正文
在存储物理架构上,
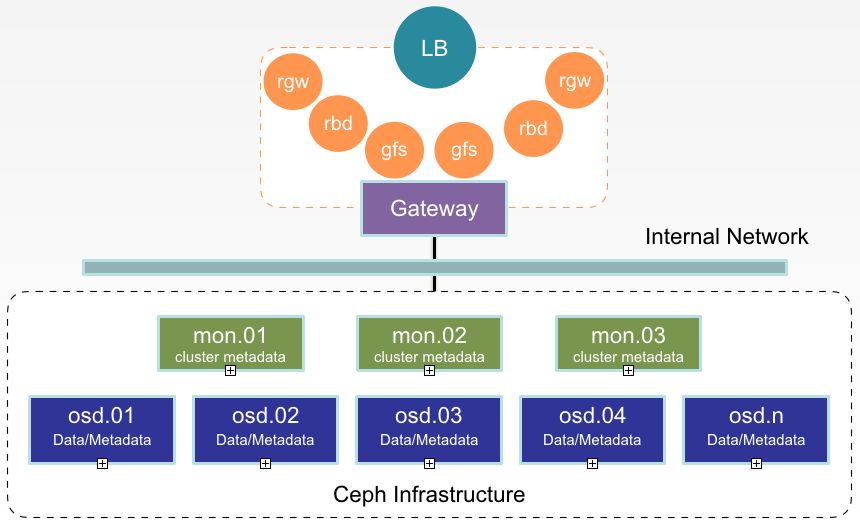
存储集群实现了3(monitor)+N(OSD)+2(client)的建设形式,实现角色隔离,功能分离,互不影响。
3个monitor节点配置有monitor和mgr服务,作为存储的大脑和监控使用。在N(数量可以线性扩展,所以未明确)个OSD节点上进行了一些优化,首先是磁盘的IO调度策略上。
SSD磁盘采用NOOP IO调度策略,NOOP遵循先入先出(FIFO)原则,对请求进行了简单的队列处理,NOOP对bio进行了后向合并,最大程度保证相邻bio进行合并处理,提高了效率。
SAS磁盘采用默认的DeadLine IO调度策略,Deadline调度策略对读和写进行区分,执行FIFO策略,每个请求会被分配一个时间戳,在读优先的情况下,可以知道哪个写请求已经长时间没有被调度,进行优先调度,避免了写饿死的情况发生。
其次,基于存储的读写策略设置,我们进行了OSD硬盘类型的混插,SSD硬盘和SAS硬盘按照1:2的比例配置,保证每次读操作都落在性能较好的SSD硬盘上,同时每次写操作也会相应提高效率。
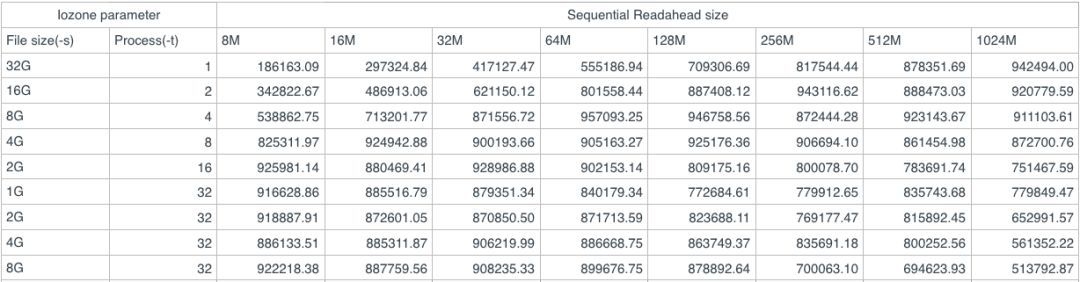
第三我们对读、写缓存和bluestore缓存进行了优化,增加了预读缓存、写缓存和bluestore缓存的大小,对整体性能表现提高很多。以下是预读缓存大小的一个性能测试:
第四我们对Bucket index进行了重新配置,修改crushmap,将其全部放置在ssd高速磁盘上。单个桶索引大概是200 bytes,当单个桶存放大量对象数据时,索引不进行单独分离或存放在高速磁盘上,会造成性能下降。因此,我们对crushmap进行导出,反编译,修改、重新编译,注入操作,使索引全部放置到ssd磁盘上,减少延迟,提高性能。
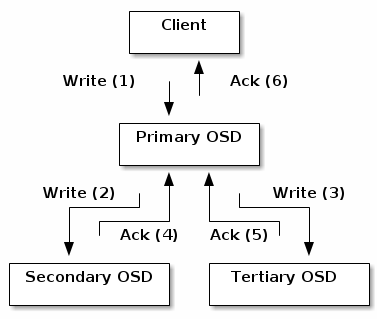
最后,我们为存储设计了一个网关,由两个节点组成,将我们的使用场景和存储本身完全解耦,即使存在配置失误或损坏,完全不会影响整个存储的健壮性和数据完整性。在网关节点上安装了Ceph rgw、Nginx和Pacemaker。由于业务对全局共享文件系统读写得需求,需利用高可用软件管理文件系统并对外暴露,供多个容器对同一文件系统进行挂载,读写数据。所以我们选择Pacemaker高可用软件对外提供唯一IP地址,保证服务唯一可访问性。众所周知,rgw单实例在可用性、扩展性和性能上存在低效问题,所以我们利用Nginx负载均衡改善效果。我们对外提供三种类型的基础存储服务,即对象存储、块存储、全局共享存储。
在存储性能优化设计方面,我们大概做了以上五点。当然,还有一些小的优化在这里就不详细介绍了,比如TCMalloc参数调整,ulimit参数调整,kernel pid_max参数调整等。





