正文
接下来我先总结一下前面说过的内容。
对于不同类型的分类方法,标注的成本有高有低,所取得的分类准确率也有高有低。对于监督分类,能够取得很高的分类准确率但同时标注的成本非常高;而对于半监督和非监督分类,标注的成本都比较低(甚至没有),但取得的分类准确率并不高。
如何让左下角的这两种方法(即半监督和非监督分类)能够取得较高的分类准确率,同时保持比较低的标注成本?
这是我们所面临和需要解决的难题。
现在深度学习技术非常热门,但我今天讲的东西不是深度学习,这并不是说要忽视深度学习,其实这个话题跟深度学习也是有关系的。
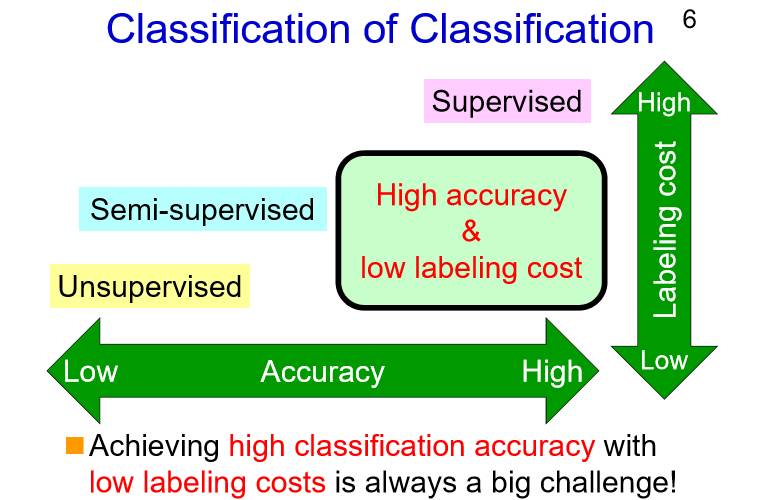
模型方面,从简单到复杂,我们有线性模型、增量模型、基于核函数的模型和深度学习模型等;机器学习方法方面,有监督学习、无监督学习、半监督学习和增强学习等。
任意的学习方法和模型都是可以相结合的,不过我今天要讲的东西是关于学习方法的,它可以使用任何的模型,包括深度学习模型。当然我更倾向于使用线性模型,因为这更简单,如果你想使用更加复杂的模型也是完全可以的。
弱监督学习的研究进展
下面是今天演讲的议程,接下来会给大家介绍四种不同的分类方法,后面如果有机会我会介绍一下理化学研究所AIP研究中心。

UU数据分类
首先看一下UU (Unlabeled, Unlabeled) 分类,U代表的无标注的数据(Unlabeled data)。
那么我们是怎样对无标注的数据进行分类的呢?假设我们有两个未标注的数据集,它们唯一的不同在于类先验(class-priors,即所属的类别)的不同。它们的函数分布如图中的左右下角,数量上各占50%左右,其实我们并不需要知道具体的比例。基于这种假设,我们需要训练一个分类器,而基于无标注数据的训练是极具挑战的。

那么怎么训练分类器呢?
首先来看一下类先验的区别是什么,在正类和负类之间,我们只看p(x)和p’(x)之间的差异,这就是我们划分正负类的标准。
假设通过某些技术方法,我们能够获取这些数据的正负类分布的先验信息,正负类的分布比例是对等的,也就是说一半数据是正类,一半是负类。x代表非标注的数据,C是一个常数,由于没有相应的标注数据,所以我们对C的值难以有个合理的估计。尽管如果C没有具体的值,我们不知道哪一侧是正类,哪一侧是负类,但这并不要紧,因为类别之间的差异性往往很明显,最终表现在符号为正或负,所以我们有时可以将常数C忽略掉。我们只看最终符号的正负,这样可以让我们得到最优的分类结果。

接下来的做法都是很直观的。因为我们要处理的是一些未标注数据,第一种方法是做核密度的估计,我们对两类数据点对应的p(x)和p’(x)进行估计,从而计算它们之间的差值,这样能够很自然地解决分类问题。然而,遗憾的是这种方法虽然简单,但有可能对p(x)-p’(x)的差值产生了低估,这是因为对p(x)和p’(x)的估计函数过于平滑所导致的。
第二种方法是直接对密度的差值进行估计,利用Kim等人所提出的模型,尽可能把密度差异的估计偏差达到最小,这种方法用一个线性的模型就能够得到相应的解决方案。










