正文
如果没有合适的题目做测谎题,也可以在编制问卷的时候设置测谎题,两种设计思路:
同一个题目前后问两遍,检查答案是否一致,如:请从下列选项中选出你最常用的地图APP。注意避免使用有两个答案的问题,比如问用户爱车的品牌就不合适,因为用户前后填答不一致,不一定都是不认真填答,也可能是因为用户本身有两辆车。
设置一个有明显错误答案的问题,检查是否选择了错误的答案,如:你最常用的地图APP是哪个:混淆选项可以用 :京东。不过我们只是想检验用户的认真程度,而非考验用户的记忆力,所以测谎题要简单明确,只要认真看题就不会错。比如问用户最常用的地图APP是哪个,混淆选项用“微信”就不合适,因为用户不认真想的话,很容易把微信自带的地图当成地图APP。
如果技术支持,也可以通过后台数据和用户问卷中的数据做匹配,常用的是性别、年龄、常居地之类的数据,也可以问一些明确的行为数据,比如是否用地图买过火车票。
需要注意的是:选择稳定的明确的数据来做校验题目,不要使用需要回忆的数据来校验,用户的记忆是模糊的有误差的,使用频率、使用年限,这些都不适合做校验,因为用户的记忆很可能与实际行为不完全相符。
问卷调研绝大部分是抽样调研,如果想通过样本的情况去推测整体的情况,除了要考虑最小样本量之外,还需要考虑样本的代表性。群体有很多属性,并不是要求样本的每个属性都和整体一致,而是关注那些对研究问题最有影响的属性,在该属性上样本和整体尽量保持一致。
假设:年龄对用户忠诚度的影响非常大,对出行方式没有影响,那么在研究忠诚度时就需要考虑到年龄因素,而在研究出行方式时,就无需考虑年龄因素了。
具体方法如下:
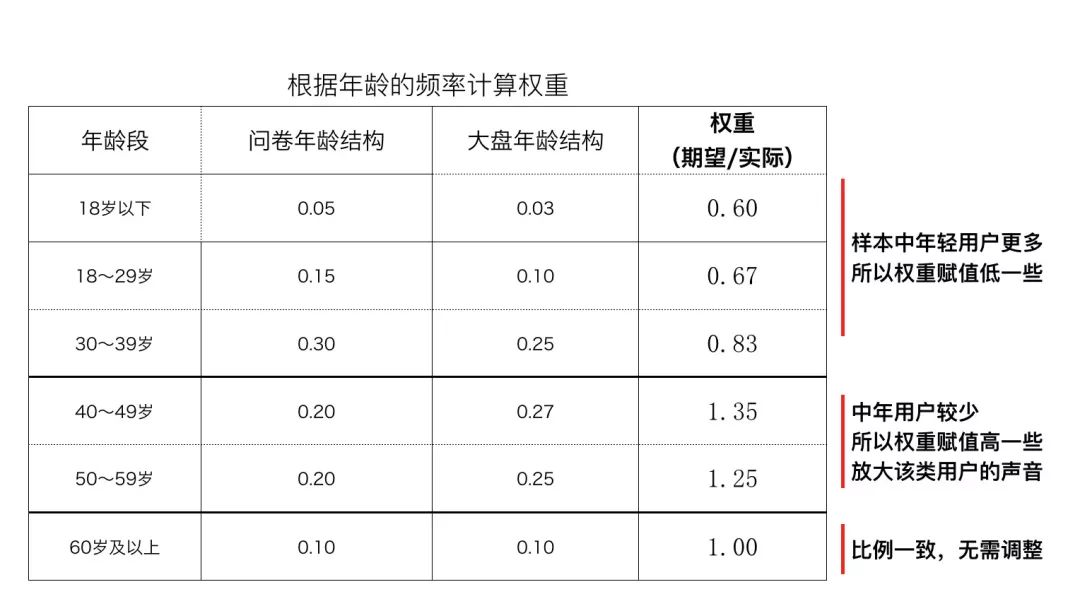
先根据整体和样本的年龄分布,计算出权重值,然后再使用spss的权重功能,给数据加权。加权后再统计忠诚度。
值得注意的是,不要为了省事儿,直接计算出样本各年龄段的值,然后给
各
年龄段的值赋个权重,求均值。这样的结果是不对的,必须要使用spss的加权功能。
如果有多个因素,挑选最重要的一个因素加权。如果非要考虑多个因素,那么需要了解多个因素交叉后的整体分布。比如既要考虑性别、又要考虑年龄,那么需要将性别和年龄交叉,知道整体男性的年龄分布、女性的年龄分布,再计算权重,成本太高了。





