正文
在Replication的默认实现中,源端会按照HLog的原始写入顺序进行回放。为了提升目标端的写入效率,我们将所有待发送的HLog先进行排序,使得同表同Region的数据都能合并处理,同时将目标端的数据写入尽量并行化。
尽管做了以上两点后,集群间的数据复制能力大大增强,但是个别服务器仍然会由于负载过大,而产生一定的复制延迟。从本质上来说,这是因为HBase的服务器分配了更多的资源服务于来自客户端的写入请求,当某个服务器成为集群中的写入热点并高负载工作时,这个节点的数据复制基本很难再消化庞大的写吞吐。这是一个曾困扰我们很久的问题,你可以用一些运维的方式去解决。比如开启更多的线程数,但这并不能总有效。因为服务于客户端的线程数,要远远大于Replication的线程数。再比如从热点服务器移走Region,降低吞吐与负载,但热点并不保证是恒定的,可能会跳跃在各个服务器,我们也开发了新的基于历史监控的负载均衡算法,以尽可能地让请求均衡。
很多时候,通过运维管理手段能够控制影响、化解问题,但当你需要维护上百个集群时,一点一滴的运维要求慢慢堆积成很高的壁垒。所以,我们尝试改进系统能力,用自动、一劳永逸地方式去解决热点下的数据复制积压问题。面对热点的基本思路是散列,在这个具体场景上,我们打破原先的自生产自推送的设计,利用整个集群的能力,使得热点服务器上积压的数据(HLog文件),能够由集群中的其他空闲服务器进行消化。
配置的在线调整不仅能极大提升运维幸福感,而且对于系统改进可以产生更加敏捷的反馈。这并不新鲜,但这是一项十分重要的能力,我们在系统改进的道路上也对其特别重视。HBase的Replication功能会有很多参数,我们将其全部优化为可在线调整,给日常的服务支撑带来了很大的价值。
多链路
业务多地多单元部署是阿里技术架构的一项重要特征,这要求基础存储具备数据链路的灵活流动性。今天,阿里HBase会在多地部署多集群,集群间数据相互流动,以满足单元化业务的需求。
在支持数据多链路的生产应用上,我们总结了以下几个要点。
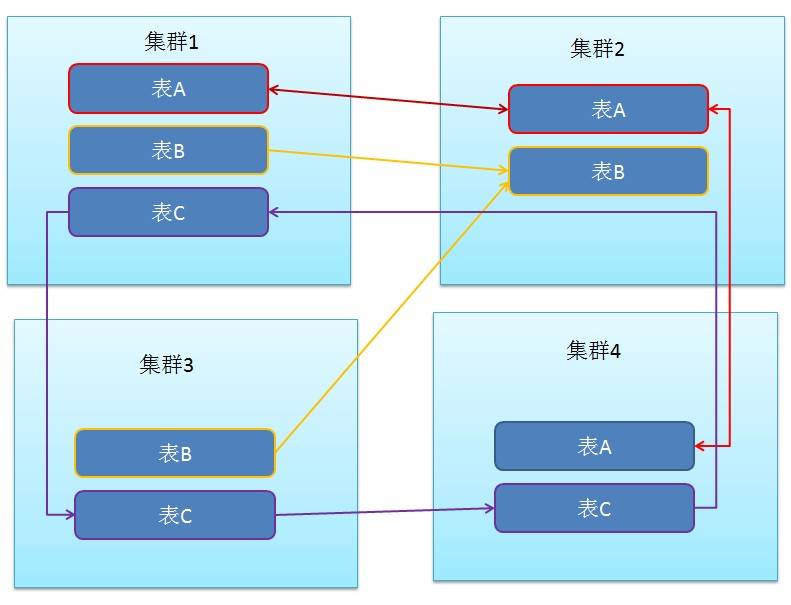
当一个HBase集群启用多个数据链路后,我们期望自由设置表的数据可以被复制到其中的一个或多个链路,使得整个数据的流动更加灵活。为此,我们增加了一种特性,通过设置表的属性,以决定该表的数据流向哪些链路,使得整个数据流动图可以由业务架构师任意设计,十分灵活。此外,当需要在集群间热迁移数据时,它也能带来十分重大的作用。 整体效果如下,以表为单位数据可以任意流动:
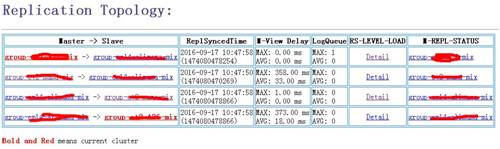
当数据可以在多个集群任意流动后,一个很迫切的需求是链路拓扑以及复制状况的可视。为此,我们强化了Replication的信息层,不仅源端保留它到多个目标的链路信息,而且每个目标端也会保留多个源端到它的链路信息,从而我们可以从任意一个集群绘制整个链路拓扑图。同时,我们极大丰富Replication的运行状况信息,并将之汇聚到HBase的Master节点,由其统一汇总展现,从中我们可以清晰得到数据是否积压、复制的性能瓶颈、节点间的均衡情况、具体的延迟时间等信息,其中复制的延迟时间是一个十分关键的信息。基本信息如图:
在数据多链路下,会产生一些循环复制的场景。比如集群A->B->C->A,这是一个简单的链接式复制,当数据流过某个集群时,HBase Replication会在数据中添加该集群ID的信息,以防止同一条数据被多次流经同一个集群,基于这个设计,即使复制链路存在环,数据也不会产生无限循环流动。但是,仍然有一个效率问题不得不提,对于ABCA这样一个数据链路,我们发现客户端写入到A集群的数据,在B集群和C集群上会被复制写入两次,一次通过A->B链路写入,另一次通过A->C->B链路写入。所以,为了避免这种写入放大,需要在链路部署上防止产生这种环。在过去实践的一些场景,发现这种环状链路不得不存在,所以系统层面,我们也对Replication做了相关优化,以去除这种写入放大。
当源集群配置了多个数据链路后,我们总是期望这些链路之间相互隔离,不会因为一个链路的积压影响其他链路。在大多数时候,这一切都如预期工作,但当集群故障时,糟糕的事情发生了,我们发现一个异常链路会阻塞全部链路的复制恢复,究其原因,是因为在数据复制的恢复期间,很多资源是所有链路共享的。所以,这些资源的链路解耦成为我们的工作,同时,也好好对数据复制的宕机恢复速度进行了优化。
数据的一致性
今天,大多数生产系统会使用异步方式去实现集群间的数据复制,因为这样效率更高、逻辑更清晰。这意味着,集群间数据是最终一致模型,当流量从主切换到备,从备上无法访问完整的数据,因为复制存在滞后,并且当主集群永久不可恢复,数据也会存在部分丢失。
为了满足业务场景的强一致需求,我们采用了两种方式。
第一种,异步复制下的强一致切换。虽然备集群的数据集滞后于主集群,但是在主集群网络健康的情况下,仍然可以保障切换前后数据的强一致。其基本过程如下,首先让主集群禁止数据写入,然后等待主集群的数据全部复制备集群,切换流量到备集群。这里存在两个依赖,一个是集群的写入控制功能(支持禁止来自客户端的数据写入),另一个是复制延迟的确定性,虽然数据是异步复制的,但是我们将数据的复制时间点明确化,即该时间点之前写入的数据已经完全复制到了备集群。
第二种,数据复制使用同步的方式。即当数据写入返回客户端成功后,能保证数据在主备集群均已写入,从而即使主集群完全不可恢复,数据在备集群中也能保证完整。
为了满足类似场景的需求,阿里HBase研发了同步方式的集群间数据复制,具体内容可参考下一节。
冗余与成本
数据在集群间的冗余复制,给系统的可用性带来了数量级的提高,但同时也意味着更大的成本开销,在保证可用性下如何优化成本是一个需要重点思考的问题,阿里HBase在这方面投入了较大精力的尝试,具体内容将在接下来的”性能与成本”章节进行介绍。
集群同步复制










