正文
这次特别针对Agentic AI UX,联发科又发起了“天玑智能体化体验领航计划”,会上能看到的参与企业除了联发科自己,还有摩托罗拉、荣耀、面壁智能、OPPO、vivo、阿里云、小米、传音、微软等。陈冠州说,期望在天玑技术的基础上,与合作伙伴一起,在2-3年内实现Agentic AI UX的愿景。
那么联发科心目中的Agentic AI UX智能体化AI用户体验究竟是什么样?或者说基于reasoning model解上面那道数学题的雏形,转向协助日常使用体验时,AI手机又会是什么样?
手机上的Agentic AI能做到什么?
徐敬全在大会主题演讲的圆桌环节坦言,即便AI手机“朝着非常正向、以超出预期的速度发展”,但在AI手机上还没有出现真正的杀手级应用(killer application),“很多地方还是需要行业一起努力”。
我们对这个问题的看法一向是乐观的,这种乐观基于两个此前多番讨论的明确趋势:(1)国外研究机构的数据显示过去4-5年内,LLM每百万token推理成本下降了1000多倍(从GPT3大几十美元的推理价格,到Llama3.2的不到0.1美元);(2)AI模型要达成相同能力,所需算力每年降低4-10倍。
圆桌环节,李大海(面壁智能联合创始人兼CEO)也提到,“同尺寸下,模型能力在快速提升。”他举例去年还需要在云上才能达成的AI能力,今年就能在端侧实现。陈冠州也说过去“几百几十B参数量的大语言模型能做到的事,现在几个B就能做到”。
基于此,我们说AI效率提升、使用成本下降。这会带动更多行业、场景普及AI,更重要的是带动应用层面的创新——这些创新甚至可能是现在的人们意想不到的——就像半导体行业摩尔定律高速推进时,相继出现互联网、智能手机等杀手级应用。所以在我们看来,AI手机、AI PC的杀手级应用出现,只是时间问题。且文首提及联发科畅想中的Agentic AI UX体验,本身已经包含有提升生活、工作、娱乐质量的重要特性了。只不过这其中还缺一环:生态。
陈冠州在开场演讲中提到:“手机里有着不同的场景:购物、游戏、创作等等。现在这些场景和特定应用是绑定关系,一个场景一个应用。”而随着AI Agentic UX的普及,“这些场景会被模糊化。智能体本身可以提供无缝、智慧的出色体验,覆盖各类应用场景。”这是个很理想的发展方向。但我们知道,这一目标涉及到AI模型,与应用、用户双方的互动,自然需要手机整个系统层面的架构、软硬件方案的共同演进。
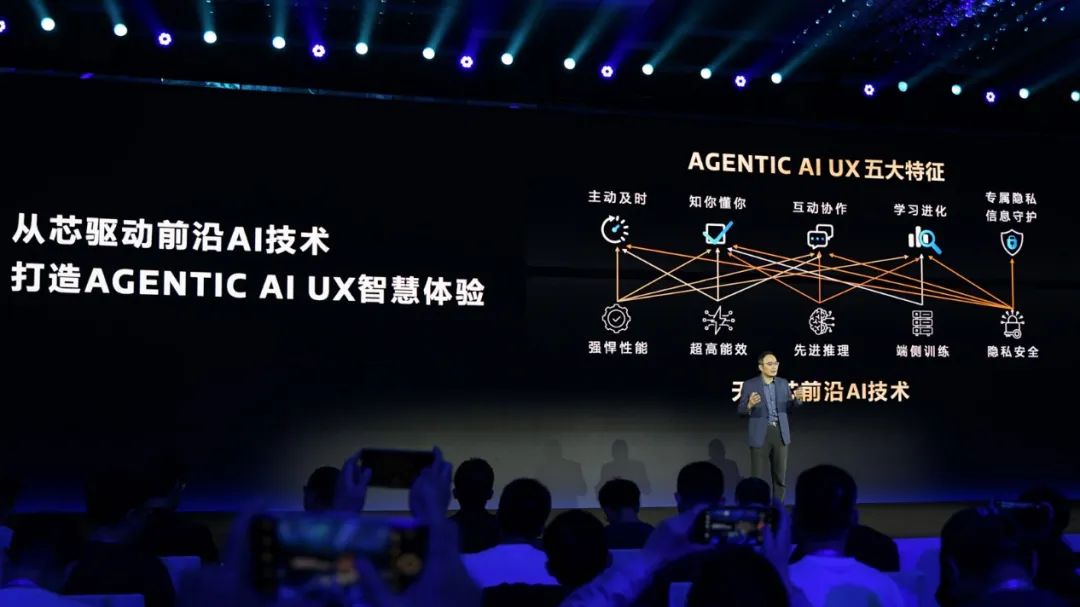
所以说到底,Agentic AI UX的实现,关键问题仍是生态建设:这也是联发科目前努力着手在做的。那么联发科期望能够达成的Agentic AI UX具体是什么样的,或者说潜在的AI手机可以达成哪些智能体化的体验?联发科自己将其总结为“五大特征”,分别是主动及时、知你懂你、互动协作、学习进化、专属隐私信息守护。
在联发科看来,手机本身就存储了一些“静态资讯”——如用户行事历中记录的行程安排;与此同时手机也在不停接收各种“动态资讯”,如微信、电话等。“比如我太太给我发短信,让我下班去接小孩。AI助手看到这则动态资讯以后,会去检查已有的行程安排,如果发现我晚上有其他安排,那么就可能直接回复我太太,无法去接小孩放学。”陈冠州举例说。
这一例体现的就是“主动及时”,相较于过去AI只能做被动响应,手机具备了同时处理“动态”与“静态”信息的能力;而“知你懂你”,即AI助手有能力发现用户的潜在需求,而非仅基于片段的机械化理解——如前文提到顺道买水果的例子,也都可以基于这样的能力去实现;
“互动协作”体现在文首所述AI助手基于用户的未来行程及运动历史,在用户点餐时提醒用户“控制体态”——这也是Agentic AI具备上下文理解能力,同时处理动态、静态信息的范例;“学习进化”是指对上述三项能力的持续跟进,“越用越懂你、越用越主动”,真正实现个人化的需求定制;当然,掌握主动和被动信息的手机,此时相比任何人都更了解用户,自然就要求“专属隐私信息守护”。
这“五大特征”在联发科看来,是未来通往GAI(通用人工智能)的组成部分。“AI从对话式,到现在能做逻辑推理,并且理解人类更深层的需求——AI就是大脑。未来所有的终端都会装上大脑,大脑陪伴着用户、了解用户、服务用户。”陈冠州说,联发科每年芯片出货面向的数十亿边缘设备,都会成为AI体验的重要载体。而这些需要“OEM、AI模型、应用合作伙伴一起努力,才有机会实现这样的愿景”。
实际上,去年联发科召开首届MDDC大会,背景也在于此。
端侧AI开发工具情况如何?
MDDC作为开发者大会,面向开发者时,为Agentic AI UX构建生态的起点就是开发工具。李彦辑谈到,天玑AI开发套件发布以来年度下载量增长了5倍,获得CSDN 2024年度开发工具奖,而且相比“S公司开发套件”和“Q公司开发套件”,开发者“推荐排名”第一。所以我们也有必要看看天玑开发工具走到哪一步了,这也有利于我们了解当代端侧AI开发工具的发展水平。
从AI模型角度来看,天玑AI开发套件v2.0增加了大量新的模型支持,包括LVM视觉大模型、LLM大语言模型——如前文提到的DeepSeek R1不同参数规模的蒸馏模型,以及MiniCPM, Qwen2, Hunyuan等主流端侧模型;另外“优化技术”部分也升级了很多项目,如真正意义上端侧的LoRA fine-tune支持,前文提到的SpD+(增强型推测解码),和随DeepSeek爆火现在也很火的MLA(多层注意力架构)、MoE等;还有更灵活的“大模型工具箱”...

稍谈一谈更灵活的大模型工具箱,陈柏谕(Mediatek AI资深技术专家)在技术演讲中说,这是从固定参数化控制 → 灵活性的转变:旧版的工具箱主要通过参数调整来做模型适配设定,以相对固定的方式去支持模型架构,只能适配已知模型。
所以天玑AI开发套件v2.0的新版大语言模型工具箱,在保留参数调整特性的前提下,“开放了Python代码直接控制”,“开发者可以通过这种方式在天玑平台适配自己的新模型”。陈柏谕说这种转变能够节省6-8周的开发时间。
就reasoning model逻辑推理模型的支持,这里有几点是特别值得一说的。
其一是增强型推测解码加速(SpD+, Speculative Decoding Plus)——SpD+在本届开发者大会上被反复提及。SpD本身是一种加速LLM推理过程的技术,相比传统单次生成1个token,基于“draft-then-verify”的方法来做加速。










