正文
从你产生问题的环境,背景,场景中增加缩小检索范围的关键字信息;
从搜索到的网页中挖掘更加有意义的描述类似问题的关键字信息。
同时对于搜索而言,特别是技术问题的搜索,有官方知识库的要优先搜索官方的知识库:比如对于Oracle产品相关的技术问题,我们也会先搜索Oracle官方的Support网站,同时搜索类似StackOverFlow网站,这些网站往往有更加全部的技术问题解决文章。
搜索技术文章,那么国外的技术网站相对来说更加全面,而对于百度这块相对弱,很多国外技术网站内容甚至都搜索不到,这时候可以尝试Google或Bing搜索。
在前期我们实施Oracle SOA项目的时候,遇到了将服务封装和注册接入到OSB后,客户端消费和调用服务出现消息报文内容被截断的问题。
由于该问题出现概率不高,并且消费端系统本身有重试机制,也暂时不影响到具体的OSB服务运行和使用。虽然到现在为止,造成该问题的原因究竟是客户端服务器配置,负载均衡,网络,报文本身,OSB套件本身的Bug缺陷等哪方面还没有最终确认,但是整个问题排查和分析过程还是有意义的。
在问题排查和分析过程中,对于各类超时时间的含义,OSB的一些关键配置,报文解析,Http Post报文发送长短连接,Tomcat的一些配置都进行了了解,同时通过该问题的分析,也发现了在技术问题分析过程中的一些问题,供后面在分析问题中借鉴和参考。
客户端发送报文到服务器端接收报文,当前现象是客户端Log日志报文是完整的,而OSB上Log的日志报文不完整。
那么究竟是客户端,服务端,还是网络传输过程中出现的问题?
这个问题边界的确定相当重要。
实际上在几天的问题分析和排查中对于问题边界一直没有最终确认,导致问题也一直没有很肯定的得到定位究竟在哪里,也导致最终问题没有得到明确的解决和排查。
比如上面说的消息报文不完整这个问题,要确定边界实际上常规思路也就两种,
-
一种就是修改程序代码进行更加详细的日志记录;
-
另外一种就是增加Trace监控。
比如该问题可以在客户端进行Http或TCP Trace,同时在服务器端也进行Http TCP Trace,通过两边的Trace信息才能够最终确定问题的边界在哪里。
但是在生产环境很难这样去做,
故障的复现是我们分析和定位问题的一个基础,问题如果随机偶然发生往往是最难解决的。当你面对问题的时候,你需要定位,那就需要问题能够复现才方便不断地去Debug或Trace。

在该问题的解决过程中,由于该异常是偶然出现,不定时而且是没有规律出现,所以也给我们排查问题造成了很大的麻烦。
虽然在问题排查过程中,我将出现问题的异常日志,和前后正常的实例都进行了导出分析,对出现问题的服务器Server节点、调用方、调用时间段都进行了分析,但是没有明显的发现出现问题的规律究竟在哪里。
同时该问题具有很高的随机性,往往是第一次调用不成功,但是同样的报文在第二次或第三次就调用成功,同时每次对于报文的截断长度都不相同。这导致很难分析具体什么场景下调用不成功。
即由于问题不能在特定的输入条件下重现,导致我们很难对问题进行进一步的分析和定位,也导致我们很难去进行特定的跟踪和边界确定。同时也很难在测试环境对该问题进行进一步的分析,和各种参数条件修改后的测试和验证。
即
由于问题不能在特定的输入条件下重现,导致我们很难对问题进行进一步的分析和定位,也导致我们很难去进行特定的跟踪和边界确定。同时也很难在测试环境对该问题进行进一步的分析,和各种参数条件修改后的测试和验证。
以上都导致问题很难快速定位和分析,只能够大范围的场景+异常的关键字搜索,然后搜索到相关的可能解决方案后,一个个的去尝试看是否能够解决。
但是,这种方式带来巨大的问题,即:
由于测试环境问题不复现,我们无法在测试环境做这个事情。那么搜索到的解决方案验证只能够在生产环境做,但是生产环境根据规定是绝对不允许随意去修改配置和调整参数的。
这也正是我们看到很多大型IT项目上线,往往会预留3个月左右的试运行期间的原因,在试运行期间生产环境的日常运维和配置修改不会严格受控管理,也方便及时分析和解决问题。
由于项目采用的Oracle SOA Suite 12c套件产品,当前在国内并没有大范围的应用,所以如果用百度搜索基本搜索不到有用信息,改用Google或Bing很多信息也无法搜索到。
因此在该问题的排查过程中,我们基本都在Oracle Support网站进行了所有相关知识点的排查,同时选择各类关键字进行搜索引擎的搜索,其中包括了:
但是并没有搜索到完全一致的场景。
对于一个最相似的关于Failed to parse XML document的场景,我们进行了相关的调整,即将KeepAlive设置为False,同时对Post Timeout设置为120秒,但是仍然出现在120秒超时时间到达后任何没有Post到完整的请求而导致超时的问题。
由于无法搜索到完全类似的场景,也导致我们很难根据网上给出的方法进行进一步测试和验证。并且Oracle顾问对于该问题也只能给出进行Tcp Trace的无用建议。
7、关键基础技术知识缺乏,导致问题分析和提出假设不合理
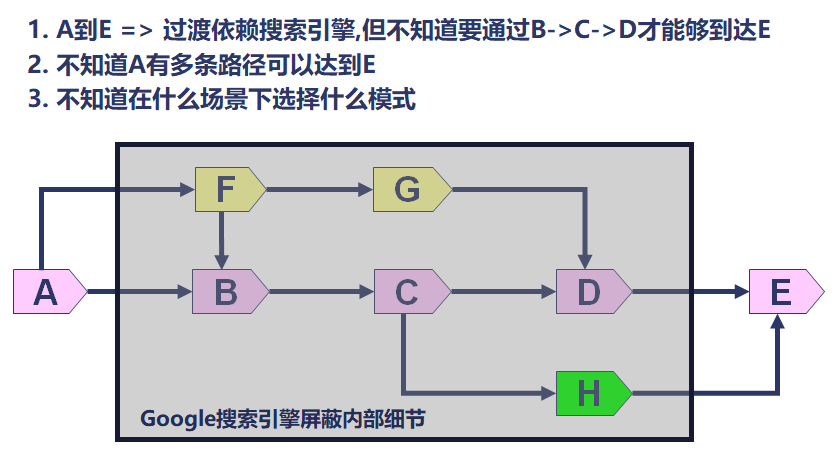
在原来问题的分析和解决中,由于搜索引擎往往会给出完全类似的场景,我们只需要根据搜索引擎给出的排查思路对问题进行排查即可。
因此解决起来效率很高,对于具体底层原理性的内容我们并不需要掌握和了解,只需要能够选择合适的关键字,通过搜索引擎搜索到最合适的内容然后进行排查即可。
但是这次问题,特殊点就在于搜索引擎根本无法给出完全类似的文章。这就导致需要基于问题提出各种合理的假设,并对假设进行逐一验证。
那么如何提出合理的假设?
这里就涉及到对于TCP底层协议,各个超时值的含义和原理,Tomcat Server的参数配置,OSB代理服务的解析过程,Weblogic的关键参数配置和含义,负载均衡策略,乃至Docker容器和IP映射等很多内容都有技术积累才可能提出最合理的思路。
比如在排查过程中,我会想到是否需要将Tomcat 的MaxPostSize值调大的假设,但是该异常是Tomcat向Weblogic Server进行Post请求发送数据,对于Tomcat 的MaxPostSize根本不会影响到这个Post请求,而只有Weblogic上的Post Size才会有影响。这个假设本身就不合理。而要快速的判断这些假设不合理,你就必须提前有这些关键的基础技术知识和背景积累。





