正文
4列为餐后血清胰岛素(单位:mm)
5列为体重指数(体重(公斤)/ 身高(米)^2)
6列为糖尿病家系作用
7列为年龄
8列为分类变量(0或1)
多数情况下,预测模型的基准水平大约为65%的分辨精度,最高则能达到接近77%的分类精度。
数据集的前五组观测值如下所示:

该数据集已知存在缺失值,某些列中存在的缺失值被标记为0。通过这些列中指标的定义和相应领域的常识可以证实上述观点,譬如体重指数和血压两列中的0作为指标数值来说是无意义的。
点击此处下载数据集
到你的当前工作路径,并重命名为pima-indians-diabetes.csv。
2、标记缺失值
在这一部分,我们将学习如何鉴别和标记缺失值。
借助散点图和统计指标,我们能够识别缺失或损坏的数据。
如下图所示,先将数据加载到Pandas模块提供的DataFrame中,然后打印出每个变量的统计信息。

运行上述代码将产生以下结果:
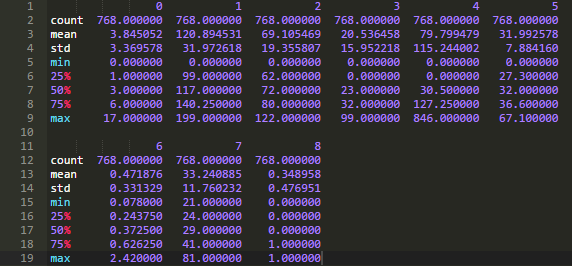
这个结果非常有用:从结果中我们可以看到很多列的最小值为0。而在一些特定列代表的变量中,0值并没有意义,这就表名该值无效或为缺失值。
具体来说,下列变量的最小值为0时数据无意义:
-
1、血浆葡萄糖浓度
-
2、舒张压
-
3、肱三头肌皮褶厚度
-
4、餐后血清胰岛素
-
5、体重指数
让我们确认一下原始数据,下述代码打印了数据集的前二十条数据。

代码运行后,可以很清楚得看到第2、3、4、5列的0值。
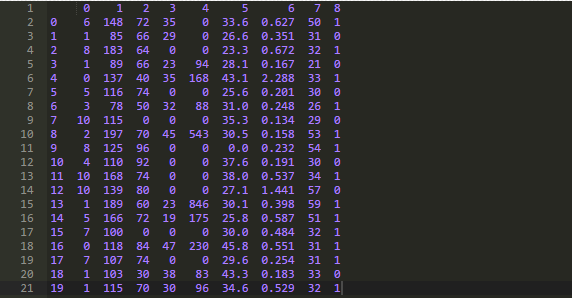
输出结果容易看出上述几列中每一列缺失值的个数。我们可以把DataFrame中感兴趣的包含0值的那部分子集标记为True,然后计算出对应列中值为True的数量。

上述代码的运行结果如下:




