正文
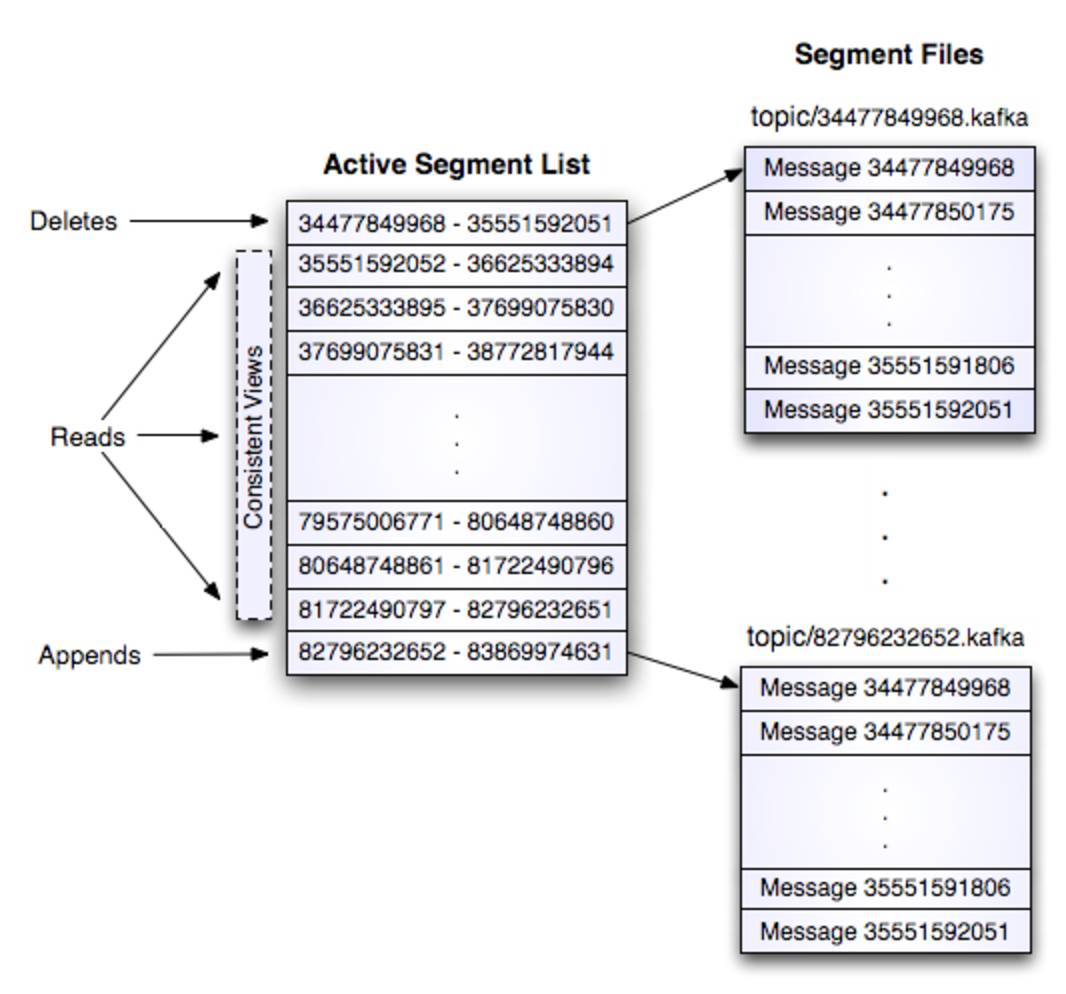
Kafka删除策略
1)N天前的删除。
2)保留最近的MGB数据。
Kafka broker
与其它消息系统不同,Kafka broker是无状态的。这意味着消费者必须维护已消费的状态信息。这些信息由消费者自己维护,broker完全不管(有offset managerbroker管理)。
以下摘抄自kafka官方文档:
Kafka Design
目标
1) 高吞吐量来支持高容量的事件流处理
2) 支持从离线系统加载数据
3) 低延迟的消息系统
持久化
1) 依赖文件系统,持久化到本地
2) 数据持久化到log
效率
1) 解决”small IO problem“:
使用”message set“组合消息。
server使用”chunks of messages“写到log。
consumer一次获取大的消息块。
2)解决”byte copying“:
在producer、broker和consumer之间使用统一的binary message format。
使用系统的pagecache。
使用sendfile传输log,避免拷贝。
端到端的批量压缩(End-to-end Batch Compression)
Kafka支持GZIP和Snappy压缩协议。
The Producer
负载均衡
1)producer可以自定义发送到哪个partition的路由规则。默认路由规则:hash(key)%numPartitions,如果key为null则随机选择一个partition。
2)自定义路由:如果key是一个user id,可以把同一个user的消息发送到同一个partition,这时consumer就可以从同一个partition读取同一个user的消息。
异步批量发送
批量发送:配置不多于固定消息数目一起发送并且等待时间小于一个固定延迟的数据。
The Consumer
consumer控制消息的读取。
Push vs Pull
1)producer push data to broker,consumer pull data from broker
2)consumer pull的优点:consumer自己控制消息的读取速度和数量。
3)consumer pull的缺点:如果broker没有数据,则可能要pull多次忙等待,Kafka可以配置consumer long pull一直等到有数据。
Consumer Position
1)大部分消息系统由broker记录哪些消息被消费了,但Kafka不是。
2)Kafka由consumer控制消息的消费,consumer甚至可以回到一个old offset的位置再次消费消息。
Message Delivery Semantics
三种:
At most once—Messages may be lost but are never redelivered.
At least once—Messages are never lost but may be redelivered.
Exactly once—this is what people actually want, each message is delivered once and only once.
Producer:有个”acks“配置可以控制接收的leader的在什么情况下就回应producer消息写入成功。
Consumer:
* 读取消息,写log,处理消息。如果处理消息失败,log已经写入,则无法再次处理失败的消息,对应”At most once“。
* 读取消息,处理消息,写log。如果消息处理成功,写log失败,则消息会被处理两次,对应”At least once“。
* 读取消息,同时处理消息并把result和log同时写入。这样保证result和log同时更新或同时失败,对应”Exactly once“。
Kafka默认保证at-least-once delivery,容许用户实现at-most-once语义,exactly-once的实现取决于目的存储系统,kafka提供了读取offset,实现也没有问题。
复制(Replication)
1)一个partition的复制个数(replication factor)包括这个partition的leader本身。
2)所有对partition的读和写都通过leader。
3)Followers通过pull获取leader上log(message和offset)
4)如果一个follower挂掉、卡住或者同步太慢,leader会把这个follower从”in sync replicas“(ISR)列表中删除。
5)当所有的”in sync replicas“的follower把一个消息写入到自己的log中时,这个消息才被认为是”committed“的。
6)如果针对某个partition的所有复制节点都挂了,Kafka选择最先复活的那个节点作为leader(这个节点不一定在ISR里)。
日志压缩(Log Compaction)
1)针对一个topic的partition,压缩使得Kafka至少知道每个key对应的最后一个值。
2)压缩不会重排序消息。





