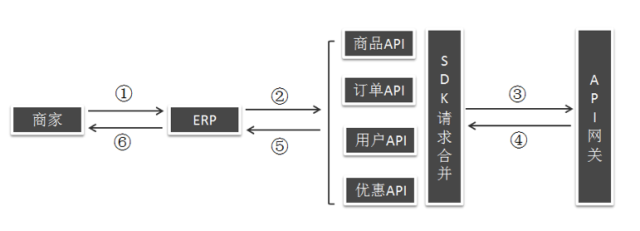
正文
API网关提供批量API调用模式缓解ISV在调用RT过高和网络消耗上的痛点。ISV发起的批量请求会在TOP SDK进行合并,并发送到指定的网关;网关接收到请求后在单线程模式下进行公共逻辑计算,计算通过后将调用安装API维度拆分,并分别发起异步化远程调用,至此该线程结束并被回收;每个子API的远程请求结果返回时会拿到一个线程进行私有逻辑处理,处理结束时会将处理结果缓存并将完成计数器加一;最后完成处理的线程,会将结果进行排序合并和输出。
TOP API网关暴露在互联网环境,日调用量达几百亿。特别是在双11场景中,API调用基数大、调用者众多以及各个API的服务能力不一致,为了保证各个API能够稳定提供服务,不会被暴涨的请求流量击垮,那么多维度流量控制是API网关的一个重要环节。API网关提供一系列通用的流量控制规则,如API每秒流控、API单日调用量控制、APPKEY单日调用量控制等。
在双11场景中,也会有一些特殊的流量控制场景,比如单个API提供的能力有限,例如只能提供20万QPS的能力而实际的调用需求可能会有40万QPS。在这种场景下怎么去做好流量分配,保证核心业务调用不被限流。
TOP API网关提供了流量分组的策略,比如我们可以把20万QPS的能力分为3个组别,并可以动态去配置和调整每个组别的比例,如:分组1占比50%、如分组2占比40%、分组3占比10%。我们将核心重要的调用放到分组1,将实时性要求高的调用放到分组2,将一些实时性要求不高的调用放到分组3。通过该模式我们能够让一些核心或者实时性要求高的调用能够较高概率通过流量限制获取到相应的数据。同时TOP API网关是一个插件化的网关,我们可以编写流控插件并动态部署到网关,在流控插件中我们可以获取到调用上下文信息,通过Groovy脚本或简单表达式编写自定义流控规则,以满足双11场景中丰富的流控场景。
使用集群流控还是单机流控?单机流控的优势是系统开销较小,但是存在如下短板:
-
集群单机流量分配不均。
-
单日流控计数器在某台服务器挂掉或者重启时比较难处理。
-
API QPS限制小于网关集群机器数量时,单机流控无法配置。
基于这些问题,API网关最开始统一使用集群流控方案,但在双11前压测中发现如下一些问题:
-
单KEY热点问题,当单KEY QPS超过几十万时,单台缓存服务器RT明显增加。
-
缓存集群QPS达到数百万时,服务器投入较高。
针对第一个问题的解法是,将缓存KEY进行分片可将请求离散多台缓存服务器。针对第二个问题,API网关采取了单机+集群流控相结合的解决方案,对于高QPS API流控采取单机流控方案,服务端使用Google ConcurrentLinkedHashMap缓存计数器,在并发安全的前提下保持了较高的性能,同时能做到LRU策略淘汰过期数据。
有了API网关,服务商可以很方便获取淘系数据,但是如何实时获取数据呢?轮询 !数据的实时性依赖于应用轮询间隔时间,这种模式,API调用效率低且浪费机器资源。基于这样的场景,开放平台推出了消息服务技术,提供一个实时的、可靠的、异步双向数据交换通道,大大提高API调用效率。目前,整个系统日均处理百亿级消息,可支撑百万级瞬时流量,如丝般顺滑。
消息系统从部署上分为三个子系统,路由系统、存储系统以及推送系统。消息数据先存储再推送,保证每条消息至少推送一次。写入与推送分离,发送方不同步等待接收方应答,客户端的任何异常不会影响发送方系统的稳定性。系统模块交互如图所示。
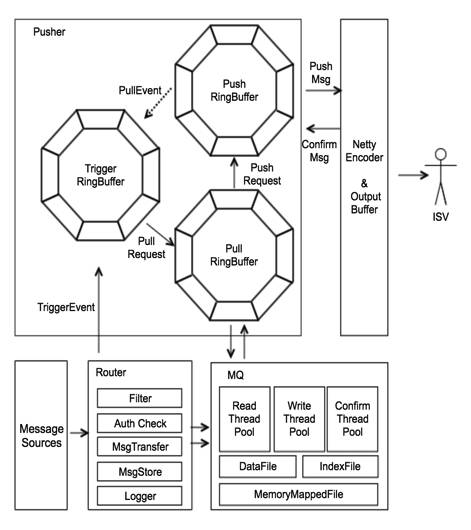
路由系统,各个处理模块管道化,扩展性强。系统监听主站的交易、商品、物流等变更事件,针对不同业务进行消息过滤、鉴权、转换、存储、日志打点等。系统运行过程记录各个消息的处理状况,通过日志采集器输出给JStorm分析集群处理并记录消息轨迹,做到每条消息有迹可循。





