正文
False
,
True
]
[
False
,
False
,
False
,
False
,
True
,
True
,
False
,
False
,
False
,
True
]
dog
:
5
True
fish
:
4
True
cat
:
9
True
bird
:
9
True
duck
:
5
True
emu
:
8
False
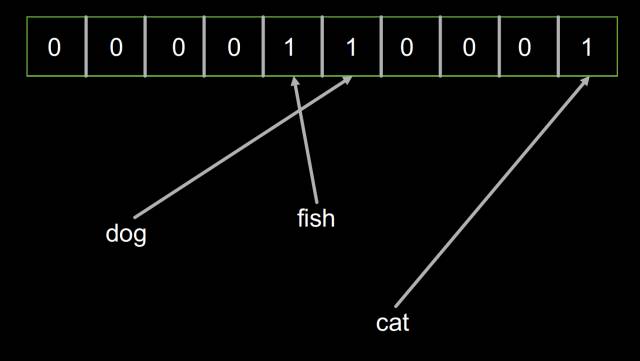
首先创建了一个容量为10的的布隆过滤器

然后分别加入 ‘dog’,‘fish’,‘cat’三个对象,这时的布隆过滤器的内容如下:
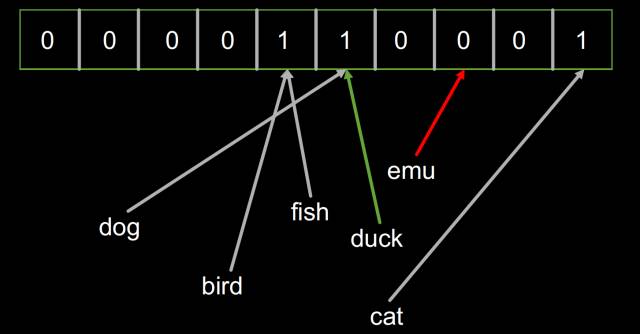
然后加入‘bird’对象,布隆过滤器的内容并没有改变,因为‘bird’和‘fish’恰好拥有相同的哈希。

最后我们检查一堆对象(’dog’, ‘fish’, ‘cat’, ‘bird’, ‘duck’, ’emu’)是不是已经被索引了。结果发现‘duck’返回True,2而‘emu’返回False。因为‘duck’的哈希恰好和‘dog’是一样的。
分词
下面一步我们要实现分词。 分词的目的是要把我们的文本数据分割成可搜索的最小单元,也就是词。这里我们主要针对英语,因为中文的分词涉及到自然语言处理,比较复杂,而英文基本只要用标点符号就好了。
下面我们看看分词的代码:
def major_segments
(
s
)
:
"""
Perform major segmenting on a string. Split the string by all of the major
breaks, and return the set of everything found. The breaks in this implementation
are single characters, but in Splunk proper they can be multiple characters.
A set is used because ordering doesn't matter, and duplicates are bad.
"""
major_breaks
=
' '
last
= -
1
results
=
set
()
# enumerate() will give us (0, s[0]), (1, s[1]), ...
for
idx
,
ch
in
enumerate
(
s
)
:
if
ch
in
major_breaks
:
segment
=
s
[
last
+
1
:
idx
]
results
.
add
(
segment
)
last
=
idx
# The last character may not be a break so always capture
# the last segment (which may end up being "", but yolo)
segment
=
s
[
last
+
1
:
]
results
.
add
(
segment
)
return
results
主要分割
主要分割使用空格来分词,实际的分词逻辑中,还会有其它的分隔符。例如Splunk的缺省分割符包括以下这些,用户也可以定义自己的分割符。
] < >( ) { } | ! ; , ‘ ” * \n \r \s \t & ? + %21 %26 %2526 %3B %7C %20 %2B %3D — %2520 %5D %5B %3A %0A %2C %28 %29
def minor_segments
(
s
)
:
"""
Perform minor segmenting on a string. This is like major
segmenting, except it also captures from the start of the
input to each break.
"""
minor_breaks
=
'_.'
last
= -
1
results
=
set
()
for
idx
,
ch
in
enumerate
(
s
)
:
if
ch
in
minor_breaks
:
segment
=
s
[
last
+
1
:
idx
]
results
.
add
(
segment
)
segment
=
s
[
:
idx
]
results
.
add
(
segment










