正文
3)Deep Reinforcement Learning-based Image Captioning with Embedding Reward
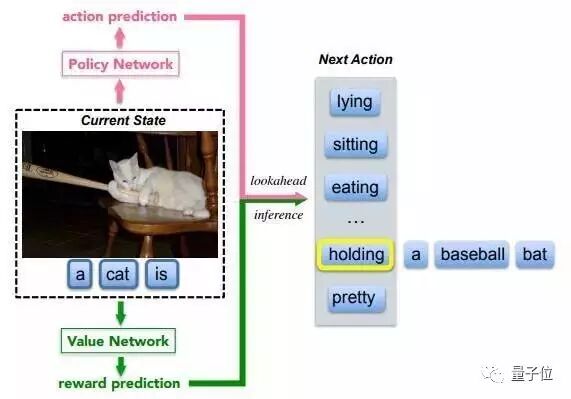
由Snapchat与谷歌合作的这篇论文也使用强化学习训练图像描述生成网络,并采用Actor-critic框架。此论文通过一个策略网络(Policy Network)和价值网络(Value Network)相互协作产生相应图像描述语句。策略网络评估当前状态产生下一个单词分布,价值网络评价在当前状态下全局可能的扩展结果。这篇论文没有用CIDEr或BLEU指标作为目标函数,而是用新的视觉语义嵌入定义的Reward,该奖励由另一个基于神经网络的模型完成,能衡量图像和已产生文本间的相似度。在MS COCO数据集上取得了不错效果。
4)Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning
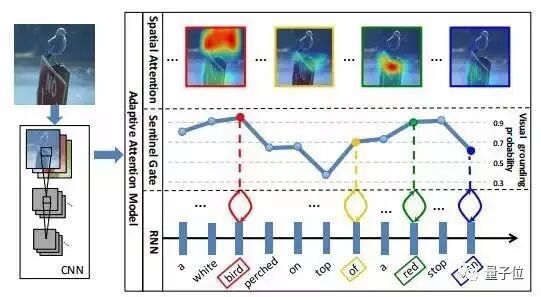
弗吉尼亚理工大学和乔治亚理工大学合作的这篇论文主要讨论自适应的注意力机制在图像描述生成中的应用。在产生描述语句的过程中,对某些特定单词,如the或of等,不需要参考图像信息;对一些词组中的单词,用语言模型就能很好产生相应单词。因此该文提出了带有视觉哨卡(Visual Sentinel)的自适应注意力模型,在产生每一个单词的时,由注意力模型决定是注意图像数据还是视觉哨卡。
在图像描述生成方面,本届CVPR还有很多其他方面的研究工作。包括在《Incorporating Copying Mechanism in Image Captioning for Learning Novel Objects》中,微软亚洲研究院将复制功能(Copying Mechanism)引入图像描述生成学习新物体,《Attend to You: Personalized Image Captioning With Context Sequence Memory Networks》一文用记忆网络(Memory Network)来定制个性化的图像描述生成。
近年来,由于视频数据大大丰富,也有一系列的工作讨论视频描述生成,包括复旦大学与英特尔合作的《Weakly Supervised Dense Video Captioning》,和杜克大学与微软合作的《Semantic Compositional Networks for Visual Captioning》等。
三、3D计算机视觉
3D Computer Vision
近年来,3D计算机视觉快速发展,被广泛应用在无人驾驶、AR或VR等领域。在本届CVPR,该研究方向亦受到广泛关注,并体现出两大特点:一方面其在传统多视图几何如三维重建等问题上有所突破,另一方面它也和现今研究热点,如深度强化学习等领域紧密结合。我们将对以下两个方向做进一步介绍:
1) Exploiting Symmetry and/or Manhattan Properties for 3D Object Structure Estimation From Single and Multiple Images
这篇论文为腾讯AI Lab、约翰霍普金斯大学及加州大学洛杉矶分校合作发表,作者主要讨论从二维图像中进行人造物体(如汽车、飞机等)的三维结构重建问题。事实上,绝大多数人造物体都有对称性以及曼哈顿结构,后者表示我们可以很容易在欲重建的人造物体上找到三个两两垂直的轴。如在汽车上,这三个轴可为两个前轮、两个左轮及门框边缘。作者首先讨论了基于单张图片的物体三维结构重建,并证明了仅用曼哈顿结构信息即可恢复图像的摄像机矩阵;然后结合对称性约束,可唯一地重建物体的三维结构,部分结果如下图所示。

然而,在单张图像重建中,遮挡和噪声等因素会对重建结果造成很大影响。所以论文后半部分转到了多张图像基于运动恢复结构(Structure from Motion, 简称SfM)及对称信息的物体三维重建中。事实上,SfM算法涉及到对二维特征点进行矩阵分解,而添加对称性约束后,我们并不能直接对两个对称的二维特征点矩阵直接进行矩阵分解,因为这样不能保证矩阵分解得到同样的摄像机矩阵以及对称的三维特征点坐标。在文章中,作者通过进一步利用对称性信息进行坐标轴旋转解决了这个问题。实验证明,该方法的物体三维结构重建及摄像机角度估计均超出了之前的最好结果。
2) PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning
本文由德国德累斯顿工业大学(TU Dresden)与微软联合发表,主要通过强化学习估计物体6D姿态。传统姿态估计系统首先对物体姿态生成一个姿态假设池(a Pool of Pose Hypotheses),接着通过一个预先训练好的卷积神经网络计算假设池中所有姿态假设得分,然后选出假设池中的一个姿态假设子集,作为新假设池进行Refine。以上过程迭代,最后返回得分最高的假设姿态作为姿态估计的结果。
但传统方法对姿态假设池Refinement的步骤非常耗时,如何选择一个较好姿态假设子集作为姿态假设池就变得尤为重要。本文作者提出了一同基于策略梯度的强化学习算法来解决这个问题。该强化学习算法通过一个不可微的奖励函数来训练一个Agent,使其选取较好的姿态假设,而不是对姿态假设池中的所有姿态进行Refine。
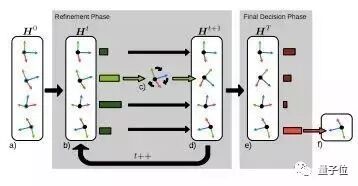
强化学习的步骤如上图所示。首先给强化学习Agent输入一个较大初始姿态假设池,然后该Agent通过对其策略采样,选择一个新的强化学习池,并对其进行Refine。上述过程达到一定次数后,最后求得的姿态假设池中得分最高的姿态假设即为所求得姿态。实验表明该方法在大大提高运行速度时,还得到超出此前最佳算法的估计结果。
四、计算机视觉与机器学习
Computer Vision & Machine Learning
计算机视觉与机器学习历来联系紧密,随着深度学习近年来在视觉领域取得的空前成功,机器学习更是受到更广泛的重视。作为机器学习一个分支,深度学习依然是计算机视觉领域绝对主流。但与前几年不同的是,纯粹用深度学习模型「单打独斗」解决某个视觉问题似乎不再流行。










