正文
所以,在使用 Redis 时,如何持续发挥它的高性能,避免操作延迟的情况发生,也是我们的关注焦点。
在这方面,我给你总结了 13 条建议:
1) 避免存储 bigkey
存储 bigkey 除了前面讲到的使用过多内存之外,对 Redis 性能也会有很大影响。
由于 Redis 处理请求是单线程的,当你的应用在写入一个 bigkey 时,更多时间将消耗在「内存分配」上,这时操作延迟就会增加。同样地,删除一个 bigkey 在「释放内存」时,也会发生耗时。
而且,当你在读取这个 bigkey 时,也会在「网络数据传输」上花费更多时间,此时后面待执行的请求就会发生排队,Redis 性能下降。
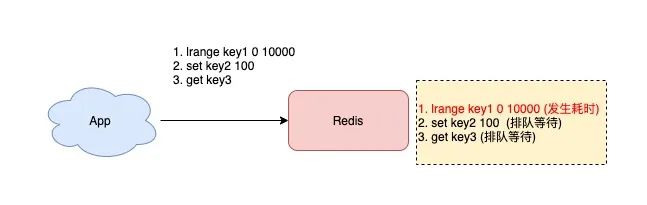
所以,你的业务应用尽量不要存储 bigkey,避免操作延迟发生。
如果你确实有存储 bigkey 的需求,你可以把 bigkey 拆分为多个小 key 存储。
2) 开启 lazy-free 机制
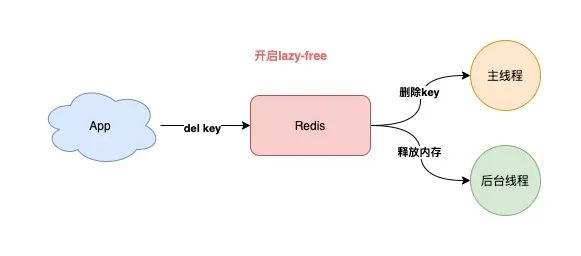
如果你无法避免存储 bigkey,那么我建议你开启 Redis 的 lazy-free 机制。(4.0+版本支持)
当开启这个机制后,Redis 在删除一个 bigkey 时,释放内存的耗时操作,将会放到后台线程中去执行,这样可以在最大程度上,避免对主线程的影响。
3) 不使用复杂度过高的命令
Redis 是单线程模型处理请求,除了操作 bigkey 会导致后面请求发生排队之外,在执行复杂度过高的命令时,也会发生这种情况。
因为执行复杂度过高的命令,会消耗更多的 CPU 资源,主线程中的其它请求只能等待,这时也会发生排队延迟。
所以,你需要避免执行例如 SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
对于这种聚合类操作,我建议你把它放到客户端来执行,不要让 Redis 承担太多的计算工作。
4) 执行 O(N) 命令时,关注 N 的大小
规避使用复杂度过高的命令,就可以高枕无忧了么?
答案是否定的。
当你在执行 O(N) 命令时,同样需要注意 N 的大小。
如果一次性查询过多的数据,也会在网络传输过程中耗时过长,操作延迟变大。
所以,对于容器类型(List/Hash/Set/ZSet),在元素数量未知的情况下,一定不要无脑执行 LRANGE key 0 -1 / HGETALL / SMEMBERS / ZRANGE key 0 -1。
在查询数据时,你要遵循以下原则:
-
先查询数据元素的数量(LLEN/HLEN/SCARD/ZCARD)
-
-
元素数量非常多,分批查询数据(LRANGE/HASCAN/SSCAN/ZSCAN)
5) 关注 DEL 时间复杂度
你没看错,在删除一个 key 时,如果姿势不对,也有可能影响到 Redis 性能。
删除一个 key,我们通常使用的是 DEL 命令,回想一下,你觉得 DEL 的时间复杂度是多少?
O(1) ?其实不一定。
当你删除的是一个 String 类型 key 时,时间复杂度确实是 O(1)。
但当你要删除的 key 是 List/Hash/Set/ZSet 类型,它的复杂度其实为 O(N),N 代表元素个数。
也就是说,删除一个 key,其元素数量越多,执行 DEL 也就越慢!
原因在于,删除大量元素时,需要依次回收每个元素的内存,元素越多,花费的时间也就越久!
而且,这个过程默认是在主线程中执行的,这势必会阻塞主线程,产生性能问题。
那删除这种元素比较多的 key,如何处理呢?
我给你的建议是,分批删除:
-
List类型:执行多次 LPOP/RPOP,直到所有元素都删除完成
-
Hash/Set/ZSet类型:先执行 HSCAN/SSCAN/SCAN 查询元素,再执行 HDEL/SREM/ZREM 依次删除每个元素
没想到吧?一个小小的删除操作,稍微不小心,也有可能引发性能问题,你在操作时需要格外注意。
6) 批量命令代替单个命令
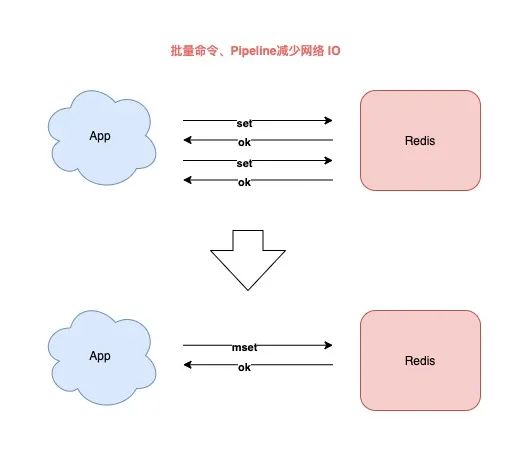
当你需要一次性操作多个 key 时,你应该使用批量命令来处理。
批量操作相比于多次单个操作的优势在于,可以显著减少客户端、服务端的来回网络 IO 次数。
所以我给你的建议是:
-
String / Hash 使用 MGET/MSET 替代 GET/SET,HMGET/HMSET 替代 HGET/HSET
-
其它数据类型使用 Pipeline,打包一次性发送多个命令到服务端执行
7) 避免集中过期 key
Redis 清理过期 key 是采用定时 + 懒惰的方式来做的,而且这个过程都是在主线程中执行。
如果你的业务存在大量 key 集中过期的情况,那么 Redis 在清理过期 key 时,也会有阻塞主线程的风险。
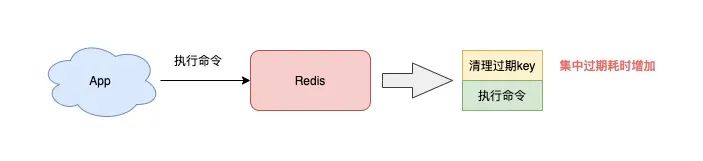
想要避免这种情况发生,你可以在设置过期时间时,增加一个随机时间,把这些 key 的过期时间打散,从而降低集中过期对主线程的影响。
8) 使用长连接操作 Redis,合理配置连接池
你的业务应该使用长连接操作 Redis,避免短连接。
当使用短连接操作 Redis 时,每次都需要经过 TCP 三次握手、四次挥手,这个过程也会增加操作耗时。
同时,你的客户端应该使用连接池的方式访问 Redis,并设置合理的参数,长时间不操作 Redis 时,需及时释放连接资源。
9) 只使用 db0
尽管 Redis 提供了 16 个 db,但我只建议你使用 db0。
为什么呢?我总结了以下 3 点原因:
-
在一个连接上操作多个 db 数据时,每次都需要先执行 SELECT,这会给 Redis 带来额外的压力
-
使用多个 db 的目的是,按不同业务线存储数据,那为何不拆分多个实例存储呢?拆分多个实例部署,多个业务线不会互相影响,还能提高 Redis 的访问性能
-
Redis Cluster 只支持 db0,如果后期你想要迁移到 Redis Cluster,迁移成本高
10) 使用读写分离 + 分片集群
如果你的业务读请求量很大,那么可以采用部署多个从库的方式,实现读写分离,让 Redis 的从库分担读压力,进而提升性能。
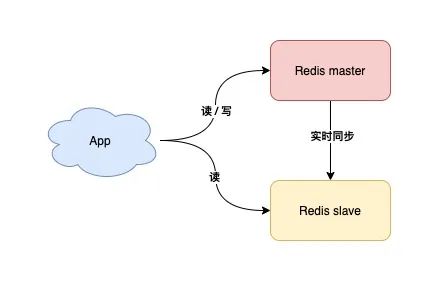
如果你的业务写请求量很大,单个 Redis 实例已无法支撑这么大的写流量,那么此时你需要使用分片集群,分担写压力。
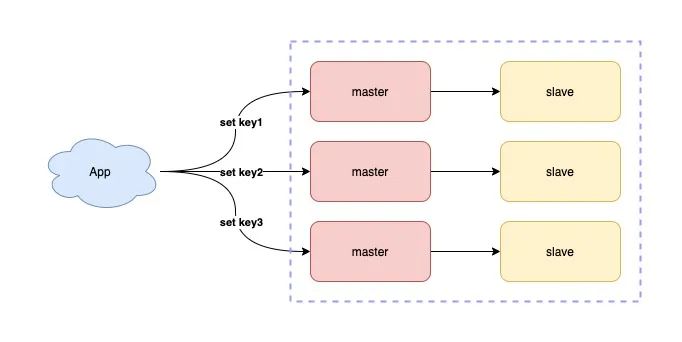
11) 不开启 AOF 或 AOF 配置为每秒刷盘










