正文
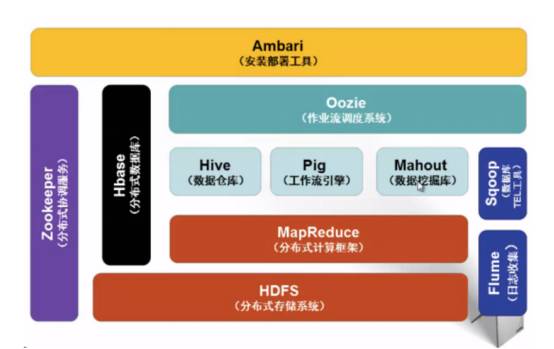
图2 Hadoop生态系统
低成本、高可靠、高扩展、高有效、高容错等特性让Hadoop成为最流行的大数据分析系统,然而其赖以生存的HDFS 和MapReduce 组件却让其一度陷入困境——批处理的工作方式让其只适用于离线数据处理,在要求实时性的场景下毫无用武之地。因此,各种基于Hadoop的工具应运而生。为了减少管理成本,提升资源的利用率,有当下众多的资源统一管理调度系统,例如Twitter 的Apache Mesos、Apache 的YARN、Google 的Borg、腾讯搜搜的Torca、Facebook Corona(开源)等。Apache Mesos是Apache孵化器中的一个开源项目,使用ZooKeeper实现容错复制,使用Linux Containers 来隔离任务,支持多种资源计划分配(内存和CPU)。提供高效、跨分布式应用程序和框架的资源隔离和共享,支持Hadoop、MPI、Hypertable、Spark 等。YARN 又被称为MapReduce 2.0,借鉴Mesos,YARN 提出了资源隔离解决方案Container,提供Java 虚拟机内存的隔离。对比MapReduce 1.0,开发人员使用ResourceManager、ApplicationMaster与NodeManager代替了原框架中核心的JobTracker 和TaskTracker。在YARN平台上可以运行多个计算框架,如MR、Tez、Storm、Spark等。
基于业务对实时的需求,有支持在线处理的Storm、Cloudar Impala、支持迭代计算的Spark 及流处理框架S4。Storm是一个分布式的、容错的实时计算系统,由BackType开发,后被Twitter捕获。Storm属于流处理平台,多用于实时计算并更新数据库。Storm也可被用于“连续计算”(Continuous Computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。Cloudera Impala是由Cloudera开发,一个开源的Massively Parallel Processing(MPP)查询引擎。与Hive 相同的元数据、SQL语法、ODBC 驱动程序和用户接口(HueBeeswax),可以直接在HDFS 或HBase 上提供快速、交互式SQL 查询。Impala是在Dremel的启发下开发的,不再使用缓慢的Hive+MapReduce 批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator 和Query Exec Engine这3部分组成),可以直接从HDFS 或者HBase 中用SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
Hadoop社区正努力扩展现有的计算模式框架和平台,以便解决现有版本在计算性能、计算模式、系统构架和处理能力上的诸多不足,这正是Hadoop2.0 版本“ YARN”的努力目标。各种计算模式还可以与内存计算模式混合,实现高实时性的大数据查询和计算分析。混合计算模式之集大成者当属UC Berkeley AMP Lab 开发的Spark生态系统,如图3所示。Spark 是开源的类Hadoop MapReduce的通用的数据分析集群计算框架,用于构建大规模、低延时的数据分析应用,建立于HDFS之上。Spark提供强大的内存计算引擎,几乎涵盖了所有典型的大数据计算模式,包括迭代计算、批处理计算、内存计算、流式计算(Spark Streaming)、数据查询分析计算(Shark)以及图计算(GraphX)。Spark 使用Scala 作为应用框架,采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。与Hadoop 不同的是,Spark 和Scala 紧密集成,Scala 像管理本地collective 对象那样管理分布式数据集。Spark支持分布式数据集上的迭代式任务,实际上可以在Hadoop文件系统上与Hadoop一起运行(通过YARN、Mesos等实现)。另外,基于性能、兼容性、数据类型的研究,还有Shark、Phoenix、Apache Accumulo、Apache Drill、Apache Giraph、Apache Hama、Apache Tez、Apache Ambari 等其他开源解决方案。预计未来相当长一段时间内,主流的Hadoop平台改进后将与各种新的计算模式和系统共存,并相互融合,形成新一代的大数据处理系统和平台。
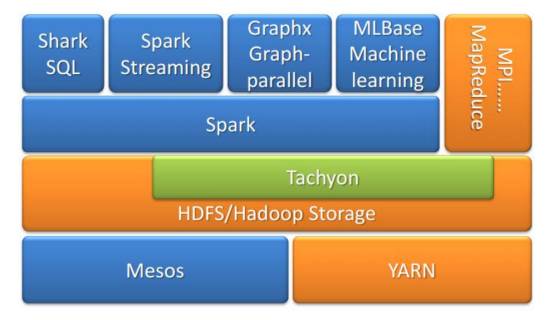
图
3 Spark
生态系统
在大数据的生命周期中,数据采集处于第一个环节。根据MapReduce产生数据的应用系统分类,大数据的采集主要有4种来源:管理信息系统、Web信息系统、物理信息系统、科学实验系统。对于不同的数据集,可能存在不同的结构和模式,如文件、XML 树、关系表等,表现为数据的异构性。对多个异构的数据集,需要做进一步集成处理或整合处理,将来自不同数据集的数据收集、整理、清洗、转换后,生成到一个新的数据集,为后续查询和分析处理提供统一的数据视图。针对管理信息系统中异构数据库集成技术、Web 信息系统中的实体识别技术和DeepWeb集成技术、传感器网络数据融合技术已经有很多研究工作,取得了较大的进展,已经推出了多种数据清洗和质量控制工具,例如,美国SAS公司的Data Flux、美国IBM 公司的Data Stage、美国Informatica 公司的Informatica Power Center。









