正文
这些是SRE跟传统的运维模式最不同的一点,就是招的人研发为主,做的事也是以研发为主。这是当时SRE成立背后的故事,这些年来我认为他们做得最好的一点是一直在维持了一种平衡。
将运维部门从传统执行部门往上提升,打破了传统的界限
。就像刚才说的DevOps,很多人理解为就是让研发部门做运维的事,或者运维部门做研发的事情,但实际上DevOps在国外的定义更宽泛一点。DevOps的思想更多的是说把整个开发流程的界限打通,产品有的时候也要干一些研发的事,研发有时候把这个信息要很快的反馈给这个产品,开发和运维或者QA和运维之间的界限也打通。所以现在去搜DevOps的图片,会发现IBM这些人都在讲圈圈,说以前是产品研发都是一条线直着来,而现在都是转圈的,这就是DevOps理论。
按照这个理论来说,SRE就是DevOps的思想在开发和运维之间的一个平衡。

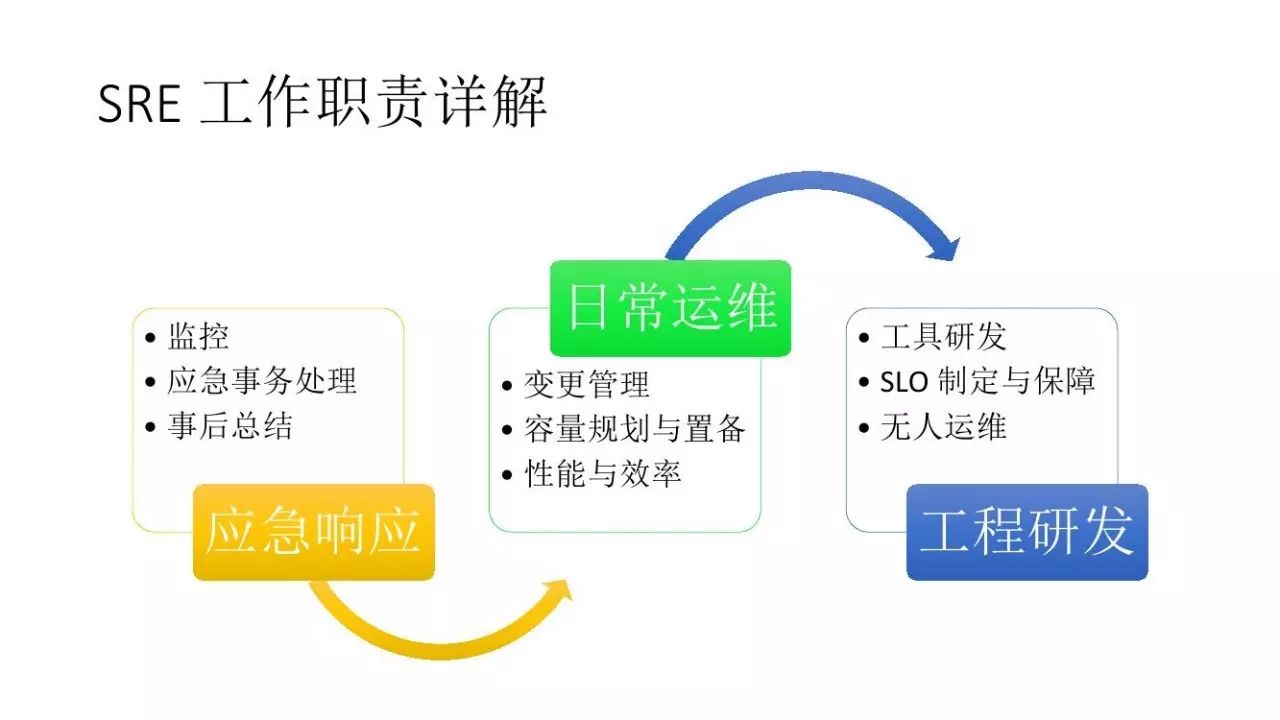
这个图是我发明的,书中没有提到。书里大概有二十多章的内容是在讲SRE的各种日常工作,简单提了一下它的金字塔模型,于是我归纳总结了一下。这里是由下至上,下面的事份额比较大一点,上面的事份额比较小一点,分了三类。第一类,运维部门最重要的是应急响应这个问题,因为业务越来越大,与运营的结合越来越紧密,很多时候要处理的事情更多的是商业和运营上的事,也包括软件上的问题,这个部门最特殊或者最唯一的职责就是应急响应。之上是日常运维,保证机器能够正常更新、快速迭代。再往上是输出一些工程研发,无论是做工具,还是做高可用架构、提高可靠性,这些都是最上层的东西,只有把底下全部做好了才能说到上面。
应急响应
应急响应是运维部门在公司最独特的一点,表现为当公司出现问题时,应该找谁或者流程应该是怎样的。我回国之后见了不少初创企业,他们网站出问题了,往往是CEO先发现,CEO打电话“哎,这个到底是怎么回事啊”,然后每一个人都说“不知道啊,不是我负责呀,我得找谁谁”。不管多大一件事都得传遍整个公司,整个效率非常混乱。
我在Google待了八年时间,这样的流程也经历过,但是最近这几年Google非常重视这一点,建立了一整套应急事件处理方式。首先要有全面监控,监控这件事情是持久不断的,重中之重。SRE所有人都要非常了解整个监控系统在所有业务中的部署实施,其实这是我们平时花精力最多的地方。监控系统里面对整个系统所有方面都有监控,不光包括业务指标,也包括性能指标、效率指标。监控应该平台化、系统化,不停的往上积累,多做一些模板,同质化的系统就可以用同样的方法去做监控。
第二点是应急事务处理,
应急事务处理分两部分,第一部分是演习,另外一部分是真正的处理流程
。如何把它做好?实际上就是要不停的去演习、去做这个事情。像刚才举的例子,网站挂了,首先不应该CEO先发现,而应该是监控系统或者报警系统先告警,在发现之前就很应该明确这个东西应该谁排查,谁处理,这个信息应该早就发给合适的人去处理,甚至他应该早就在做了。如果发生特别大的,需要跨部门之间协作的问题,那不应该只是领导现场调配,而是整个组织每个人都明白这个流程应该是怎么样的,直接就做。
Google甚至可以做到在一次事故中间两地交班,某个团队处理一半,然后我交接给另外一边团队,就下班回家了,持续不停的有人继续跟踪处理这件事情,而不会出现问题
。这样一个模式是我觉得非常值得我们思考的。
处理完问题之后,要总结。之前听过的一个故事是,某公司业务出现了一个事故,大家加班加点,十几个小时没睡觉把这事搞定,然后领导过来就说了一句“大家辛苦了,回家睡觉吧”。但是,其实在这个时候我要说,领导光说这个其实恰恰是不够的。领导在这里应该问:为什么加班啊?这个事情为什么会发生啊,下次能不能不发生,大家能不能不加班,能不能不熬夜?这样才对, 能做到事后总结这个事情很难,但只有把这个做好了,才能降低以后问题发生的几率。
日常运维
日常运维做得最多的可能是变更管理。业务现在发展非常快,迭代速度、迭代周期非常快。其实这件事情能做好,能够做到无缝、安全、不停的变更管理,是运维部门能给公司做的最大贡献。
第二个,容量规划,当规模大到一定程度的时候,就需要有人来回答这个问题——到底要买多少新机器,能否保证明年的性能、效率,那谁来负责这件事呢?SRE部门提出这些方案,然后要确保这些指标、这些东西是有数据支撑的,确实能解决问题的。
工程研发
工程研发虽然做得少,但是工作很关键。
SRE在工程研发上主要的工作,首先是帮产品部门确定一个SLO
。SLO是一个服务指标,每一个产品都有一个服务指标。任何系统都不可能是百分之百可靠的,也没有必要做到百分之百可靠。这里得有一个目标,比如说可以每个月中断几分钟。这件事情是要产品部门考虑清楚的。比如我之前在YouTube做视频存储、视频点播的时候,要考虑每个视频到底是存一份还是存两份的问题,将这种问题放到一个非常大的部署规模里面的时候,只有产品部门能够拍板。说到底是要不要花这个预算,要不要花这么多钱去提高0.1%的可靠性或者0.01%的可靠性。
另外一点是无人化运维。大家都看过《黑客帝国》吧?一醒来发现大家都是电池,都是为机器服务的。其实把这个比喻放在运维部门非常合适。因为如果不停的开发出需要人来操作运维的系统,结果大家最后都是电池,明显是不可持续的。如果不停的产生这种需要人来操作的东西,不停的招人,最后就变成不停的运维这个东西。把整个流程自动化,建立一个能够应对复杂业务的平台,这就是工程研发上最需要的东西。





