正文
SMT 以词和短语为单位进行翻译,是 NMT 出现前的上一代最佳模型,主要依赖于对大量语料进行统计找出规律,SMT 模型相比于 NMT 模型规模较小,能够保存在本地,以 Microsoft Translator 的 iOS 版本为例,一个简体中文离线包的大小是 205MB。
而为华为特别开发的这一款 Microsoft Translator 的特别之处就在于,其文本翻译和图像翻译模式均采用了离线的神经机器翻译模型。
这一原先仅仅能通过微软 Cognitive Services API 调用的,部署在微软云上的神经机器翻译系统,采用了惯用的多层 LSTM 编码器、注意力(attention)算法和解码器组成的系统。

图:LSTM 编码器 + 注意力模型 + 解码器系统演示
这类复杂的神经网络通常带有数以百万计的参数,每次解码过程需要进行大量的运算,通常都会以云端的 CPU 或 GPU 进行。例如,谷歌翻译利用 GPU 进行推理,有道翻译利用 CPU 进行。而开发一款神经机器翻译系统最大的障碍之一就是推理速度。谷歌和有道的工程师都曾表示,开发的初期阶段,模型虽然准确率很高,但翻译一句话需要 10 秒钟甚至更多。这使得系统完全达不到「可用」的标准。工程师们投入了大量的精力对模型做不影响效果前提下的修改和简化,才让部署在云端处理器上的系统变得可用。而这一次,微软的工程师直接将这个原本难倒了大型 CPU 和 GPU 的模型放在了移动端芯片里。
微软将模型中最耗费计算资源的 LSTM 编码器用深层前馈神经网络(deep feed-forward neural network)替代,
转换为大量低运算难度的可并行计算,充分利用华为 NPU 能够进行大规模并行计算的特点,让 NPU 在神经网络的每一层中同时计算神经元的原始输出和经过 ReLU 激活函数的非线性输出,由于 NPU 有充足的高速存储空间,这些计算可以免受 CPU 与 NPU 间数据交换的延迟,直接并行得到结果。
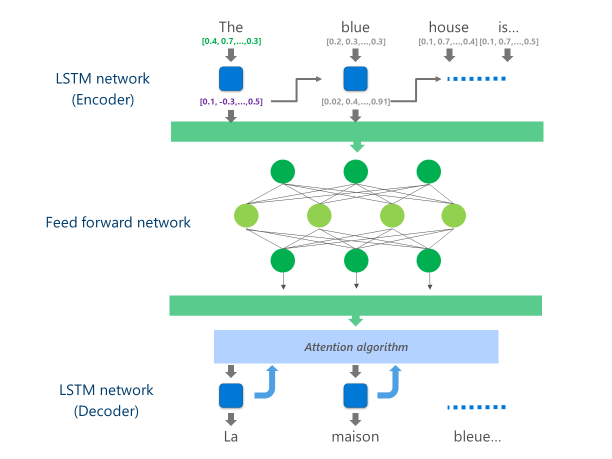
图:替代后的翻译模型
搭载于最新的 Mate 10 系列上的麒麟 970 芯片及其内置的 AI 专用处理单元 NPU,是华为第一次在移动设备的层面上把机器学习硬件计算加速能力叠加进芯片中去,也让 Mate 10 成为全世界的消费者拿到的第一款有专用于进行人工智能方面计算的处理单元的手机。
黄学东表示,从手机 CPU 到 NPU 有接近 300% 的计算加速,正是这个加速让神经网络在终端设备上的离线推理越过了阈值,从不可能变成可能。
以前在 CPU 时代,离线操作就要承受巨大的性能损失,而在线服务就无法脱离开对网络的依赖。尤其是翻译这样一项服务,很多应用场景都并没有稳定的网络支持,是需要有强大的离线功能存在的。而华为手机的用户大多为商务人士,很多应用场景都在国外,网络条件并不能得到保障,离线功能可以说是必不可少。
因此微软的工程师联合华为的工程师,对现有的神经翻译模型进行了层数、模型结构、工程实现方法等多方面优化,能够在大幅减小所需运算量的情况下让离线模型效果可以媲美在线模型,「大家应该感觉不出来二者的差距」,黄学东说。同时也研究了如何更好地同时使用 NPU 与 CPU :利用 NPU 完成推理工作,利用 CPU 辅助程序所需的其他操作。










