正文
User-agent: *Disallow: /Disallow: /poi/detail.phpSitemap: http://www.mafengwo.cn/sitemapIndex.xml
HTTP请求和响应处理
其实爬取网页就是通过HTTP协议访问网页,不过通过浏览器反问往往是人的行为,把这种行为变成使用程序来访问。
urllib包
urllib是标准库,它一个工具包模块,包含下面模块来处理url:
* urllib.request 用于打开和读写url
* urllib.error 包含了由urllib.request引起的异常
* urllib.parse 用于解析url
* urllib.robotparser 分析robots.txt文件
Python2中提供了urllib和urllib2。
urllib提供较为底层的接口,urllib2对urllib进行了进一步封装。
Python3中将urllib合并到了urllib2中,并更名为标准库urllib包。
urllib.request模块
定义了在基本和摘要式身份验证、重定向、cookies等应用中打开Url(主要是HTTP)的函数和类。
1.urlopen(url,data=None)
url是链接地址字符串,或请求类的实例
data提交的数据,如果data为Non发起的GET请求,否则发起POST请求。
见urllib.request.Request#get_method返回http.client.HTTPResponse类的相遇对象,这是一个类文件对象。
from urllib.request import urlopenresponses = urlopen("http://www.bing.com") print(responses.closed)with responses: print(1, type(responses)) print(2,responses.status,responses.reason) print(3,responses.geturl()) print(4,responses.info()) print(5,responses.read()[:50])
print(responses.closed)
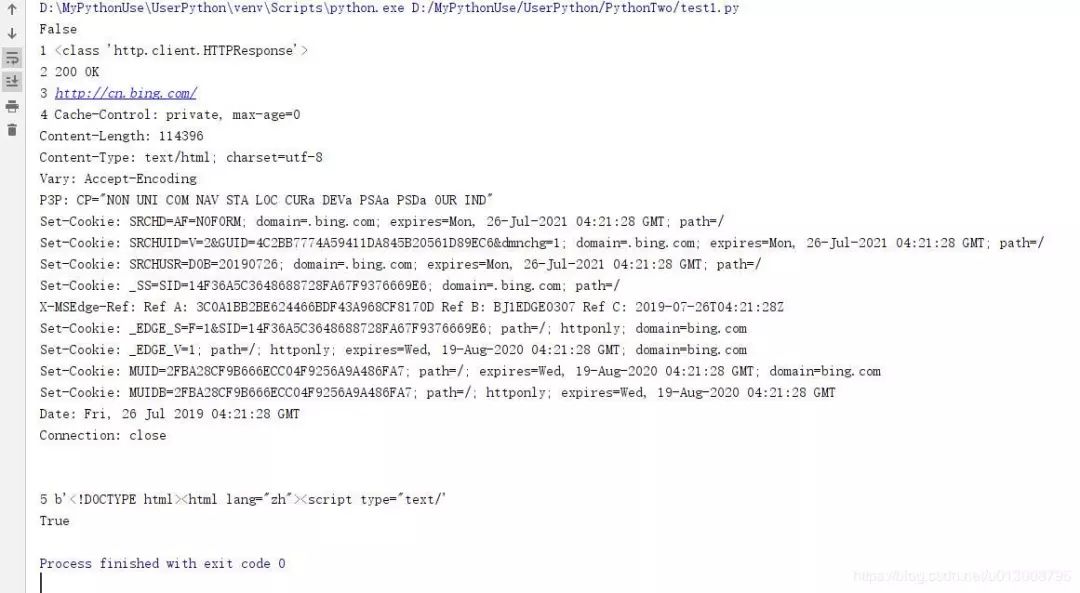
1. 上例,通过urllib.request.urlopen方法,发起一个HTTP的GET请求,WEB服务器返回了网页内容。
响应的数据被封装到类文件对象中,可以通过read方法、readline方法、readlines方法获取数据,status和reason属性表示返回的状态码,info方法返回头信息,等等。
上例代码非常精简,即可以获得网站的响应数据。
但目前urlopen方法通过url字符串和data发起HTTP的请求。
如果想修改HTTP头,例如useragent,就的借助其他方式。
原码中构造的useragen如下:
class OpenerDirector: def __init__(self): client_version = "Python-urllib/%s" % __version__ self.addheaders = [('User-agent', client_version)]```* 当前显示为Python-urlib/3.7* 有些网站是反爬虫的,所以要把爬虫伪装成浏览器。顺便打开一个浏览器,复制李立群的UA值,用来伪装。
Request(url,data=None,headers={})
初始化方法,构造一个请求对象。
可添加一个header的字典。
data参数决定是GET还是POST请求。
obj.add_header(key,val)为header增加一个键值对。
from urllib.request import Request,urlopenimport randomurl = "http://www.bing.com/"
ua_list = [ "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36", "Mozilla/5.0 (Windows; U; Windows NT 6.1; zh-CN) AppleWebKit/537.36 (KHTML, like Gecko) Version/5.0.1 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)" ]
ua = random.choice(ua_list)request = Request(url)request.add_header("User-Agent",ua)print(type(request))
response = urlopen(request,timeout=20) print(type(response))
with response: print(1





