正文
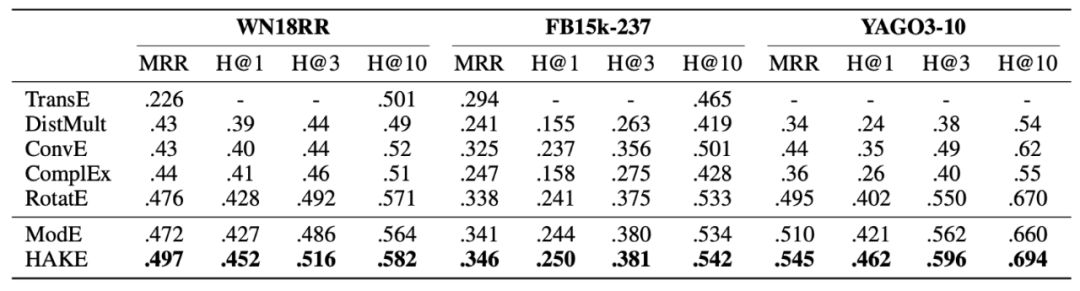
HAKE 与基准模型 ModE 在 WN18RR、FB15k-237 与 YAGO3-10 上的实验对比结果如下图所示。
基于上文中关于树型结构的论述,我们对于实体的嵌入向量的表现有如下的期望:
-
位于更高语义层级的实体更加靠近树的根节点,故模长更小
-
位于更低语义层级的实体更加靠近树的叶节点,故模长更大
由于关系连接着头尾实体,我们对于关系的嵌入向量的表现有如下期望:
-
如果头实体的语义层级更高,而尾实体的语义层级更低,那么我们期望

-
如果头实体的语义层级更低,而尾实体的语义层级更高,那么我们期望

-
如果头尾实体位于相同的语义层级,那么我们期望

为了验证上述猜想,我们进行了如下实验分析。首先,我们从三个数据集中选取了一些代表性的关系。接着,对于这些关系在 ModE 与 HAKE 模型中的模长部分向量,我们绘制了每一维度的取值的分布直方图,如下图所示:

对于图中的六个关系,我们将其分为三组。图 (a) (b) 中的关系所连接的头实体的语义层级低于尾实体;图 © (d) 中的关系所连接的头尾实体的语义层级相同;图 (e) (f) 中的关系所连接的头实体的语义层级高于尾实体。
从图中可以分析得出,当头实体语义层级更高时,关系的模长总体大于1;当尾实体语义层级更高时,关系的模长总体小于1;当头尾实体的语义层级相同时,关系的模长总体接近1。这样的实验结果与上述猜想完全一致。我们还发现,与 ModE 相比,HAKE 的模长嵌入向量的取值分布更为集中,方差更小,这表明 HAKE 能够更加清晰准确地对语义层级进行建模。
在上述图 © (d) 中,关系的模长都接近于 1,因此利用模长部分难以对该关系连接的实体进行区分。对于这种情况,我们求助于 HAKE 的角度部分。我们从 WN18RR 和 FB15k-237 中各选取了一种关系,并绘制了它们角度部分每一维度的取值的的分布直方图,如下图所示。
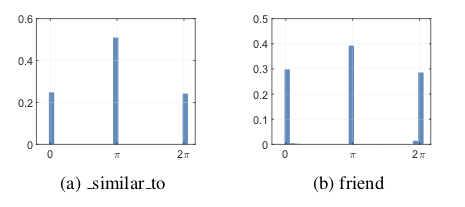
从图中可以看到,它们每一维度的取值主要集中于三个值附近:0、π 与 2π,并且取值接近 π 的维度占比为 40%-50%。也就是说,这些头尾实体中接近一半的维度取值都相差 π。因此位于同一语义层级的实体可以被角度部分区分。
我们接下来对实体进行可视化分析。在这部分的实验中,为了更加清晰的展示出通过 HAKE 建模得到的分层效果,我们将 HAKE 与 RotatE 进行对比,将两种模型得到的实体向量的不同维度都绘制成同一个二维平面上的点。我们从 WN18RR 中选取了三个不同类型的三元组,得到如下的散点图。

图 (a) 中的三元组中,头实体位于更低的语义层级;图 (b) 中,头尾实体的语义层级相同;图 © 中,头实体位于更高的语义层级。需要注意的是,为了更加直观地显示出分层效果,我们绘制散点图时对于每一个点的模长使用了对数缩放操作。因此,图中更大的半径实际上表示更小的模长。
从图中可以看到,在头尾实体分属不同语义层级的场景下(图 (a) 与 (c)),HAKE 的散点图表现出了更加明显的分层效果,而在 RotatE 的散点图中,头尾实体则难以依靠半径进行区分。对于头尾实体属于相同语义层级的场景下,表示头尾实体的点应该具有大致相同的半径。在此场景下,HAKE 依然表现的更好,因为 HAKE 中的实体模长分布的方差更小。
本文介绍了一个可建模语义分层的知识图谱补全模型:HAKE。该模型使用极坐标系对语义分层进行建模。其中,模长部分用于建模分属不同语义层级的实体;角度部分用于建模属于相同语义层级的实体。实验结果表明 HAKE 的性能优于现有的性能最好的方法。进一步分析结果显示,训练得到的模型中模长与角度的表现与预期相符,能够很好地对语义层级进行建模。
一文全览,知识图谱@AAAI 2020





