迭代见过的图片数量也随之增长,相应的迭代次数就可以下降,人们也能更快地得到结果。
基于上述四点分析,我们应该对Batch-Size这一问题有了一个直观的认识。我们在比赛中,为了解决这个问题,特意研发了一整套多机训练系统,以实现我们
大Batch-Size物体检测算法:MegDet。
因为有良好的内部支持,我们的MegDet算法可以几乎无开销完成算量,产生几乎线性的加速比和更优的检测结果。下面,我将介绍MegDet实现过程中的四个要点。

-
要实现MegDet,
首先需要大量的底层支持
,大致上可以分为三类:第一是一套GPU 计算云平台,这在我们内部被称为Brain++平台,专门负责统筹规划硬件资源的使用;第二是基于Brain++平台的MegBrain软件框架,提供了诸多深度学习必备的工具箱。第三是在前面两者之上建立的物体检测算法,在此我们基于FPN框架设计了一套检测算法。
这里,我们简单科普一下FPN检测框架。和传统的Faster-RCNN框架不同,FPN在不同尺寸的特征图上提取RoI,以此达到分而治之的效果,即:大物体在小特征图上检测,小物体在大特征图上检测。这种设计既能充分利用现有卷积神经网络的锥形结构,又能有效解决COCO数据集中普遍存在的小物体问题,一举两得。


-
解决了BN统计不准确的问题。
简单来讲,已有的BN统计方法局限于统计单张卡上的图片,做不到多张卡联合统计。由于物体检测本身的特性,单张卡上的图片数量达不到BN统计的要求,因此只能通过多卡联合统计来训练得到结果。为此,我们利用了NCCL(NVIDIA Collective Communications Library)代码库,实现了多卡BN。具体的算法流程可以参照上图,首先通过单卡自主统计BN的参数,再将参数发送到单张卡上进行合并,最后再把BN的结果同步到其他卡上,以进行下一步的训练。

-
Sublinear Memory技术。
这项技术的目的在于减少深度卷积神经网络的显存消耗量,保证我们在比赛之中可以尽可能地使用大模型。我们可以通过上图来简单地体会这项技术的作用。在现有训练方法中,为了计算Conv2中参数(W2, b2)的梯度,人们一般需要保存Conv2的输出结果;但实际上,Conv2的输出结果可以根据Conv1的结果来动态计算,这样Conv2的输出结果就不需要保存,显存消耗也能进一步下降;特别是一些非常深的神经网络,例如152层的模型,Sublinear Memory能显著降低显存的使用量,帮助我们尝试更多的技巧。
-
介绍一些在大Batch-Size下的学习率调参技巧。
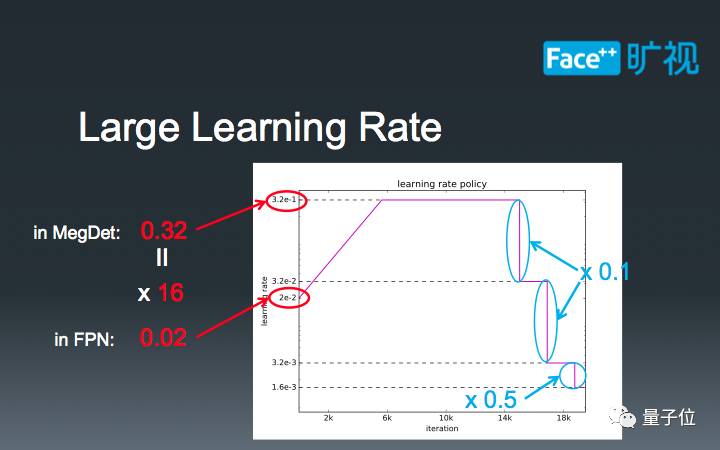
16-batch的FPN标准学习率是0.02, 而我们的MegDet的Batch-Size是256。在这种情况下,我们如果直接设定学习率为0.32=0.02 x 16,会导致模型早期迅速发散,无法完成训练。因此,我们需要有一个“逐步预热”的过程,让模型逐渐适应较大的学习率。当训练到一定阶段的时候,我们设定了三个下降阶段:在前两个阶段,我们直接将学习率除以10,最后再将学习率减半。这种学习率的设计主要是为了在比赛中取得极致性能,也是我们的经验所得。

至此,我们可以比较一下不同年份,物体检测的Batch-Size规模。最初,2015年,人们使用2-batch来训练物体检测算法;过了一年之后,这个数字增长到了8倍,即16-batch;今年,在我们Megvii研究院的推动下,又增长到了256-batch,是原始Faster-RCNN的128倍,FPN的16倍。这个数字也恰好是ImageNet常见的Batch-Size。
在MegDet的帮助之下,我们取得了COCO Detection Challenge 2017的冠军,同时也部分解决了之前提到的小Batch-Size训练的问题。
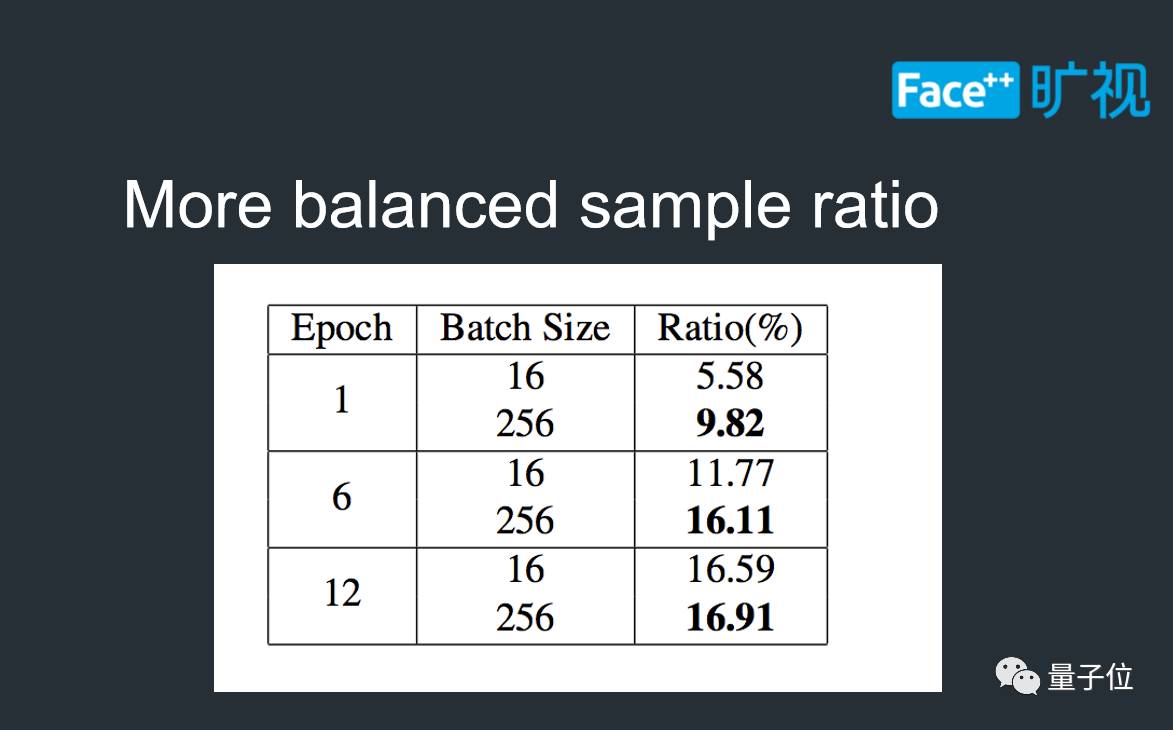
首先,根据我们的统计,在训练过程之中,正负样本比例比小Batch-Size更优,这也意味着梯度的计算能更好地拟合数据分布。
下图展示了两张正样本比例相差较大的结果,由于大Batch-Size能够同时计算这两种极端情况的梯度,使得模型参数更新更加平稳。
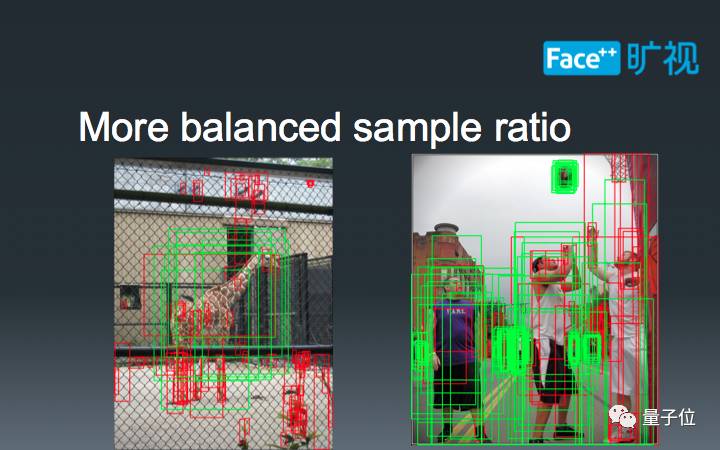
其次,我们通过多机BN的实现,实现了大Batch-Size下物体检测算法的性能提升。
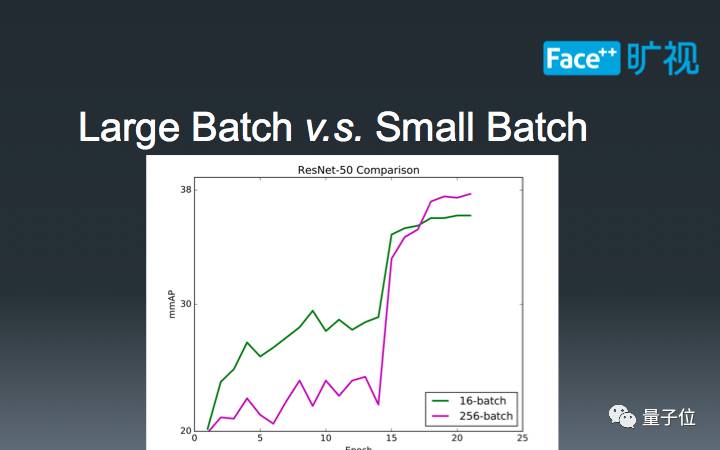
在已有的ImageNet Classification任务中,人们研究大Batch-Size的目的是为了防止掉点;然而在物体检测任务之中,我们却惊奇地发现,大Batch-Size可以直接带来性能提升,这和已有的经验并不相符。另一方面,通过上图的逐Epoch精度曲线,我们还发现256-batch和16-batch在同等Epoch下的精度并不能重合,甚至还有较大的间隔,这也和ImageNet Classification已有的研究结果相违背。一个潜在的因素是物体检测的多loss计算扰乱了中间结果的检测精度,但详细研究这个现象还需要跟多的实验,这已经超出了本文的范畴。









