正文
索引更新:索引有全量更新、增量更新两种,增量更新就是局部更新,如果数据量在百万量级以上,数据变化不多的场景下,尽量用增量更新。另外,索引的 Update 实际是先 Delete 指定记录,然后再把指定记录对应的新值 Add 到索引。
鉴于 Lucene 强大的特性和稳定性,有很多种基于 Lucene 封装的企业级搜索平台。其中最流行有两个:Apache Solr 和 Elastic search。
-
Apache Solr:它本身是 Apache Lucene 项目下的开源企业搜索平台,算是 Lucene 的直系。美团、阿里搜索服务是基于 Solr 来搭建的。
-
Elastic Search:简称 ES,由 Elastic 公司开发。Elastic 成立于 2012 年,总部在阿姆斯特丹,不久前 Google 宣布与 Elastic 达成战略合作协议,为谷歌云提供新的搜索以及相关分析服务。 最近几年,ES 变得越来越普及,StackOverflow、Github、百度等都在使用。
企业搜索都有些什么不同,解决了什么需求呢?综合 Solr 和 ES,我觉得主要有两点:
Solr 有 SolrCloud 来管理集群,它是基于 ZooKeeper 来控制节点的负载均衡:
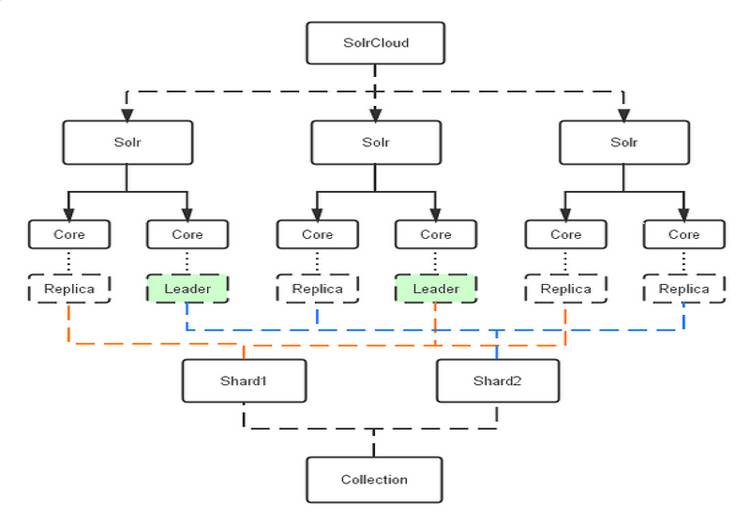
Solr 控制节点的管理后台:
ES 集群管理是透明化,它基于 Cluster+Node+Shards(分片实现主从复制) 机制,自己实现节点管理。它的主从配置 Demo:
Master 的配置 (elasticsearch.yml):
cluster.name: esapp
node.name: esnode0
node.master: true
node.data: true
network.host: 0.0.0.0
Slave 的配置:
cluster.name: esapp
node.name: esnode2
node.master: false
node.data: true
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["esnode0"]
其中,network.host: 0.0.0.0 代表了没有绑定具体的 ip,这样其他机器可以通过 9200 这个默认端口通过 http 方式访问查看服务。而 slave 中的 discovery.zen.ping.unicast.hosts 指定了 master 的地址。
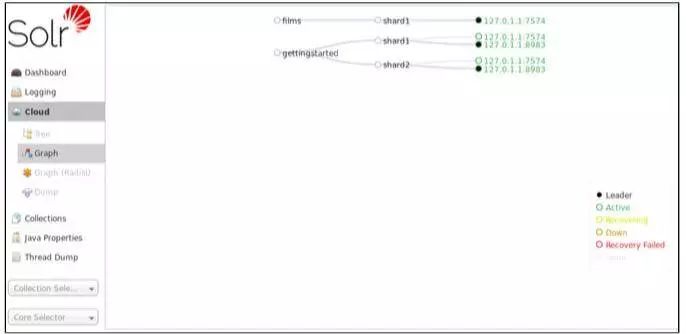
Solr、ES 都提供了基于 HTTP 的搜索管理平台,Solr 自带管理后台, ES 有独立数据视图产品,如下图:

此外,Solr 和 ES 都提供方便的 REST API,以供各种客户端调用搜索服务,比如 Solr API:

因为 ES 在 12 年后才出现,早年 Solr 在企业级搜索市场算是一枝独秀。我在阿里的时候,早期 Taobao SKU 搜索服务还是基于 Solr 实现,那时的 Solr 对百万量级 SKU 做全量更新就已经是毫秒级别。
在美团,我也采用 Solr 集群搭建团购 SKU 搜索系统。大体的架构实现:

美团团购搜索主要有:商品列表按价格、购买量、人气等各种排序;移动端有大量 LBS 服务,它比较耗性能;一些热词的关键字搜索。最早,美团采用 MongoDB 提供的搜索,当时考虑:
-
MongoDB 存储是 JSON 数据,查询也方便。
-
它是基于平衡二叉树的内存索引,查询比较快,当时一台实例能撑到 3000 的 QPS(里面有大概 30% 是 LBS 查询)。不过 MongoDB 现在已经采用了新的搜索引擎叫 WiredTiger,一种文档级锁的存储引擎取代过去内存存储引擎 MMAP。
-
友好支持基于 GEO Hash 算法的 LBS 搜索。这点满足我们的移动端的 LBS 服务,它还可以一个 SKU 有多个坐标(分店)的查询。而 Solr 当时只能支持一个 SKU 一个坐标关联,遇到多个分店要拆解成多个 Docs 记录放在索引库中。








