正文
况且,我们在转到 JSON 之后还获得了更多的特性,比如协议版本。有时候,当我们在新版本的协议上使用 protobuf 时,客户端也必须改用 protobuf。如果你有数百个服务,就算只有 10% 的服务进行了迁移,这也会引起很大的连锁反应。你在一个服务上做了一些变更,就会有十多个服务也需要跟着改动。
因此,我们就会面临这样的一种情况,一个服务的开发人员已经发布了第五个、第六个,甚至第七个版本,但生产环境里仍然在运行第四个版本,就因为其他相关服务的开发人员有他们自己的优先级和截止日期。他们无法持续地更新他们的服务,并使用新版本的协议。所以,新版本的服务虽然发布了,但还派不上用场。然后,我们却要以一种很奇怪的方式来修复旧版本的 bug,这让支持工作变得更加复杂。
最后,我们决定停止发布新版本的协议。我们提供协议的基础版本,可以往里面添加少量的属性。服务的消费者开始使用 JSON schema。
标准看起来是这样的:

我们没有使用版本 1、2 和 3,而是只使用版本 1 和指向它的 schema。
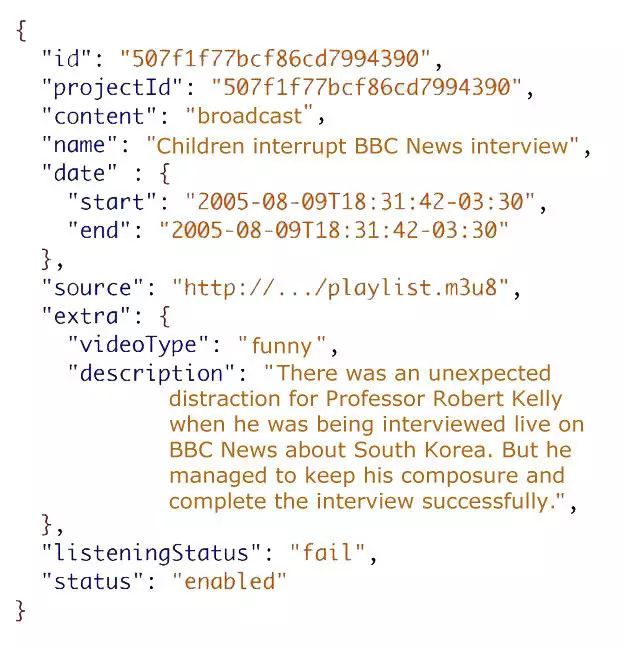
这是从我们服务返回的一个典型的响应结果。它是一个内容管理器,返回有关广播的信息。这里有一个消费者 schema 的例子。
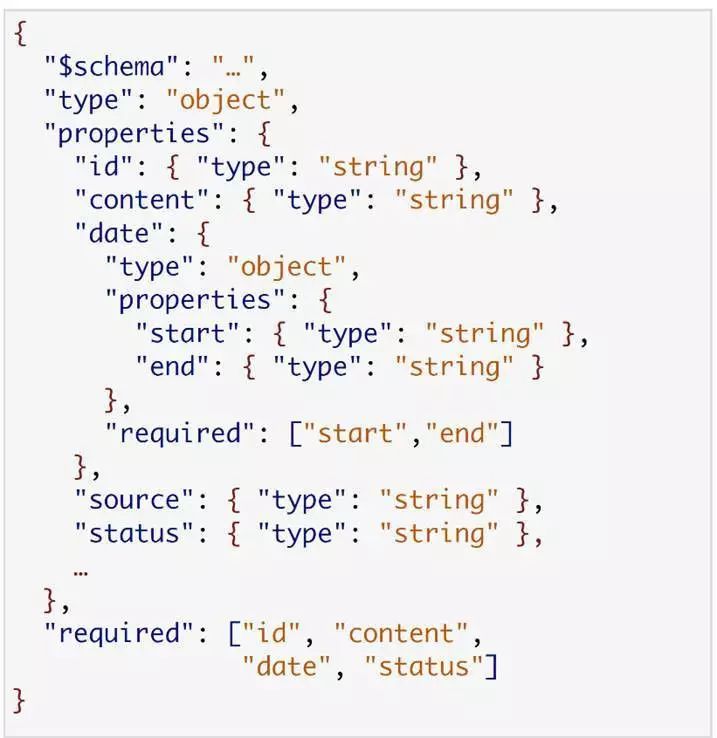
最底下的字符串最有意思,也就是"required"那块。我们可以看到,这个服务只需要 4 个字段——id、content、date 和 status。如果我们使用了这个 schema,那么消费者就只会得到这样的数据。

它们可以被用在每一个协议版本里,从第一个版本到后来的每一个变更版本。这样,在版本之间迁移就容易很多。在我们发布新版本之后,客户端的迁移就会简单很多。
下一个重要的议题是系统的稳定性问题。这是微服务和其他任何一个系统都需要面临的问题(在微服务架构里,我们可以更强烈地感觉到它的重要性)。系统总会在某个时候变得不稳定。
如果服务间的调用链只包含了一两个服务,那么就没有什么问题。在这种情况下,你看不出单体和分布式系统之间有多大区别。但当调用链里包含了 5 到 7 个调用,那么问题就会接踵而至。你根本不知道为什么会这样,也不知道能做些什么。在这种情况下,调试会变得很困难。在单体系统里,你可以通过逐步调试来找出错误。但对于微服务来说,网络不稳定性或高负载下的性能不稳定性也会对微服务造成影响。特别是对于拥有大量节点的分布式系统来说,这些情况就更加显而易见了。
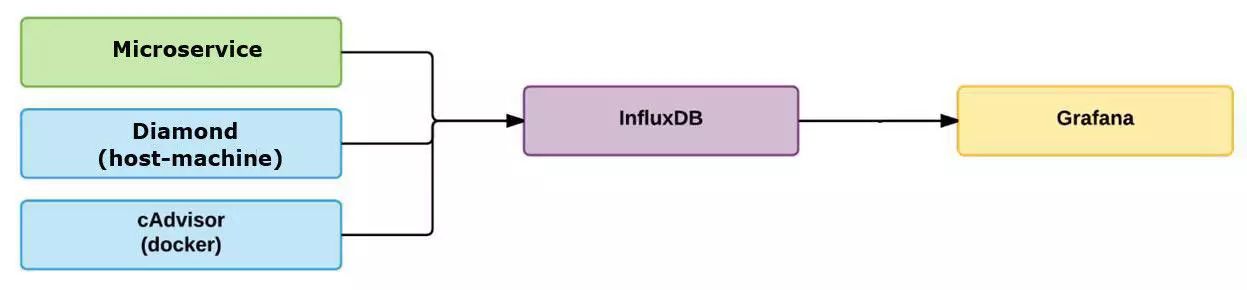
在一开始,我们采用了传统的办法。我们监控所有的东西,查看问题和问题的发生点,然后尝试尽快修复它们。我们将微服务的度量指标收集到一个独立的数据库里。我们使用 Diamond 来收集系统度量指标。我们使用 cAdvisor 来分析容器的资源使用情况和性能特征。所有的结果都被保存到 InfluxDB,然后我们在 Grafana 里创建仪表盘。
于是,我们现在的基础设施里又多了三个组件。
我们比以往更加关注所发生的一切。我们对问题的反应速度更快了。不过,这并没有阻止问题的出现。
奇怪的是,微服务架构的主要问题出在那些不稳定的服务上。它们有的今天运行正常,明天就不行,而且有各种各样的原因。如果服务出现超载,而你继续向它发送负载,它就会宕机一段时间。如果它在一段时间不提供服务,负载就会下降,然后它就又活过来了。这类系统很难维护,也很难知道到底出了什么问题。
最后,我们决定把这些服务停掉,而不是让它们来回折腾。我们因此需要改变服务的实现方式。
我们做了一件很重要的事情。我们对每个服务接收的请求数量设定了一个上限。每个服务知道自己可以处理多少个来自客户端的请求(我们稍后会详细说明)。如果请求数量达到上限,服务将抛出 503 Service Unavailable 异常。客户端知道这个节点无法提供服务,就会选择另一个节点。
当系统出现问题时,我们就可以通过这种方式来减少请求时间。另外,我们也提升了服务的稳定性。
我们引入了第二种模式——回路断路器(Circuit Breaker)。我们在客户端实现了这种模式。
假设有一个服务 A,它有 4 个可以访问的服务 B 的实例。它向注册中心索要服务 B 的地址:“给我这些服务的地址”。它得到了服务 B 的 4 个地址。服务 A 向第一个服务 B 的实例发起了请求。第一个服务 B 实例正常返回响应。服务 A 将其标记为可访问:“是的,我可以访问它”。然后,服务 A 向第二个服务 B 实例发起请求,不过它没有在期望的时间内得到响应。我们禁用了这个实例,然后向下一个实例发起请求。下一个实例因为某些原因返回了不正确的协议版本。于是我们也将其禁用,然后转向第四个实例。
总得来说,只有一半的服务能够为客户端提供服务。于是服务 A 将会向能够正常返回响应的两个服务发起请求。而另外两个无法满足要求的实例被禁用了一段时间。
我们通过这种方式来提升性能的稳定性。如果服务出现了问题,我们就将其关闭,并发出告警,然后尝试找出问题所在。
因为引入了回路断路器模式,我们的基础设施里又多了一个组件——Hystrix。